![]()
Chapter 1
Safety management anno 2016
Safety management has a brief but chequered history where the institutionalised concern for safety at places of work, in the sense of efforts to prevent harm to people, goes back about 200 years. The initial safety concerns focused on the harm and injuries that could befall people who were at work. This was understandable considering the nature of work, not least the nature of the relatively unsophisticated technology that was used. Seen from the perspective of industrial work in the second decade of the 21st century, the technology of the workplace in the 19th century was quite simple, not least because the level of automation was low. Work processes were also relatively independent of each other and would typically show the linear dependency of the assembly line. All this changed dramatically around the middle of the 20th century, not least because of the advent of new technologies and sciences: digital computers, telecommunication, cybernetics, and information theory. Technology became more powerful but also more complex, processes became more integrated and dependent on each other, customer demands to quality and reliability grew, and the pace of work increased relentlessly. Safety was no longer limited to the prevention of injuries to the people at work, but had to consider the possible hazards of the technology being used to customers, to innocent bystanders, and to society.
The development of many of the new technologies had been, to a large extent, driven by the needs of the military during WW-II and its continuation in the Cold War that followed. The precursor to industrial safety management systems (SMS) was the concern for system safety engineering that began in the 1950s in the U.S. Air Force Ballistic Missile Division. The increased complexity of the equipment created a need to ensure that technology would function as intended with optimum safety within the constraints of operational effectiveness. The same need could soon be found in the civilian sector where complex technologies were enthusiastically greeted as a way to provide better products and services to the consumer as well as higher profitability. Despite the many problems that this has led to, with regard to safety as well as other aspects, these needs have so far shown little sign of weakening.
SMSs started to appear around the beginning of the current millennium and a standard for SMS was arguably introduced by the International Civil Aviation Organisation (ICAO) and described as follows:
A safety management system (SMS) is an organized approach to managing safety, including the necessary organizational structures, accountabilities, policies and procedures. (ICAO, 2006)
ICAO’s SMS standard was, quite typically, motivated by a growing number of serious aviation accidents. In that sense, it was no different from the safety legislation in the 19th century or from practically every other effort or initiative to improve safety. Indeed, ICAO’s Safety Management Manual (page 2–1) defines safety as:
… the state in which the possibility of harm to persons or of property damage is reduced to, and maintained at or below, an acceptable level through a continuing process of hazard identification and risk management.
Across all industries and professions, safety is associated with being free from harm and therefore being without the consequences of failure, damage, accidents, or other nondesirable events. The purpose of safety management is consequently to ensure that the number of things that go wrong, i.e., the hazards, or the number of adverse outcomes is as low as possible – with zero harm as the ideal. However, as a growing number of industries and practitioners have realised, this is not enough in the world of today. Identification and elimination of hazards, and prevention of and protection against unwanted outcomes, is inadequate for nontrivial sociotechnical systems, as resilience engineering has pointed out. A state of safety must also include looking at the things that go well in order to find ways to support and facilitate them. This goes for the individuals at work as well as for the organisation and the overall SMS.
Managing what is not there
The two most serious problems with the common approach to safety relate to the way that safety is measured and to the way that safety is studied.
The measurement problem is simply that an increase in safety is represented by a decrease in what is measured. Thus, a lower number of reported accidents (or other unwanted outcomes) is seen as representing a higher level of safety. The purpose of safety management is continuously to reduce or eliminate adverse outcomes and thereby achieve the enviable state of ‘freedom from harm’. But it is only possible to know how well an SMS works if there is something to measure. Therefore, the better the job an SMS does the less information there is about how to make improvements. This corresponds to the well-known regulator paradox, where the absence of feedback ultimately leads to a loss of control (Weinberg and Weinberg, 1979). The essence of the paradox is that the task of a regulator is to eliminate variation but this variation is the ultimate source of information about how well the regulator works. Therefore, the better the job a regulator does the less information it gets about how to improve. Thus, if an investment in safety does not lead to measurable results, such as a reduction in the number of accidents, then there is no way of knowing whether the investment had the desired effect. Furthermore, if the number of accidents is low to begin with, it is unreasonable to expect that the effect of improvements made can ever be measured.
The problem of how safety is studied comes, in a way, from the very definition of safety as the (relative) absence of injury or harm (see also Chapter 8). Situations where such harm occurs are said to represent a lack of safety or to be due to the absence of safety. It is therefore nothing less than paradoxical that we try to improve our understanding of safety by studying situations where we acknowledge there is a lack of safety. Safety science thus differs from other sciences by trying to study its subject matter in situations where it is absent, rather than in situations where it is present. It is little wonder that progress has been so slow.
It is widely believed that safety management should pursue the ‘zero vision’ and that the level of risk should be As Low As Reasonably Practicable (ALARP). Although it makes intuitive sense to be free from incidents and accidents, it does not make much sense that the goal of safety management is to be without something. It stands to reason that it is difficult to manage something that is not there, that it is difficult to measure it, and that it is difficult to understand it. It is of limited comfort that safety is not alone in doing that. The same problem can be found in Statistical Process Control, in lean manufacturing, and in Total Quality Management.
Safety management: a focus on details
When we try to explain something, in particular events that in one way or another are surprising or unexpected, there is a strong preference for explanations that rely on single or monolithic causes. Having one rather than several causes for a problem makes it possible to consider each problem by itself and to solve one problem before moving on to the next.
The main assumption of this approach is whatever happens can be decomposed into parts and that each part can be addressed without considering the others. This is so, regardless of whether the problem is one that happened in the past – illustrated by the Root Cause Analysis of an accident or incident – or one that may appear in the future – illustrated by the Fault Tree. In the reactive case, such as accident investigations, the principle is visible in the way that each potential or possible cause is treated by itself, thus leading to (at least) as many solutions or steps to take as there are causes. A good example is provided by an Australian study of how to reduce harm in blood transfusions (VMIA, 2010). The study ended by making 40 different recommendations, distributed as follows: environment (3 recommendations), staff (9 recommendations), equipment (12 recommendations), patient (2 recommendations), procedure (6 recommendations), and culture (8 recommendations), thus nicely illustrating how we try to deal with unwieldy practical problems by simplifying them.
Managing safety by snapshots
An unintended, and usually overlooked, consequence of conventional safety management is that the basis is made up of snapshots of how an organisation functions – or rather, snapshots of how an organisation does not function, of how it fails, or has failed. The conventional wisdom is that accidents and incidents provide opportunities to learn and the basis for taking steps to make sure that the same or similar will not happen again. Indeed, one of the seminal works in safety is a book entitled Learning from Accidents in Industry (Kletz, 1994). Yet consider for a moment that accidents are events that occur infrequently and irregularly and lead to serious adverse outcomes. Accidents are therefore not typical of how an organisation performs; on the contrary, they represent unusual situations where an organisation has failed either in part or in whole. Yet safety management focuses on and analyses such situations in order to improve safety, following the ‘find-and-fix’ approach. Without being facetious, it would actually be more appropriate to call it the management of nonsafety.
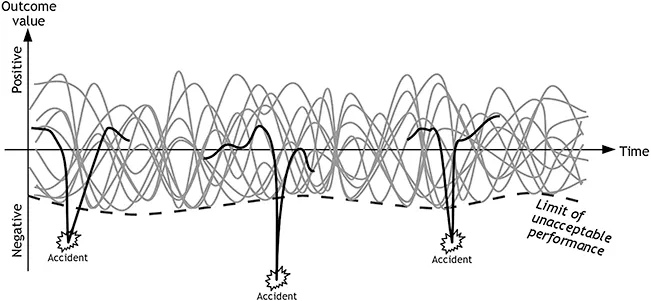
The principle of safety management based on analysing situations where something has gone wrong can be illustrated by Figure 1.1. The multiple grey traces or curves represent the multitude of ongoing processes or activities that typically take place. The purpose of safety management is to make sure that they do not go below the limit of safe performance, shown by a dotted line in Figure 1.1. (Other types of management, e.g., quality management, may try to limit the variability of the processes and keep them as close to a mean value as possible.) The limit of safe performance is not fixed, but depends on the current conditions, and is therefore in Figure 1.1 shown as an undulating curve rather than a horizontal line. The black curve fragments represent processes or developments that produce – or are assumed to produce – the unwanted outcomes. Unwanted outcomes do not occur very often, simply because a functioning organisation cannot afford that. If they occurred frequently, one of two things would happen: steps would be taken to make a change, or the organisation would cease to exist. Neither do unwanted outcomes happen regularly; indeed, when something goes wrong it is usually a surprise; it is unexpected. ‘Learning from accidents’ is therefore based on haphazard snapshots of situations where the organisation did not work, i.e., on snapshots of irregular anomalies. The fragmented black curves illustrate that we focus on what happened around the accident but not on the long-term developments. To make matters worse, these anomalies are further described in terms of individual ‘parts’ or structures that have failed, using linear cause-effect relations. It therefore does not seem to be the best basis for managing the safety of an organisation.
Managing safety by everyday work
Instead of basing safety management on the infrequent and irregular occurrences of adverse outcomes and assume that they are the result of orderly ‘mechanisms’ represented by the fragmented black curves, we should focus on the everyday processes that are represented by the multiple grey curves. These are shown in Figure 1.2, where the graphical rendering has been reversed so that the everyday processes in focus are shown in black while the accidents are shown in grey.
Acceptable outcomes differ crucially from unacceptable or harmful outcomes by being continuous and of course by being acceptable, i.e., above the limit of unacceptable performance. The general purpose of establishing and operating an organisation is indeed to ensure a way of functioning that delivers acceptable outcomes reliably and continuously. The focus of safety management, as well as of management in general, must therefore be the continuous performance or functioning instead of the exceptions, the rare events.
The focus of any kind of management should be on what happens regularly, rather than what happens rarely or not at all. A common argument for the current approach is that the accidents are what happens and that ‘nothing happens’ when there are no accidents. It is true that nothing spectacular or out of the ordinary happens in periods of calm and stable everyday performance. Nothing unusual happens, and nothing happens that automatically attracts attention. But it is a crucial mistake to claim that this means that nothing happens as such. On the contrary, an amazing number of things happen, but they go unnoticed precisely because they happen every day. They escape our attention because they are regular, routine, and habitual and because the outcomes are as expected. But it is precisely when ‘nothing’ happens that we are safe, in the sense of being without accidents; it is when ‘nothing’ happens that we are productive, in the sense of generating a sufficient number of output (products) per unit; it is when ‘nothing’ happens that we are efficient, in the sense of being able to produce with acceptable waste of time and effort; and it is when ‘nothing’ happens that we are able to produce with high quality, in the sense of having a small number of ‘rejects’.
Management of organisational performance in general and safety in particular should therefore be based on an understanding of the ‘nothing’ that happens all the time, on the typical, everyday processes, rather than on the snapshots of dysfunctional states. Safety management must in particular try to make sure that the typical, everyday processes go well or succeed as often as possible. We need to know and understand how things happen, and we need to be able to measure and assess them. This is what this book is about.
Safety-I and Safety-II
Around turn of the 20th century, ideas about resilience engineering started to spread from a small group of safety experts to the wider community of safety practitioners and academics. At that time, the main motivation was the concern about safety in nontrivial sociotechnical systems with safety defined as the ‘freedom from unacceptable harm’ or something similar. The development of resilience engineering was driven by the realisation that the established approaches to safety were ineffective and possibly even harmful and therefore a hindrance for progress (Haavik et al., 2016). Safety management was based on a strong belief that all adverse outcomes had identifiable causes and that these causes could be eliminated or neutralised once they had been found, as explained by the causality credo. Safety was defined generically as a condition where as few things as possible went wrong. It followed from this understanding that safety could be achieved by preventing things from going wrong, i.e., by looking at and responding to unwanted outcomes and the events that were assumed to lead to them. This understanding of safety is now called Safety-I (Hollnagel, 2014a).
Resilience engineering took a different approach. It started by disputing the tacit assumption that there was a value symmetry between effects and causes, in the sense that adverse outcomes were due to similarly adverse causes. Value symmetry expresses the belief that unacceptable outcomes have unacceptable causes and vice versa. An accident is thus seen as a consequence of something having gone wrong – a failure, a malfunction, or an error. It corresponds to our moral codex that good deeds are rewarded while bad deeds are punished. In this case, the ‘rewards’ and ‘punishments’ are the acceptable and unacceptable outcomes, respectively, while the deeds are the inferred causes. This view is also called the hypothesis of different causes, meaning that the causes of acceptable outcomes are different from the causes of unacceptable outcomes. Unacceptable outcomes are caused by failures, malfunctions, or errors while acceptable outcomes are ‘caused’ by correctly performing systems, in particular by correct human performance. Instead, resilience engineering argued that ‘failures were the flip side of successes’, or in other words that things that go right and things that go wrong happen in basically the...