A comprehensive look at state-of-the-art ADP theory and real-world applications
This book fills a gap in the literature by providing a theoretical framework for integrating techniques from adaptive dynamic programming (ADP) and modern nonlinear control to address data-driven optimal control design challenges arising from both parametric and dynamic uncertainties.
Traditional model-based approaches leave much to be desired when addressing the challenges posed by the ever-increasing complexity of real-world engineering systems. An alternative which has received much interest in recent years are biologically-inspired approaches, primarily RADP. Despite their growing popularity worldwide, until now books on ADP have focused nearly exclusively on analysis and design, with scant consideration given to how it can be applied to address robustness issues, a new challenge arising from dynamic uncertainties encountered in common engineering problems.
Robust Adaptive Dynamic Programming zeros in on the practical concerns of engineers. The authors develop RADP theory from linear systems to partially-linear, large-scale, and completely nonlinear systems. They provide in-depth coverage of state-of-the-art applications in power systems, supplemented with numerous real-world examples implemented in MATLAB. They also explore fascinating reverse engineering topics, such how ADP theory can be applied to the study of the human brain and cognition. In addition, the book:
Covers the latest developments in RADP theory and applications for solving a range of systems' complexity problems
Explores multiple real-world implementations in power systems with illustrative examples backed up by reusable MATLAB code and Simulink block sets
Provides an overview of nonlinear control, machine learning, and dynamic control
Features discussions of novel applications for RADP theory, including an entire chapter on how it can be used as a computational mechanism of human movement control
Robust Adaptive Dynamic Programming is both a valuable working resource and an intriguing exploration of contemporary ADP theory and applications for practicing engineers and advanced students in systems theory, control engineering, computer science, and applied mathematics.
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Reinforcement learning (RL) is originally observed from the learning behavior in humans and other mammals. The definition of RL varies in different literature. Indeed, learning a certain task through trial-and-error can be considered as an example of RL. In general, an RL problem requires the existence of an agent, that can interact with some unknown environment by taking actions, and receiving a reward from it. Sutton and Barto referred to RL as how to map situations to actions so as to maximize a numerical reward signal [47]. Apparently, maximizing a reward is equivalent to minimizing a cost, which is used more frequently in the context of optimal control [32]. In this book, a mapping between situations and actions is called a policy, and the goal of RL is to learn an optimal policy such that a predefined cost is minimized.
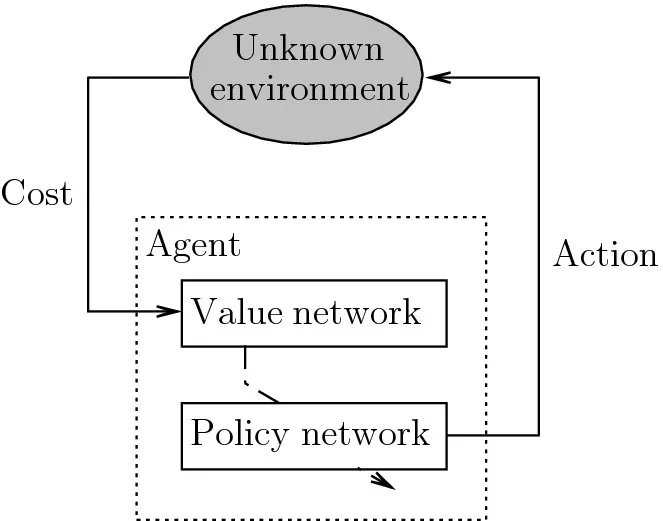
As a unique learning approach, RL does not require a supervisor to teach an agent to take the optimal action. Instead, it focuses on how the agent, through interactions with the unknown environment, should modify its own actions toward the optimal one (Figure 1.1). An RL iteration generally contains two major steps. First, the agent evaluates the cost under the current policy, through interacting with the environment. This step is known as policy evaluation. Second, based on the evaluated cost, the agent adopts a new policy aiming at further reducing the cost. This is the step of policy improvement.
Figure 1.1 Illustration of RL. The agent takes an action to interact with the unknown environment, and evaluates the resulting cost, based on which the agent can further improve the action to reduce the cost.
As an important branch in machine learning theory, RL has been brought to the computer science and control science literature as a way to study artificial intelligence in the 1960s [37, 38, 54]. Since then, numerous contributions to RL, from a control perspective, have been made (see, e.g., [2, 29, 33, 34, 46, 53, 56]). Recently, AlphaGo, a computer program developed by Google DeepMind, is able to improve itself through reinforcement learning and has beaten professional human Go players [44]. It is believed that significant attention will continuously be paid to the study of reinforcement learning, since it is a promising tool for us to better understand the true intelligence in human brains.
1.1.2 Introduction to DP
On the other hand, dynamic programming (DP) [4] offers a theoretical way to solve multistage decision-making problems. However, it suffers from the inherent computational complexity, also known as the curse of dimensionality [41]. Therefore, the need for approximative methods has been recognized as early as in the late 1950s [3]. In [15], an iterative technique called policy iteration (PI) was devised by Howard for Markov decision processes (MDPs). Also, Howard referred to the iterative method developed by Bellman [3, 4] as value iteration (VI). Computing the optimal solution through successive approximations, PI is closely related to learning methods. In 1968, Werbos pointed out that PI can be employed to perform RL [58]. Starting from then, many real-time RL methods for finding online optimal control policies have emerged and they are broadly called approximate/adaptive dynamic programming (ADP) [31, 33, 41, 43, 55, 60–65, 68], or neurodynamic programming [5]. The main feature of ADP [59, 61] is that it employs ideas from RL to achieve online approximation of the value function, without using the knowledge of the system dynamics.
1.1.3 The Development of ADP
The development of ADP theory consists of three phases. In the first phase, ADP was extensively investigated within the communities of computer science and operations research. PI and VI are usually employed as two basic algorithms. In [46], Sutton introduced the temporal difference method. In 1989, Watkins proposed the well-known Q-learning method in his PhD thesis [56]. Q-learning shares similar features with the action-dependent heuristic dynamic programming (ADHDP) scheme proposed by Werbos in [62]. Other related research work under a discrete time and discrete state-space Markov decision process framework can be found in [5, 6, 8, 9, 41, 42, 48, 47] and references therein. In the second phase, stability is brought into the context of ADP while real-time control problems are studied for dynamic systems. To the best of our knowledge, Lewis and his co-workers are the first who contributed to the integration of stability theory and ADP theory [33]. An essential advantage of ADP theory is that an optimal control policy can be obtained via a recursive numerical algorithm using online information without solving the Hamilton-Jacobi-Bellman (HJB) equation (for nonlinear systems) and the algebraic Riccati equation (ARE) (for linear systems), even when the system dynamics are not precisely known. Related optimal feedback control designs for linear and nonlinear dynamic systems have been proposed by several researchers over the past few years; see, for example, [7, 10, 39, 40, 50, 52, 66, 69]. While most of the previous work on ADP theory was devoted to discrete-time (DT) systems (see [31] and references therein), there has been relatively less research for the continuous-time (CT) counterpart. This is mainly because ADP is considerably more difficult for CT systems than for DT systems. Indeed, many results developed for DT systems [35] cannot be extended straightforwardly to CT systems. As a result, early attempts were made to apply Q-learning for CT systems via discretization technique [1, 11]. However, the convergence and stability analysis of these schemes are challenging. In [40], Murray et. al proposed an implementation method which requires the measurements of the derivatives of the state variables. As said previously, Lewis and his co-workers proposed the first solution to stability analysis and convergence proofs for ADP-based control systems by means of linear quadratic regulator (LQR) theory [52]. A synchronous policy iteration scheme was also presented in [49]. For CT linear systems, the partial knowledge of the system dynamics (i.e., the input matrix) must be precisely known. This restriction has been completely removed in [18]. A nonlinear variant of this method can be found in [22] and [23].
The third phase in the development of ADP theory is related to extensions of previous ADP results to nonlinear uncertain systems. Neural networks and game theory are utilized to address the presence of uncertainty and nonlinearity in control systems. See, for example, [14, 31, 50, 51, 57, 67, 69, 70]. An implicit assumption in these papers is that the system order is known and that the uncertainty is static, not dynamic. The presence of dynamic uncertainty has not been systematically addressed in the literature of ADP. By dynamic uncertainty, we refer to the mismatch between the nominal model (also referred to as the reduced-order system) and the real plant when the order of the nominal model is lower than the order of the real system. A closely related topic of research is how to account for the effect of unseen variables [60]. It is quite common that the full-state information is often missing in many engineering applications and only the output measurement or partial-state measurements are available. Adaptation of the existing ADP theory to this practical scenario is important yet non-trivial. Neural networks are sought for addressing the state estimation problem [12, 28]. However, the stability analysis of the estimator/controller augmented system is by no means easy, because the total system is highly interconnected and often strongly nonlinear. The configuration of a standard ADP-based control system is shown in Figure 1.2.
Figure 1.2 Illustration of the ADP scheme.
Our recent work [17, 19, 20, 21] on the development of robust ADP (for short, RADP) theory is exactly targeted at addressing these challenges.
1.1.4 What Is RADP?
RADP is developed to address the presence of dynamic uncertainty in linear and nonlinear dynamical systems. See Figure 1.3 for an illustration. There are several reasons for which we pursue a new framework for RADP. First and foremost, it is well known that building an exact mathema...
Table of contents
Cover
Series
Title Page
Copyright
Dedication
About the Authors
Preface and Acknowledgments
Acronyms
Glossary
Chapter 1: Introduction
Chapter 2: Adaptive Dynamic Programming for Uncertain Linear Systems
Chapter 4: Global Adaptive Dynamic Programming for Nonlinear Polynomial Systems
Chapter 5: Robust Adaptive Dynamic Programming
Chapter 6: Robust Adaptive Dynamic Programming for Large-Scale Systems
Chapter 7: Robust Adaptive Dynamic Programming as A Theory of Sensorimotor Control
Appendix A: Basic Concepts in Nonlinear Systems
Appendix B: Semidefinite Programming and Sum-of-Squares Programming
Appendix C: Proofs
Index
IEEE Press Series
EULA
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
Perlego offers two plans: Essential and Complete
Essential is ideal for learners and professionals who enjoy exploring a wide range of subjects. Access the Essential Library with 800,000+ trusted titles and best-sellers across business, personal growth, and the humanities. Includes unlimited reading time and Standard Read Aloud voice.
Complete: Perfect for advanced learners and researchers needing full, unrestricted access. Unlock 1.5M+ books across hundreds of subjects, including academic and specialized titles. The Complete Plan also includes advanced features like Premium Read Aloud and Research Assistant.
Both plans are available with monthly, semester, or annual billing cycles.
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go. Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Robust Adaptive Dynamic Programming by Yu Jiang,Zhong-Ping Jiang in PDF and/or ePUB format, as well as other popular books in Biological Sciences & System Theory. We have over 1.5 million books available in our catalogue for you to explore.