A pragmatic approach to Big Data by taking the reader on a journey between Big Data (what it is) and the Smart Data (what it is for).
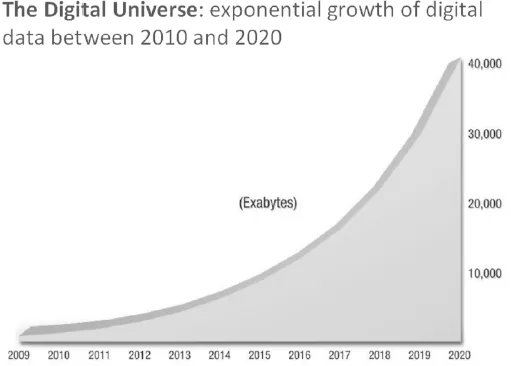
Today's decision making can be reached via information (related to the data), knowledge (related to people and processes), and timing (the capacity to decide, act and react at the right time). The huge increase in volume of data traffic, and its format (unstructured data such as blogs, logs, and video) generated by the "digitalization" of our world modifies radically our relationship to the space (in motion) and time, dimension and by capillarity, the enterprise vision of performance monitoring and optimization.