![]()
1
Nucleic Acid Structure and Basic Analysis
Ralph Rapley
University of Hertfordshire, School of Life and Medical Sciences, College Lane, Hatfield, AL10 9AB, UK
*E-mail:
[email protected] Substantial advances have been made in gene analysis and genomics in recent years, and this has been accelerated by the continued development and refinement of methods and techniques for studying nucleic acids. The application of molecular biology techniques has allowed understanding of cellular processes, both in normal and disease states. The advent of this type of DNA analysis has provided insight into the genetic make up of patients and their disease susceptibility and diagnostics. Prognostic analysis has also allowed the development of personalised or precision medicine and there is now great promise in further developments in drug discovery and molecular gene therapy. This chapter provides an overview of the general features of nucleic acid structure and function. It also describes some of the basic methods used in nucleic acid isolation and analysis, including restriction analysis, blotting, hybridization, the polymerase chain reaction (PCR) and associated methods, such as quantitative PCR and further genetic tests based on this method.
1.1 Introduction
Major advances have been made in gene analysis and genomics in recent years and this has been accelerated by the continued development and refinement of methods and techniques for studying nucleic acids. One major area of current research is the identification and diagnosis of diseases that are multifactorial in nature. There are numerous diseases where analysis of genomes has provided insights into the disease and one particularly notable example is oncology. Molecular genetic analysis of this area has allowed a discrete set of cellular genes, termed oncogenes and tumour suppressor genes, to be identified and characterised. These genes and the proteins and enzymes they encode are major components of cell signalling and the cell cycle and are intimately involved in many aspects cell regulation. The disruption of oncogenes and tumour suppressor genes contributes to the early changes required for cancers to develop. Identification and analysis of these genes and genomes has already provided information for use in diagnostics and prognostics and a number have been shown to be biomarkers of a particular cancer type. In a number of cancers well-defined molecular events have been correlated with mutations in oncogenes and therefore in the corresponding protein. It is already possible to screen and predict the outcome of some disease processes at an early stage, a point which itself raises significant ethical dilemmas. The application of molecular biology has allowed understanding of cellular processes both in normal and disease states. The advent of this type of analysis has given rise to the development of personalised or precision medicine and there is now great promise in further developments in drug discovery and molecular gene therapy. A number of genetically engineered therapeutic proteins and enzymes have been developed and are already having an effect on disease management. In addition the correction of disorders at the gene level using gene therapy is also under way. Perhaps one of the most startling applications of molecular biology to date is indeed gene editing and the development of gene modifications methods such as the clustered regularly interspaced short palindromic repeats (CRISPR)–CRISPR-associated system 9 (cas9) system, which may have a profound effect on treating genetic-based diseases. In considering the potential utility of molecular biology techniques it is important to understand the basic structure of nucleic acids and gain an appreciation of how this dictates the function in vivo and in vitro. Indeed, many techniques used in molecular biology mimic in some way the natural functions of nucleic acids, such as replication and transcription. This chapter is intended to provide an overview of the general features of nucleic acid structure and function and describe some of the basic methods used in their isolation and analysis.
1.2 Structure of Nucleic Acids
1.2.1 Primary Structure of Nucleic Acids
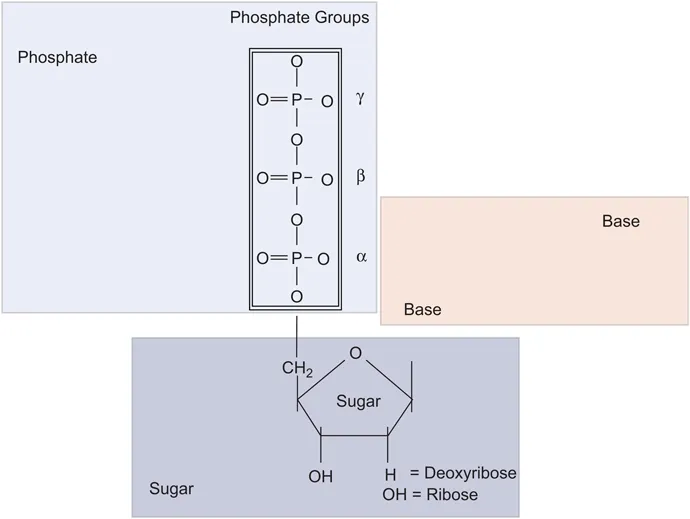
DNA and RNA are macromolecular structures composed of regular repeating polymers formed from nucleotides. 1 These are the basic building blocks of nucleic acids and are derived from nucleosides, which are composed of two elements: a five-membered pentose carbon sugar (2-deoxyribose in DNA and ribose in RNA), and a nitrogenous base (Figure 1.1). The carbon atoms of the sugar are designated ‘prime’ (l′, 2′, 3′, etc.). To distinguish them from the carbons of the nitrogenous bases, of which there are two types, either a purine or a pyrimidine. A nucleotide, or nucleoside phosphate, is formed by the attachment of a phosphate to the 5′ position of a nucleoside by an ester linkage. Such nucleotides can be joined together by the formation of a second ester bond by reaction between the phosphate of one nucleotide and the 3′ hydroxyl of another, thus generating a 5′ to 3′ phosphodiester bond between adjacent sugars; this process can be repeated indefinitely to give long polynucleotide molecules. DNA has two such polynucleotide strands. However, since each strand has both a free 5′ hydroxyl group at one end, and a free 3′ hydroxyl at the other end, each strand has a polarity or directionality. The polarities of the two strands of the molecule are in opposite directions, and thus DNA is described as an ‘anti-parallel’ structure.
Figure 1.1 Representation of a deoxynucleoside triphosphate indicating the three components of a sugar, triphosphate and a base. The base can be either A C G or T. In RNA the 2′ carbon has an OH whereas it is deoxy in DNA. Reproduced from ref. 22 with permission from the Royal Society of Chemistry.
The purine bases (composed of fused five- and six-membered rings), adenine (A) and guanine (G), are found in both RNA and DNA, as is the pyrimidine (a single six-membered ring) cytosine (C). The other pyrimidines are each restricted to one type of nucleic acid: uracil (U) occurs exclusively in RNA, whilst thymine (T) is limited to DNA. Thus it is possible to distinguish between RNA and DNA on the basis of the presence of ribose and uracil in RNA, and deoxyribose and thymine in DNA. However, it is the sequence of bases along the structure, which distinguishes one DNA (or RNA) from another.
1.2.2 Secondary Structure of Nucleic Acids
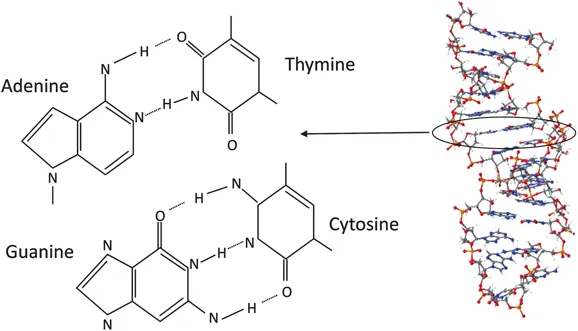
The two polynucleotide chains in DNA are usually found in the shape of a right-handed double helix, in which the bases of the two strands lie in the centre of the molecule, with the sugar–phosphate backbones on the outside. 2 A crucial feature of this double-stranded structure is that it depends on the sequence of bases in one strand being complementary to those in the other strand. A purine base attached to a sugar residue on one strand is always hydrogen bonded to a pyrimidine base attached to a sugar residue on the other strand. Moreover, adenine (A) always pairs with thymine (T) or uracil (U) in RNA, via two hydrogen bonds, and guanine (G) always pairs with cytosine (C) by three hydrogen bonds (Figure 1.2). When these conditions are met a stable double-helical structure results in which the backbones of the two strands are, on average, a constant distance apart. Thus, if the sequence of one strand is known, that of the other strand can be deduced. The strands are designated as plus (+) and minus (−) and an RNA molecule complementary to the minus (−) strand is synthesised during transcription. The base sequence may cause significant local variations in the shape of the DNA molecule, and these variations are vital for specific interactions between the DNA and various proteins to take place. Although the three-dimensional structure of DNA may vary it generally adopts a double helical structure termed the b form or b-DNA in vivo.
Figure 1.2 Representation of the four bases in DNA and their complementary base pairing, A–T and C–G through hydrogen bonds. The right hand side depicts a DNA double helix. Reproduced from ref. 22 with permission from the Royal Society of Chemistry.
It has been well recognized for some time that DNA as a structure may be chemically modified without the underlying DNA sequence being altered. One of the most important modifications is the addition of a methyl (CH3) group to cytosine, termed DNA methylation and catalysed by DNA methyltransferases. This results in what some describe as the fifth base in DNA. Approximately 1.5% of human DNA is methylated (termed the epigenome) and the methylation status appears to have a profound effect on gene expression, where hypomethylation appears to promote gene expression. This feature of gene expression control is termed epigenetics and is a complex process which is also extended to the modification of histone proteins and some small RNA molecules involved in gene expression control. Importantly, epigenetics appears to play a role in disease states, such as cancers and certain neurological diseases, which may lead to a new means of future treatment.
1.2.3 Denaturation of Double-stranded DNA
The two anti-parallel strands of DNA are held together only by the weak forces of hydrogen bonding between complementary bases, and partly by hydrophobic interactions between adjacent, stacked base pairs, termed base-stacking. Little energy is needed to separate a few base pairs, and so, at any instant, a few short stretches of DNA will be opened up to the single-stranded conformation. However, such stretches immediately pair up again at room temperature, so the molecule as a whole remains predominantly double-stranded.
If, however, a DNA solution is heated to approximately 90 °C or above there will be enough kinetic energy to denature the DNA completely, causing it to separate into single strands. The temperature at which 50% of the DNA is melted is termed the melting temperature or T m, and this depends on the nature of the DNA. If several different samples of DNA are melted, it is found that the T m is highest for those DNA molecules that contain the highest proportion of cytosine and guanine, and T m can actually be used to estimate the percentage (C + G) in a DNA sample. This relationship between T m and (C + G) content arises because cytosine and guanine form three hydrogen bonds when base-paired, whereas thymine and adenine form only two. Because of the differential numbers of hydrogen bonds between A–T and C–G pairs those sequences with a predominance of C–G pairs will require greater energy to separate or denature them. The conditions required to...