Introduction
Remote sensing can be termed a mature discipline, in the sense that the underlying physical principles are well understood, and applications are beginning to appear in operational contexts spanning a diverse array of applications. In addition, the supporting technology has evolved to the extent that image acquisition, field work, and digital analysis are today much more sophisticated than in the early days of analog imaging, computer mainframe-based processing, and qualitative analysis. However, with the wide range of remotely sensed data that is now available, the rapid and continued advances in the power and storage capacity of modern desktop computers, and the sophistication of the many software packages available, remote sensing is far from a static field. Indeed, the last decade has seen the development of commercial fine resolution remote sensing from space (Toutin, in this volume), the exponential growth of lidar (also known as airborne laser scanning) (Hyyppä et al., in this volume), and the increasing sophistication and automation of image processing, to name just a few examples. This rapid evolution of remote sensing technology suggests that there is a need for a periodic and relatively comprehensive review of the field of remote sensing. This book is an attempt to address that need.
In this introductory chapter we lay the groundwork for a theme that is common throughout many of the chapters in this book, namely, the trade-offs and issues that should be considered in selecting data for a specific problem. For example, in Chapter 25 Wulder et al. consider data selection within the context of vegetation characterization, and in Chapter 31, Crews and Walsh review data selection from the perspective of social scientists. This introductory chapter provides a broad perspective on this important topic.
Ironically, selecting data is today more challenging than in the past, a consequence of the wide range of data currently available. In the past, few remotely sensed data sets were available, and consequently the properties of the available data tended to determine the nature of the problems that could be addressed. Thus, an important part of early remote sensing research using the Earth Resources Technology Satellite (ERTS, later renamed Landsat) was simply to ask the question, ‘What can we do with these new data?’ Today, we have a vast array of data to select from in remote sensing, and so a new problem has emerged – how do we optimize the data characteristics that we use, so that the data will most effectively address a particular application or research problem? It should thus be clear that the definition of an optimal data set is entirely dependent on the aims of the project for which the data are intended.
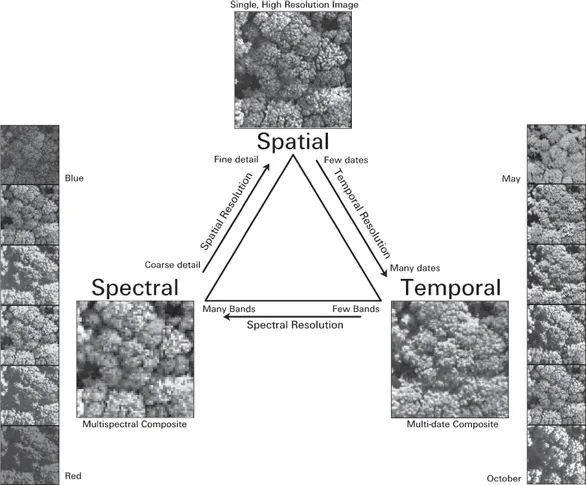
Adding to the complexity of choosing data attributes are three related issues. Firstly, there are fundamental physical and engineering tradeoffs that limit the nature and detail of the data that can be collected using an imaging system (Kerekes, in this volume; Figure 1.1). These constraints help explain the design choices made in satellite-borne sensors, and likewise need to be considered by those planning their own custom acquisitions of aerial imagery (Stow, in this volume).
A second issue that makes selecting the appropriate data for a project complex is that, just as too little data will likely reduce quality of the analysis, data with too much detail may also have a negative effect (Latty et al. 1985). It is intuitive that too much spatial detail can be burdensome for a computer-based analysis, and the same principle applies to other components of imagine information, including the spectral, radiometric, and temporal scales of the data. For example, Hughes (1968) showed that an excessive number of spectral bands can lead to lower classification accuracy, an observation that is known as the Hughes phenomenon (Swain and Davis 1978).
The last issue, perhaps the most important of the three, is the need to match the scale of the analysis to the scale of the phenomena under investigation (Wiens 1989). Inferences drawn from an analysis at one spatial scale are not necessarily valid at another scale, an issue known in ecology as cross-level ecological fallacy (Robinson 1950, Alker 1969). In geography, the dependence of observed patterns on how data are aggregated is known as the modifiable areal unit problem (MAUP, Openshaw and Taylor 1979, Openshaw 1983, 1984). The MAUP has two components (Jelinsky and Wu 1996):
Figure 1.1 Given a limited bandwidth for image acquisition, storage, and communication, trade-offs have to be made regarding the spatial, spectral, and temporal scale of the imagery that can be acquired. Radiometric scale (not shown) is also important. (See the color plate section of this volume for a color version of this figure).
Source: Figure reproduced from T. Key, T. Warner, J. McGraw, and M. A. Fajvan, 2001. A comparison of multispectral and multitemporal imagery for tree species classification. Remote Sensing of Environment 75: 100–112.
- The scale problem, which focuses on how results may vary as the size of the aggregation units (pixels, in the typical remote sensing analysis) varies.
- The zoning (or aggregation) problem, which focuses on how the results may vary as the shape, orientation and position of the units vary, even as the number of aggregation units is held constant.
In remote sensing, attention has usually focused on the MAUP scale problem, and less attention has been applied to the zoning problem (for an exception, see Jelinsky and Wu 1996), because most pixels are assumed to represent a similar, approximately square shape. However, NOAA Advanced Very High Resolution Radiometer (AVHRR) Global Area Coverage (GAC) data is produced by aggregating a linear-oriented subset of finer scale Local Area Coverage pixels (Justice and Tucker, in this volume), thus potentially opening the GAC data to zoning problems. Clearly, both scale and zoning MAUP problems are potentially present when ancillary vector-derived data are used in a remote sensing analysis (Merchant and Narumalani, in this volume).
Woodcock and Strahler (1987) provide a useful remote sensing conceptual framework that categorizes images based on the size...