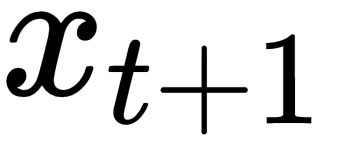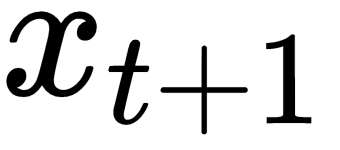In this chapter, we will describe some of the most exciting techniques in modern (at the time of writing—late 2017) machine learning, recurrent neural networks. They are, however, not new; they have been around since the 1980s, but they have become popular due to the numerous records in language-related tasks in recent years.
Why do we need a different type of architecture for text? Consider the following example:
"I live in Prague since 2015"
and
"Since 2015 I live in Prague"
If we would like to teach a traditional feed-forward network such as a perceptron or a multi-layer perceptron to identify the date I moved to Prague, then this network would have to learn separate parameters for each input feature, which in particular implies that it would have to learn grammar to answer this simple question! This is undesirable in many applications. Similar issues motivated machine learning researchers and statisticians in the 1980s to introduce the idea of sharing parameters across different parts of the model. This idea is the secret sauce of recurrent neural networks, our next deep learning architecture.
By design, recurrent neural networks are well-suited for processing sequential data. In general, machine learning applied to sequential data can be roughly divided into four main areas:
- Sequence prediction: Given , predict the next element of the sequence,
- Sequence classification: Given , predict a category or label for it
- Sequence generation: Given , generate a new element of the sequence,
- Sequence to sequence prediction: Given , generate an equivalent sequence,
Applications of sequence prediction include weather forecasting and stock market prediction. For classification, we can think, for example, of sentiment analysis and document classification. Automatic image captioning or text generation are part of the sequence generation family of problems, whereas machine translation might be the most familiar example of sequence to sequence prediction we see in our everyday lives.
Our focus for this chapter is on applications of recurrent neural networks for text generation. Since, as we saw previously, text generation is part of a much larger set of problems, many of our algorithms are portable to other contexts.
Training deep learning models is often time-consuming, and recurrent neural networks are not the exception. Our focus is on the ideas over the data, which we will illustrate with smaller datasets than those that you might encounter later on in the wild. This is for the purpose of clarity: We want to make it easier for you to get started on any standard laptop. Once you grasp the basics, you can spin off your own cluster in your favorite cloud provider.
![]()
Coming from a mathematics background, in my rather hectic career I have seen many different trends, particularly during the last few years, which all sound very similar to me: "you have a problem? wavelets can save you!", "finite elements are the solution to everything", and similar over-enthusiastic claims.
Of course, each tool has its time and place and, more importantly, an application domain where it excels. I find recurrent neural networks quite interesting for the many features they can achieve:
- Produce consistent markup text (opening and closing tags, recognizing timestamp-like data)
- Write Wikipedia articles with references, and create URLs from non-existing addresses, by learning what a URL should look like
- Create credible-looking scientific papers from LaTeX
All these amazing features are possible without the network having any context information or metadata. In particular, without knowing English, nor what a URL or a bit of LaTeX syntax looks like.
These and even more interesting capabilities of neural networks are superbly described by Andrej Karpathy in The Unreasonable Effectiveness of Recurrent Neural Networks: http://karpathy.github.io/2015/05/21/rnn-effectiveness/.
What makes recurrent neural networks exciting? Instead of a constrained fixed-input size to fixed-output size, we can operate over sequences of vectors instead.
A limitation of many machine learning algorithms, including standard feed-forward neural networks, is that they accept a fixed size vector as input and produce a fixed size vector as output. For instance, if we want to classify text, we receive a corpus of documents from which we create a vocabulary to vectorize each document and the output is a vector with class probabilities. Recurrent neural networks instead allow us to take sequences of vectors as input. So, from a one-to-one correspondence between fixed input size and fixed output size, we have a much richer landscape, one-to-one, one-to-many, many-to-one, many-to-many.
Why is that desirable? Let's look at a few examples:
- One-to-one: Supervised learning, for instance, text classification
- One-to-many: Given an input text, generate a summary (a sequence of words with important information)
- Many-to-one: Sentiment analysis in text
- Many-to-many: Machine translation
Moreover, as recurrent neural networks maintain an internal state which gets updated according to new information, we can view RNNs as a description of a program. In fact, a paper by Siegelman in 1995 shows that recurrent neural networks are Turing complete, they can simulate arbitrary programs.
![]()
How does the network keep track of the previous states? To put it in the context of text generation, think of our training data as a list of character sequences (tokenized words). For each word, from the first character, we will predict the following:
Formally, let's denote a sequence of t+1 characters as x = [x0, x1, x2, ... , xt]. Let s-1 =0.
For k=0,2,...t, we construct the following sequence:
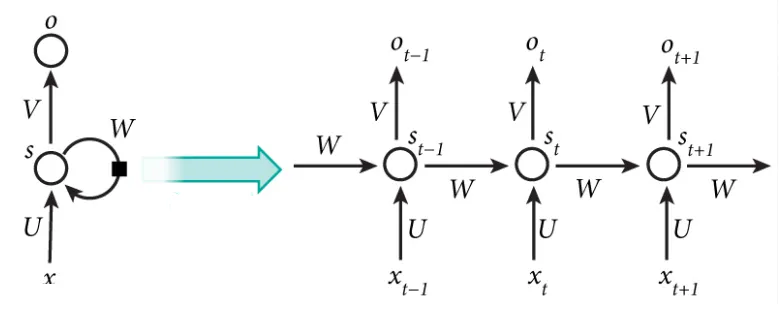
This is summarized in the following diagram, when input x is received, the internal state, s, of the network is modified, and then used to generate an output, o:
Figure 1...