Dieses Buch hat zum Ziel, die in der empirischen Forschung häufig verwendete Methode der multiplen linearen Regressionsanalyse in nachvollziehbarer Weise darzulegen. Als Hilfsmittel hierfür wird die schrittweise Entwicklung einer leistungsfähigen Software mit der weitverbreiteten Programmiersprache C unter Rückgriff auf Konzepte der parallelen Programmierung und des Cluster Computing herangezogen. Hierzu werden zunächst relevante mathematische Zusammenhänge aufgegriffen, die auch ohne größere Vorkenntnisse für den Leser nachvollziehbar sein sollten.Es werden Betrachtungen zur Effizienz von Algorithmen vorgenommen, welche für die Analyse von komplexen Modellen und von umfangreichen Datenmengen ("big data") unabdingbar sind. Im Buch wird anschaulich erläutert, wie die Berechnung eines komplexen Prognosemodells mit 20 Eingangsvariablen -abhängig von der konkreten Software-Implementation- entweder über 8000 Jahre oder unter 8 Minuten Rechenzeit benötigt. Beispielhaft werden mit der erstellten Analysesoftware empirische Daten einer vom Autor im Sommer 2014 durchgeführten psychologischen Feldstudie zur Burnout-Forschung an Beschäftigten im deutschen Gesundheitswesen untersucht.Das Buch integriert methodische Ansätze aus den Disziplinen Informatik und Psychologie und enthält 72 Tabellen, 67 Abbildungen sowie 45 Formeln.

eBook - ePub
Multiple lineare Regression & High Performance Computing
Methodik und Software-Implementation komplexer Analysemodelle
- 616 Seiten
- German
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
eBook - ePub
Multiple lineare Regression & High Performance Computing
Methodik und Software-Implementation komplexer Analysemodelle
Über dieses Buch
375,005 Studierende vertrauen auf uns
Zugang zu über 1,5 Millionen Titeln zu einem fairen monatlichen Preis.
Mit unseren Lerntools kannst du noch effizienter lernen.
Information
1. Über dieses Buch
für meine Frau Gesa
Dieses Buch hat zum Ziel, die in der empirischen Forschung häufig verwendete Methode der multiplen linearen Regressionsanalyse in nachvollziehbarer Weise darzulegen. Als Hilfsmittel hierfür wird die schrittweise Entwicklung einer performanten Software mit der weitverbreiteten Programmiersprache C unter Rückgriff auf Konzepte der parallelen Programmierung und des Cluster Computing herangezogen. Hierzu werden zunächst relevante mathematische Zusammenhänge aufgegriffen, die auch ohne größere Vorkenntnisse für den Leser nachvollziehbar sein sollten.
Es werden Betrachtungen zur Effizienz von Algorithmen vorgenommen, welche für die Analyse von komplexen Modellen und von umfangreichen Datenmengen („big data“) unabdingbar sind. Im Buch wird anschaulich erläutert, wie die Berechnung eines komplexen Prognosemodells mit 20 Eingangsvariablen -abhängig von der konkreten Software-Implementation- entweder über 8000 Jahre oder unter 8 Minuten Rechenzeit benötigt. Beispielhaft werden mit der erstellten Analysesoftware empirische Daten einer vom Autor im Sommer 2014 durchgeführten psychologischen Feldstudie zur Burnout-Forschung an Beschäftigten im deutschen Gesundheitswesen untersucht.
Das Buch integriert methodische Ansätze aus den Disziplinen Informatik und Psychologie und enthält 72 Tabellen, 67 Abbildungen sowie 45 Formeln.
Anmerkungen zur 5.Auflage
Zur weiteren Laufzeitoptimierung wurde eine zusätzliche Parallelisierung der Hauptregressionsanalyse auf im Cluster verfügbare Computer mit Mehrkernprozessoren umgesetzt (Kap. 5.14). Mit dem zusätzlich vorgenommenen Experiment 9 konnten nunmehr weitere Performanzgewinne von zusätzlich 35% nachgewiesen werden. Dabei wurde z.B. die Berechnung eines komplexen Regressionsmodells mit 20 Prädiktoren in einer Durchlaufzeit von weniger als acht Minuten auf einer experimentellen Clusterumgebung mit 16 verfügbaren Prozessorkernen abgeschlossen. Diese Performanzgewinne ermöglichten die Simulation hochkompexer Regressionsmodelle mit 24 Prädiktoren mit einer Durchlaufzeit von weniger als neun Stunden. In methodischer Hinsicht erfolgte im Kap. 4.4 eine Berücksichtigung der Modelldiagnose von Residuen und Mahalonobis-Distanzen. Anhand eines konkreten Beispiels wurden die Auswirkungen von Ausreißern und einflussreicher Datenpunkte auf die Parameterschätzungen und die Modellpassung einer Regressionsanalyse veranschaulicht. Im Kap. 4.5 wurde das Bootstrapping-Verfahren anhand eines nachvollziehbaren Beispiels eingearbeitet und die Grundlage zur späteren Anwendung dieser Technik in der multiplen linearen Regression gelegt.
Zudem wurde im Kap. 5.16 eine vergleichende Betrachtung zwischen verschiedenen C-Compilern und deren Auswirkungen auf die Performance der Software eingearbeitet und experimentell nachvollzogen.
Dätgen, im April 2015
Anmerkungen zur 4.Auflage
Als weitere Ergänzung wurde das Konzept des Cluster Computing im Kap. 5.14 berücksichtigt. Die vorgestellte Software-Lösung wurde um ein simples Protokoll zur Rechnerkommunikation im Cluster in Kombination mit paralleler Ausführung auf beteiligten Mehrkern-Prozessoren erweitert. Im Zuge dessen wird auch die Lastverteilungs-Problematik näher diskutiert.
Anmerkungen zur 3.Auflage
Mit der 3.Auflage erfolgte eine weitere Optimierung der Software zur effizienten Berechnung komplexer Regressionsmodelle und damit einhergehend eine Erweiterung des Kapitels 5.9. Zudem wurde in Kap.0 ein weiterer Hypothesentest der zugrundeliegenden Studie aufgenommen. Im Anhang A-8 wurde zusätzlich eine um eine simple Dateiverwaltung erweiterte Softwareversion aufgenommen, welche eine wiederholte Eingabe von Messdaten überflüssig macht.
Anmerkungen zur 2.Auflage
In der 2.Auflage erfolgte eine Überarbeitung von Kap. 2.4 mit genaueren Erläuterungen zur linearen Transformation von Matrizen. Zudem wurde das Kap. 5.10 und der Anhang A-6 mit optimierten Programmroutinen zur linearen Transformation von Matrizen und zur Berechnung von Determinanten aktualisiert. Der Abschnitt zur praktischen Anwendung der multiplen linearen Regression (Kap.0) wurde um die Prüfung einer weiteren Hypothese aus der zugrundeliegenden Studie ergänzt.
2. Ausgewählte mathematische Grundlagen
Mit korrelativen Analysen können lediglich ungerichtete Zusammenhänge zwischen Merkmalen untersucht werden. Sachlogische Überlegungen können jedoch häufig eine Richtung der Beeinflussung nahelegen (Fahrmeir, Künstler, Pigeot & Tutz, 2007, S. 153). In der Regressionsanalyse muß entschieden werden, welche Variablen (die sog. Prädiktoren, meist mit Xi bezeichnet) welche Variable (das sog. Kriterium, meist mit Y bezeichnet) vorhersagen sollen (Sedlmeier & Renkewitz, 2013, S.237).
Für die lineare Regressionsanalyse sind ausgewählte mathematische Grundlagen von Bedeutung. Aus der deskriptiven Statistik werden sowohl univariate Maße (auf ein Merkmal bezogen), bivariate Maße (auf zwei Merkmale bezogen), als auch multivariate Maße (auf mehr als zwei Merkmale bezogen) benötigt.
2.1. Univariate Maße
Das arithmetische Mittel aus n vorliegenden Messwerten xi (der sog. Urliste) ist in Formel 1 für metrische Merkmale definiert (Fahrmeir et al., 2007, S. 53-54). Bedeutsam für die lineare Regression ist die Schwerpunkteigenschaft des arithmetischen Mittels, d.h. alle Abweichungen der einzelnen Messwerte von ihrem gemeinsamen Mittelwert heben sich zu Null auf (vgl. hierzu die Formel 2).
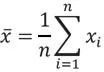
Formel 1: Arithmetisches Mittel
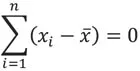
Formel 2: Schwerpunkteigenschaft des arithmetischen Mittels
Beispiel. Messreihe zum chronischen Stress von zehn Probanden.
Tabelle 1 Das arithmetische Mittel zu realen Messdaten
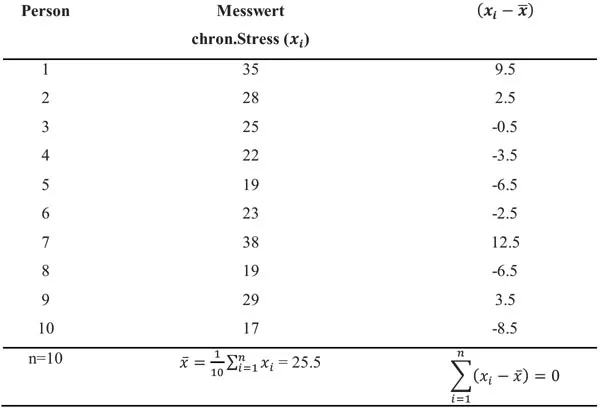
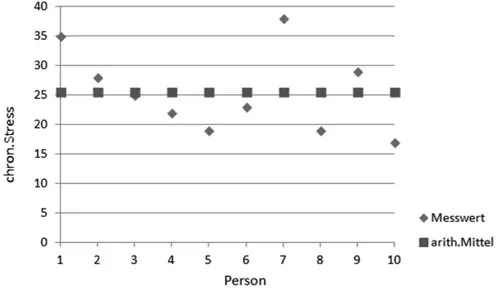
Abbildung 1: Messreihe zum chronischen Stress.
Tabelle 1 und Abbildung 1 demonstrieren anschaulich die Schwerpunkteigenschaft des arithmetischen Mittels. Die Messwerte einzelner Personen weichen mehr oder weniger vom aus allen Personen errechneten Mittelwert ab. Dabei heben sich die Über- und Unterschreitungen der Einzelpersonen vom Mittelwert zu Null auf.
Eine weitere, für die lineare Regression bedeutsame univariate Kenngröße ist die Streuung der Messwerte eines Merkmals, die empirische Varianz. Sie steht im Zusammenhang mit dem arithmetischen Mittel und ist nur für metrische Merkmale sinnvoll einsetzbar (Fahrmeir et al., 2007, Kap. 2.2.3). Es ist wichtig festzuhalten, daß die empirische Varianz (Formel 3) aus der mittleren quadrierte...
Inhaltsverzeichnis
- Über den Autor
- Inhaltsverzeichnis
- Abkürzungsverzeichnis
- Tabellenverzeichnis
- Abbildungsverzeichnis
- Formelverzeichnis
- 1. Über dieses Buch
- 2. Ausgewählte mathematische Grundlagen
- 3. Das einfache lineare Regressionsmodell
- 4. Das multiple lineare Regressionsmodell
- 5. Software-Implementation
- 6. Ein praktischer Anwendungsfall
- Literaturverzeichnis
- Anhang
- Impressum
Häufig gestellte Fragen
Ja, du kannst dein Abo jederzeit über den Tab Abo in deinen Kontoeinstellungen auf der Perlego-Website kündigen. Dein Abo bleibt bis zum Ende deines aktuellen Abrechnungszeitraums aktiv. Erfahre, wie du dein Abo kündigen kannst
Nein, Bücher können nicht als externe Dateien, z. B. PDFs, zur Verwendung außerhalb von Perlego heruntergeladen werden. Du kannst jedoch Bücher in der Perlego-App herunterladen, um sie offline auf deinem Smartphone oder Tablet zu lesen. Erfahre, wie du Bücher herunterladen kannst, um sie offline zu lesen
Perlego bietet zwei Pläne an: Essential und Complete
- Essential ist ideal für Lernende und Fachkräfte, die es genießen, eine Vielzahl von Themen zu erkunden. Greife auf die Essential Library mit über 800.000 vertrauenswürdigen Titeln und Bestsellern in den Bereichen Wirtschaft, persönliche Weiterentwicklung und Geisteswissenschaften zu. Enthält unbegrenzte Lesezeit und Standard-Vorlesestimme.
- Complete: Perfekt für fortgeschrittene Lernende und Forschende, die vollen, uneingeschränkten Zugriff benötigen. Entsperre über 1,5 Millionen Bücher zu Hunderten von Themen, einschließlich akademischen und spezialisierten Titeln. Der Complete-Plan enthält außerdem fortschrittliche Funktionen wie Premium Vorlesen und Forschungsassistent.
Wir sind ein Online-Lehrbuch-Abonnement-Service, bei dem du für weniger als den Preis eines einzelnen Buchs pro Monat Zugriff auf eine gesamte Online-Bibliothek erhältst. Bei über 1,5 Millionen Büchern zu mehr als 990 Themen bist du bestens versorgt! Erfahre mehr über unsere Mission
Achte auf das Symbol zum Vorlesen bei deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Erfahre mehr über die Funktion „Vorlesen“
Ja! Du kannst die Perlego-App sowohl auf iOS- als auch auf Android-Geräten nutzen, damit du jederzeit und überall lesen kannst – sogar offline. Perfekt für den Weg zur Arbeit oder wenn du unterwegs bist.
Bitte beachte, dass wir Geräte, auf denen die Betriebssysteme iOS 13 und Android 7 oder noch ältere Versionen ausgeführt werden, nicht unterstützen können. Mehr über die Verwendung der App erfahren
Bitte beachte, dass wir Geräte, auf denen die Betriebssysteme iOS 13 und Android 7 oder noch ältere Versionen ausgeführt werden, nicht unterstützen können. Mehr über die Verwendung der App erfahren
Ja, du kannst auf Multiple lineare Regression & High Performance Computing von Thomas Kaul im PDF- und/oder ePUB-Format sowie auf andere beliebte Bücher in Informatik & Informationstechnologie zugreifen. In unserem Katalog stehen über 1,5 Millionen Bücher zur Verfügung.