This section covers the Apache Spark fundamentals. It is important to become very familiar with the concepts that are presented here before moving on to the next chapters, where we'll be exploring the available APIs.
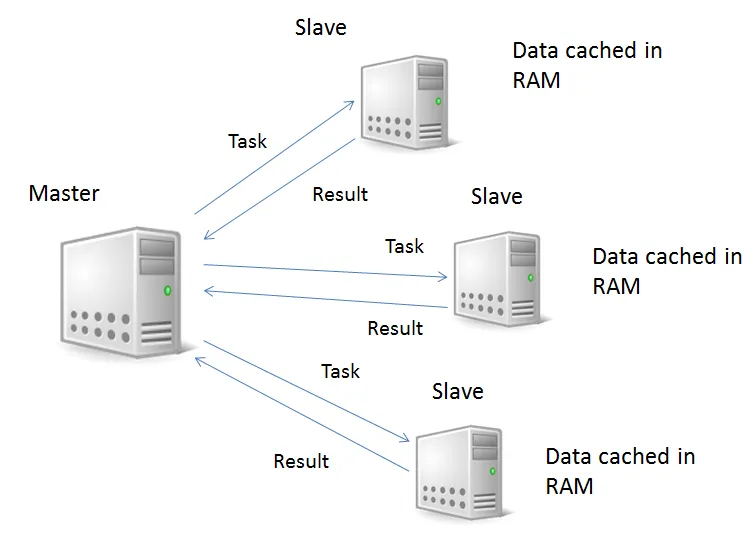
As mentioned in the introduction to this chapter, the Spark engine processes data in distributed memory across the nodes of a cluster. The following diagram shows the logical structure of how a typical Spark job processes information:
Spark can access data that's stored in different systems, such as HDFS, Cassandra, MongoDB, relational databases, and also cloud storage services such as Amazon S3 and Azure Data Lake Storage.
Now, let's get hands-on with Spark so that we can go deeper into the core APIs and libraries. In all of the chapters of this book, I will be referring to the 2.2.1 release of Spark, however, several examples that are presented here should work with the 2.0 release or later. I will put a note when an example is specifically for 2.2+ releases only.
First of all, you need to download Spark from its official website (https://spark.apache.org/downloads.html). The download page should look like this:
Figure 1.4
You need to have JDK 1.8+ and Python 2.7+ or 3.4+ (only if you need to develop using this language). Spark 2.2.1 supports Scala 2.11. The JDK needs to be present on your user path system variable, though, alternatively, you could have your user JAVA_HOME environment variable pointing to a JDK installation.
Extract the content of the downloaded archive to any local directory. Move to the $SPARK_HOME/bin directory. There, among the other executables, you will find the interactive Spark shells for Scala and Python. They are the best way to get familiar with this framework. In this chapter, I am going to present examples that you can run through these shells.
You can run a Scala shell using the following command:
$SPARK_HOME/bin/spark-shell.sh
If you don't specify an argument, Spark assumes that you're running locally in standalone mode. Here's the expected output to the console:
Spark context Web UI available at http://10.72.0.2:4040
Spark context available as 'sc' (master = local[*], app id = local-1518131682342).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.1
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_91)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
The web UI is available at the following URL: http://<host>:4040.
It will give you the following output:
Figure 1.5
From there, you can check the status of your jobs and executors.
From the output of the console startup, you will notice that two built-in variables, sc and spark, are available. sc represents the SparkContext (http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.SparkContext), which in Spark < 2.0 was the entry point for each application. Through the Spark context (and its specializations), you can get input data from data sources, create and manipulate RDDs (http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.RDD), and attain the Spark primary abstraction before 2.0. The RDD programming section will cover this topic and other operations in more detail. Starting from release 2.0, a new entry point, SparkSession (http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.SparkSession), and a new main data abstraction, the Dataset (http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset), were introduced. More details on them are presented in the following sections. The SparkContext is still part of the Spark API so that compatibility with existing frameworks not supporting Spark sessions is ensured, but the direction the project has taken is to move development to use the SparkSession.
Here's an example of how to read and manipulate a text file and put it into a Dataset using the Spark shell (the file used in this example is part of the resources for the examples that are bundled with the Spark distribution):
scala> spark.read.textFile("/usr/spark-2.2.1/examples/src/main/resources/people.txt")
res5: org.apache.spark.sql.Dataset[String] = [value: string] The result is a Dataset instance that contains the file lines. You can then make several operations on this Dataset, such as counting the number of lines:
scala> res5.count()
res6: Long = 3
You can also get the first line of the Dataset:
scala> res5.first()
res7: String = Michael, 29
In this example, we used a path on the local fi...