Scientific computing has become an indispensable tool in numerous fields, such as physics, mechanics, biology, finance and industry. For example, it enables us, thanks to efficient algorithms adapted to current computers, to simulate, without the help of models or experimentations, the deflection of beams in bending, the sound level in a theater room or a fluid flowing around an aircraft wing.
This book presents the scientific computing techniques applied to parallel computing for the numerical simulation of large-scale problems; these problems result from systems modeled by partial differential equations. Computing concepts will be tackled via examples.
Implementation and programming techniques resulting from the finite element method will be presented for direct solvers, iterative solvers and domain decomposition methods, along with an introduction to MPI and OpenMP.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
This chapter does not claim to be a course in computer programming. Only those architectural features which are not obvious to the user, i.e. those that imperatively need to be taken into account for coding which achieves the optimal performance of scientific computers, are presented here. Therefore, we will not be going into the details of hardware and software technologies of computer systems, but will only explain those principles and notions that are indispensable to learn.
1.1. Different types of parallelism
1.1.1.Overlap, concurrency and parallelism
The objective of numerical simulation is to approximate, as closely as possible, physical reality, through the use of discrete models. The richer the model, and the more parameters it takes into account, the greater the amount of computational power. The function of supercomputers is to permit the execution of a large number of calculations in a sufficiently short time, so that the simulation tool can be exploited as part of a design process, or in forecasting.
The natural criterion of performance for a supercomputer is based on the speed of calculations, or the number of arithmetic operations achievable per second. These arithmetic operations – addition, subtraction, multiplication or division – involve data, either real or complex, which are represented by floating point numbers. A floating point number is a real number that is represented by two integers, a mantissa and an exponent. Since computers work in base 2, the value of a real number, represented in floating point representation, is equal to the mantissa or signific and multiplied by 2 times the power of the exponent. The precision of a real number is then limited by the length of the mantissa. The unit used to measure calculation speeds is the “flops” (floating point operations per second). As the frequencies of current microprocessors have increased, the following terms are commonly employed: Mflops, or a million operations per second (Mega = 106); Gflops, or a billion operations per second (Giga = 109); Tflops, which is a trillion operations per second (Tera = 1012); and even Pflops, or a quadrillion operations per second (Peta = 1015). Speeds are dependent upon the technologies used for components and depend on the frequencies of the microprocessors. Up until the early 2000s, there were enormous improvements in the integration of semi–conductor circuits due to manufacturing processes and novel engraving techniques. These technological advances have permitted the frequency of microprocessors to double, on average, every 18 months. This observation is known as Moore’s law. In the past few years, after that amazing acceleration in speeds, the frequencies are now blocked at a few GHz. Increasing frequencies beyond these levels has provoked serious problems of overheating that lead to excessive power consumption, and technical constraints have also been raised when trying to evacuate the heat.
At the beginning of the 1980s, the fastest scientific computers clocked in around 100 MHz and the maximum speeds were roughly 100 Mflops. A little more than 20 years later, the frequencies are a few GHz, and the maximum speeds are on the order of a few Tflops. To put this into perspective, the speeds due to the evolution of the basic electronic components have been increased by a factor in the order of tens, yet computing power has increased by a factor bordering on hundreds of thousands. In his book Physics Of The Future, Michio Kaku observes that: “Today, your cell phone has more computer power than all of NASA back in 1969, when it placed two astronauts on the moon.” How is this possible? The explanation lies in the evolution of computer architectures, and more precisely in the use of parallelization methods. The most natural way to overcome the speed limits linked to the frequencies of processors is to duplicate the arithmetic logic units: the speed is twice as fast if two adders are used, rather than one, if the functional units can be made to work simultaneously. The ongoing improvements in semi-conductor technology no longer lead to increases in frequencies. However, recent advances allow for greater integration, which in turn permits us to add a larger number of functional units on the same chip, which can even go as far as to completely duplicate the core of the processor. Pushing this logic further, it is also possible to multiply the number of processors in the same machine. Computer architecture with functional units, or where multiple processors are capable of functioning simultaneously to execute an application, is referred to as “parallel”. The term “parallel computer” generally refers to a machine that has multiple processors. It is this type of system that the following sections of this work will primarily focus on.
But even before developing parallel architectures, manufacturers have always been concerned about making the best use of computing power, and in particular trying to avoid idle states as much as possible. This entails the recovery of execution times used for the various coding instructions. To more rapidly perform a set of operations successively using separate components, such as the memory, data bus, arithmetic logic units (ALUs), it is possible to begin the execution of a complex instruction before the previous instruction has been completed. This is called instruction “overlap”.
More generally, it is sometimes possible to perform distinct operations simultaneously, accessing the main or secondary memory on the one hand, while carrying out arithmetical operations in the processor, on the other hand. This is referred to as “concurrency” . This type of technique has been used for a long time in all systems that are able to process several tasks at the same time using timesharing. The global output of the system is optimized, without necessarily accelerating the execution time of each separate task.
When the question is of accelerating the execution of a single program, the subject of this book, things become more complicated. We have to produce instruction packets that are susceptible to benefit from concurrency. This requires not only tailoring the hardware, but also adapting the software. So, parallelization is a type of concurrent operations in cases where certain parts of the processor, or even the complete machine, have been duplicated so that instructions, or instruction packets, often very similar, can be simultaneously executed.
1.1.2.Temporal and spatial parallelism for arithmetic logic units
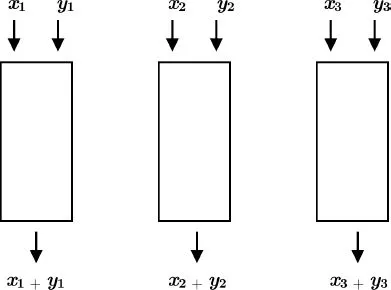
The parallelism introduced in the preceding section is also referred to as spatial parallelism. To increase processing output, we can duplicate the work; for example, with three units we can triple the output.
Figure 1.1.Spatial parallelism: multiplication of units
There is also what is called temporal parallelism, which relies on the overlap of synchronized successive similar instructions. The model for this is the assembly line. The principle consists of dividing up assembly tasks into a series of successive operations, with a similar duration. If the chain has three levels, when the operations of the first level are completed, the object being assembled is then passed onto the second level where immediately the operations of the first level for a new object are begun, and so forth. Thus, if the total time of fabrication of each object consists of three cycles, a new finished object is completed every three cycles of the chain. Schematically, this is as fast as having three full workshops running simultaneously. This way of functioning allows us, on the one hand, to avoid duplication of all the tools, and on the other hand, also assures a more continuous flow ...
Table of contents
Cover
Table of Contents
Title
Copyright
Preface
Introduction
1 Computer Architectures
2 Parallelization and Programming Models
3 Parallel Algorithm Concepts
4 Basics of Numerical Matrix Analysis
5 Sparse Matrices
6 Solving Linear Systems
7 LU Methods for Solving Linear Systems
8 Parallelization of LU Methods for Dense Matrices
9 LU Methods for Sparse Matrices
10 Basics of Krylov Subspaces
11 Methods with Complete Orthogonalization for Symmetric Positive Definite Matrices
12 Exact Orthogonalization Methods for Arbitrary Matrices
13 Biorthogonalization Methods for Non-symmetric Matrices
14 Parallelization of Krylov Methods
15 Parallel Preconditioning Methods
Appendices
Bibliography
Index
End User License Agreement
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Parallel Scientific Computing by Frédéric Magoules,François-Xavier Roux,Guillaume Houzeaux in PDF and/or ePUB format, as well as other popular books in Computer Science & Computer Engineering. We have over 1.5 million books available in our catalogue for you to explore.