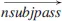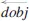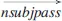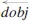![]()
Part 1
Understanding Semantics
![]()
Open information extraction
Duc-Thuan Vo* and Ebrahim Bagheri†
Open information extraction (Open IE) systems aim to obtain relation tuples with highly scalable extraction in portable across domain by identifying a variety of relation phrases and their arguments in arbitrary sentences. The first generation of Open IE learns linear chain models based on unlexicalized features such as Part-of-Speech (POS) or shallow tags to label the intermediate words between pair of potential arguments for identifying extractable relations. Open IE currently is developed in the second generation that is able to extract instances of the most frequently observed relation types such as Verb, Noun and Prep, Verb and Prep, and Infinitive with deep linguistic analysis. They expose simple yet principled ways in which verbs express relationships in linguistics such as verb phrase-based extraction or clause-based extraction. They obtain a significantly higher performance over previous systems in the first generation. In this paper, we describe an overview of two Open IE generations including strengths, weaknesses and application areas.
Keywords: Open information extraction; natural language processing; verb phrase-based extraction; clause-based extraction.
1.Information Extraction and Open Information Extraction
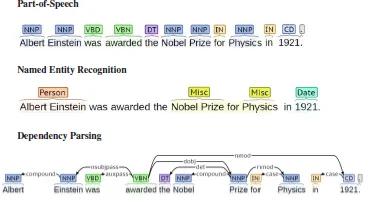
Information Extraction (IE) is growing as one of the active research areas in artificial intelligence for enabling computers to read and comprehend unstructured textual content.1 IE systems aim to distill semantic relations which present relevant segments of information on entities and relationships between them from large numbers of textual documents. The main objective of IE is to extract and represent information in a tuple of two entities and a relationship between them. For instance, given the sentence “Barack Obama is the President of the United States”, they venture to extract the relation tuple President of (Barack Obama, the United States) automatically. The identified relations can be used for enhancing machine reading by building knowledge bases in Resource Description Framework (RDF) or ontology forms. Most IE systems2–5 focus on extracting tuples from domain-specific corpora and rely on some form of pattern-matching technique. Therefore, the performance of these systems is heavily dependent on considerable domain specific knowledge. Several methods employ advanced pattern matching techniques in order to extract relation tuples from knowledge bases by learning patterns based on labeled training examples that serve as initial seeds.
Many of the current IE systems are limited in terms of scalability and portability across domains while in most corpora likes news, blog, email, encyclopedia, the extractors need to be able to extract relation tuples from across different domains. Therefore, there has been move towards next generation IE systems that can be highly scalable on large Web corpora. Etzioni et al.1 have introduced one of the pioneering Open IE systems called TextRunner.6 This system tackles an unbounded number of relations and eschews domain-specific training data, and scales linearly. This system does not presuppose a predefined set of relations and is targeted at all relations that can be extracted. Open IE is currently being developed in its second generation in systems such as ReVerb,7 OLLIE,7 and ClausIE,8 which extend from previous Open IE systems such as TextRunner,6 StatSnowBall,9 and WOE.10 Figure 1 summarizes the differences of traditional IE systems and the new IE systems which are called Open IE.1,11
2.First Open IE Generation
In the first generation, Open IE systems aimed at constructing a general model that could express a relation based on unlexicalized features such as POS or shallow tags, e.g., a description of a verb in its surrounding context or the presence of capitalization and punctuation. While traditional IE requires relations to be specified in their input, Open IE systems use their relation-independent model as self-training to learn relations and entities in the corpora. TextRunner is one of the first Open IE systems. It applied a Naive Bayes model with POS and Chunking features that trained tuples using examples heuristically generated from the Penn Tree-bank. Subsequent work showed that a linear-chain Conditional Random Field (CRF)1,6 or Markov Logic Network9 can be used for identifying extractable relations. Several Open IE systems have been proposed in the first generation, including TextRunner, WOE, and StatSnowBall that typically consist of the following three stages: (1) Intermediate levels of analysis and (2) Learning models and (3) Presentation, which we elaborate in the following:
Fig. 1. IE versus Open IE.
Intermediate levels of analysis
In this stage, Natural Language Processing (NLP) techniques such as named entity recognition (NER), POS and Phrase-chunking are used. The input sequence of words are taken as input and each word in the sequence is labeled with its part of speech, e.g., noun, verb, adjective by a POS tagger. A set of nonoverlapping phrases in the sentence is divided based on POS tags by a phrase chunked. Named entities in the sentence are located and categorized by NER. Some systems such as TextRunner, WOE used KNnext8 work directly with the output of the syntactic and dependency parsers as shown in Fig. 2. They define a method to identify useful proposition components of the parse trees. As a result, a parser will return a parsing tree including the POS of each word, the presence of phrases, grammatical structures and semantic roles for the input sentence. The structure and annotation will be essential for determining the relationship between entities for learning models of the next stage.
Fig. 2. POS, NER and DP analysis in the sentence “Albert Einstein was awarded the Nobel Prize for Physics in 1921”.
Learning models
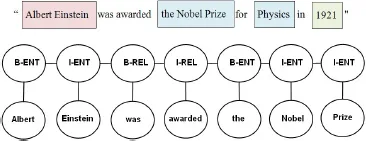
An Open IE would learn a general model that depicts how a relation could be expressed in a particular language. A linear-chain model such as CRF can then be applied to a sequence which is labeled with POS tags, word segments, semantic roles, named entities, and traditional forms of relation extraction from the first stage. The system will train a learning model given a set of input observations to maximize the conditional probability of a finite set of labels. TextRunner and WOEpos use CRFs to learn whether sequences of tokens are part of a relation. When identifying entities, the system determines a maximum number of words and their surrounding pair of entities which could be considered as possible evidence of a relation.
Figure 3 shows entity pairs “Albert Einstein” and “the Nobel Prize” with the relationship “was awarded” serving to anchor the entities. On the other hand, WOEparse learns relations generated from corePath, a form of shortest path where a relation could exist, by computing the normalized logarithmic frequency as the probability that a relation could be found. For instance, the shortest
path “Albert Einstein”
“was awarded”
“the Nobel Prize” presents the relationship between “Albert Einstein” and “the Nobel Prize” could be learned from the patterns “E1”
“V”
“E2” in the training data.
Fig. 3. A CRF is used to identify the relationship “was awarded” between “Albert Einstein” and “the Nobel Prize”.
Presentation
In this stage, Open IE systems provide a presentation of the extracted relation triples. The sentences of the input will be presented in the form of instances of a set of relations after being labeled by the learning models. TextRunner and WOE take sentences in a corpus and quickly extract textual triples that are present in each sentence. The form of relation triples contain three textual components where the first and third denote pairs of entity arguments and the second denotes the relationship between them as (Arg1, Rel, Arg2). Figure 4 shows the differences of presentations between traditional IE and Open IE.
Additionally, with large scale and heterogeneous corpora such as the Web, Open IE systems also need to address the disambiguation of entities, e.g., same entities may be referred to by a variety of names (Obama or Barack Obama or B. H. Obama) or the same string (Michael) may refer to different entities. Open IE systems try to compute the probability that two strings denote synonymous pairs of entities based on a highly scalable and unsupervised analysis of tuples. TextRunner applies the Resolver system12 while WOE uses the infoboxes from Wikipedia for classifying entities in the relation triples.
2.1.Advantages and disadvantages
Open IE systems need to be highly scalable and perform extractions on huge Web corpora such as news, blog, emails, and encyclopedias. TextRunner was tested on a collection of over 120 million Web pages and extracted over 500 million triples. This system also had a collaboration with Google on running over one billion public Web pages with noticeable precision and recall on this large-scale corpus.
First generation Open IE systems can suffer from problems such as extracting incoherent and uninformative relations. Incoherent extractions are circumstances when the system extracts relation phra...