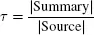![]()
PART 1
Foundations
![]()
1
Why Summarize Texts?
In the 1780s, Joseph Joubert1 was already tormented by his ambition to summarize texts and condense sentences. Though he did not know it, he was a visionary of the field of automatic text summarization, which was born some two and a half centuries later with the arrival of the Internet and the subsequent surge in the number of documents. Despite this surge, the number of documents which have been annotated (with Standard Generalized Markup Language (SGML), Extensible Markup Language (XML) or their dialects) remains small compared to unstructured text documents. As a result, this huge volume of documents quickly accumulates to even larger quantities. As a result, text documents are often analyzed in a perfunctory and very superficial way. In addition, different types of documents, such as administrative notes, technical reports, medical documents and legal and scientific texts, etc., have very different writing standards. Automatic text analysis tasks and text mining2 [BER 04, FEL 07, MIN 02] as exploration, information extraction (IE), categorization and classification, among others, are therefore becoming increasingly difficult to implement [MAN 99b].
1.1. The need for automatic summarization
The expression “too much information kills information” is as relevant today as it has ever been. The fact that the Internet exists in multiple languages does nothing but increase the aforementioned difficulties regarding document analysis. Automatic text summarization helps us to efficiently process the ever-growing volume of information, which humans are simply incapable of handling. To be efficient, it is essential that the storage of documents is linked to their distribution. In fact, providing summaries alongside source documents is an interesting idea: summaries would become an exclusive way of accessing the content of the source document [MIN 01]. However, unfortunately this is not always possible.
Summaries written by the authors of online documents are not always available: they either do not exist or have been written by somebody else. In fact, summaries can either be written by the document author, professional summarizers3 or a third party. Minel et al. [MIN 01] have questioned why we are not happy with the summaries written by professional summarizers. According to the authors there are a number of reasons: “[…] because the cost of production of a summary by a professional is very high. […] Finally, the reliability of this kind of summary is very controversial”. Knowing how to write documents does not always equate with knowing how to write correct summaries. This is even more true when the source document(s) relate to a specialized domain.
Why summarize texts? There are several valid reasons in favor of the – automatic – summarization of documents. Here are just a few [ARC 13]:
1) Summaries reduce reading time.
2) When researching documents, summaries make the selection process easier.
3) Automatic summarization improves the effectiveness of indexing.
4) Automatic summarization algorithms are less biased than human summarizers.
5) Personalized summaries are useful in question-answering systems as they provide personalized information.
6) Using automatic or semi-automatic summarization systems enables commercial abstract services to increase the number of texts they are able to process.
In addition to the above, the American National Standards Institute4 (ANSI) [ANS 79] states that “a well prepared abstract enables readers to identify the basic content of a document quickly and accurately, to determine its relevance to their interests, and thus to decide whether they need to read the document in its entirety”. Indeed, in 2002 the SUMMAC report supports this assertion by demonstrating that “summaries as short as 17% of full text length sped up decision-making by almost a factor of 2 with no statistically significant degradation in accuracy” [MAN 02].
1.2. Definitions of text summarization
The literature provides various definitions of text summarization. In 1979, the ANSI provided a concise definition [ANS 79]:
DEFINITION 1.1.– [An abstract] is an abbreviated, accurate representation of the contents of a document, preferably prepared by its author(s) for publication with it. Such abstracts are useful in access publications and machine-readable databases.
According to van Dijk [DIJ 80]:
DEFINITION 1.2.– The primary function of abstracts is to indicate and predict the structure and content of the text.
According to Cleveland [CLE 83]:
DEFINITION 1.3.– An abstract summarizes the essential contents of a particular knowledge record, and it is a true surrogate of the document.
Nevertheless, it is important to understand that these definitions describe summaries produced by people. Definitions of automatic summarization are considerably less ambitious. For instance, automatic text summarization is defined in the Oxford English dictionary5 as:
DEFINITION 1.4.– The creation of a shortened version of a text by a computer program. The product of this procedure still contains the most important points of the original text.
Automatically generated summaries do not need to be stored in databases (unlike the ANSI summaries) as they are generated online in accordance with users’ needs. After all, the main objective of automatic summarization is to provide readers with information and give him or her exclusive access to the source literature [MOE 00, MAN 01]. Nevertheless, summarizing text documents is a process of compression, which involves the loss of information. The process is automatic when it is carried out by an algorithm or a computer system. But what information should be included in the summary that is provided to the user? [SPÄ 93, SPÄ 97]. An intuitive answer would be that the generated summary must contain the most important and representative content from the source document. But how can we measure the representativeness and the significance of the information? This is one of the key questions automatic text summarization algorithms are trying to answer.
Karen Spärck-Jones and Tetsuya Sakai [SAK 01] defined the process of generating automatic text summaries (or abstract process) in their 2001 article as follows:
DEFINITION 1.5.– A summary is a reductive transformation of a source text into a summary text by extraction or generation.
According to Radev et al. [RAD 00]:
DEFINITION 1.6.– Text Summarization (TS) is the process of identifying salient concepts in text narrative, conceptualizing the relationships that exist among them and generating concise representations of the input text that preserve the gist of its content.
In 2002, Radev et al. [RAD 02a] introduced the concept of multidocument summarization and the length of the summary in their definition:
DEFINITION 1.7.– [A summary is] a text that is produced from one or more texts, that conveys important information in the original text(s), and that is no longer than half of the original text(s) and usually significantly less than that.
According to Horacio Saggion and Guy Lapalme [SAG 02b], in terms of function, a summary is:
DEFINITION 1.8.– A condensed version of a source document having a recognizable genre and a very specific purpose: to give the reader an exact and concise idea of the contents of the source.
The ratio between the length of the summary and the length of the source document is calculated by the compression rate τ:
where | • | indicates the length of the document in characters, words or sentences. τ can be expressed as a percentage.
So what is the optimal value for the compression rate? The ANSI recommends that summaries be no longer than 250 words [ANS 79]. [BOR 75] indicate that a rate of τ = 10% is desirable for summaries. In contrast, [GOL 99] maintain that the length of the summary is not connected to the length of the source text. Finally, [RAD 02a] and [HOV 05] specify that the length of the summary must be less than half of that of the source document. In fact, [LIN 99]’s study shows that the best performances of automatic summarization systems are found with a compression rate of τ = 15 to 30% of the length of the source document.
We are now going to introduce a definition of automatic summarization, inspired by [HOV 05]6 , which takes the length of the source document into account:
DEFINITION 1.9.– An automatic summary is a text generated by a software, that is coherent and contains a significant amount of relevant information from the source text. Its compression rate τ is less than a third of the length of the original document.
Generating summaries demands that the summarizer (both human and algorithm) make an effort to select, reformulate and create a coherent text containing the most informative segments of a document. The notion of segments of information is left purposefully vague. Summaries can be guided by a particular profile, topic or query, as is the case for multidocument summarization [MAN 99a, MOR 99, MAN 01. Finally, coherence, cohesion as well as the temporality of the information presented must also be respected.
Many different types of document summarizations exist. There are two main reasons for this: first, there are many different types and sources of documents and, second, people have different uses for summaries and are, thus, not looking for the same type of document summarization. In any case, there is a gene...