Comprehensive coverage of all aspects of space application oriented fault tolerance techniques
• Experienced expert author working on fault tolerance for Chinese space program for almost three decades
• Initiatively provides a systematic texts for the cutting-edge fault tolerance techniques in spacecraft control computer, with emphasis on practical engineering knowledge
• Presents fundamental and advanced theories and technologies in a logical and easy-to-understand manner
• Beneficial to readers inside and outside the area of space applications

eBook - ePub
Fault-Tolerance Techniques for Spacecraft Control Computers
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Fault-Tolerance Techniques for Spacecraft Control Computers
About this book
Trusted by 375,005 students
Access to over 1 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
1
Introduction
A control computer is one of the key equipment in a spacecraft control system. Its reliability is critical to the operations of the spacecraft. Furthermore, the success of a space mission hinges on failure‐free operation of the control computer. In a mission flight, a spacecraft’s long‐term operation in a hostile space environment without maintenance requires a highly reliable control computer, which usually employs multiple fault‐tolerance techniques in the design phase. With focus on the spacecraft control computer’s characteristics and reliability requirements, this chapter provides an overview of fundamental fault‐tolerance concepts and principles, analyzes the space environment, emphasizes the importance of fault‐tolerance techniques in the spacecraft control computer, and summarizes the current status and future development direction of fault‐tolerance technology.
1.1 Fundamental Concepts and Principles of Fault‐tolerance Techniques
Fault‐tolerance technology is an important approach to guarantee the dependability of a spacecraft control computer. It improves system reliability through implementation of multiple redundancies. This section briefly introduces its fundamental concepts and principles.
1.1.1 Fundamental Concepts
“Fault‐tolerance” refers to “a system’s ability to function properly in the event of one or more component faults,” which means the failure of a component or a subsystem should not result in failure of the system. The essential idea is to achieve a highly reliable system using components that may have only standard reliability [1]. A fault‐tolerant computer system is defined as a system that is designed to continue fulfilling assigned tasks even in the event of hardware faults and/or software errors. The techniques used to design and analyze fault‐tolerant computer systems are called fault‐tolerance techniques. The combination of theories and research related to fault‐tolerant computer techniques is termed fault‐tolerant computing [2–4].
System reliability assurance depends on the implementation of fault‐tolerance technology. Before the discussion of fault‐tolerance, it is necessary to clarify the following concepts [4,5]:
- Fault: a physical defect in hardware, imperfection in design and manufacturing, or bugs in software.
- Error: information inaccuracy or incorrect status resulting from a fault.
- Failure: a system’s inability to provide the target service.
A fault can either be explicit or implicit. An error is a consequence and manifestation of a fault. A failure is defined as a system’s inability to function. A system error may or may not result in system failure – that is, a system with a fault or error may still be able to complete its inherent function, which serves as the foundation of fault‐tolerance theory. Because there are no clearly defined boundaries, concepts 1, 2, and 3 above are usually collectively known as “fault” (failure).
Faults can be divided into five categories on the basis of their pattern of manifestation, as shown in Figure 1.1.
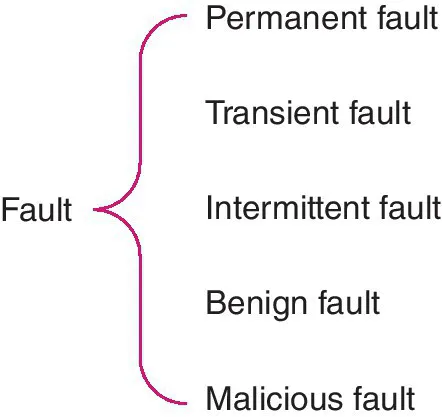
Figure 1.1 Fault categorization.
“Permanent fault” can be interpreted as permanent component failure. “Transient fault” refers to the component’s failure at a certain time. “Intermittent fault” refers to recurring component failure – sometimes a failure occurs, sometimes it does not. When there is no fault, the system operates properly; when there is a fault, the component fails. A “benign fault” only results in the failure of a component, which is relatively easy to handle. A “malicious fault” causes the failed component to appear normal, or transmit inaccurate values to different receivers as a result of malfunction – hence, it is more hostile.
Currently, the following three fault‐tolerant strategies are utilized [4–6]:
- Fault masking. This strategy prevents faults from entering the system through redundancy design, so that faults are transparent to the system, having no influence. It is mainly applied in systems that require high reliability and real‐time performance. The major methods include memory correction code and majority voting. This type of method is also called static redundancy.
- Reconfiguration. This strategy recovers system operation through fault removal. It includes the following steps:
- Fault detection – fault determination, which is a necessary condition for system recovery;
- Fault location – used to determine the position of the fault;
- Fault isolation – used to isolate the fault to prevent its propagation to other parts of the system;
- Fault recovery – used to recover system operation through reconfiguration.This method is also defined as dynamic redundancy.
- Integration of fault masking and reconfiguration. This integration realizes system fault‐tolerance through the combination of static redundancy and dynamic redundancy, also called hybrid redundancy.
In addition to strategies 1, 2, and 3 above, analysis shows that, in certain scenarios, it is possible to achieve fault‐tolerance through degraded redundancy. Since degraded redundancy reduces or...
Table of contents
- Cover
- Title Page
- Table of Contents
- Brief Introduction
- Preface
- 1 Introduction
- 2 Fault‐Tolerance Architectures and Key Techniques
- 3 Fault Detection Techniques
- 4 Bus Techniques
- 5 Software Fault‐Tolerance Techniques
- 6 Fault‐Tolerance Techniques for FPGA
- 7 Fault‐Injection Techniques
- 8 Intelligent Fault‐Tolerance Techniques
- Acronyms
- Index
- End User License Agreement
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
- Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
- Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.4M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Fault-Tolerance Techniques for Spacecraft Control Computers by Mengfei Yang,Gengxin Hua,Yanjun Feng,Jian Gong in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Engineering. We have over one million books available in our catalogue for you to explore.