
eBook - ePub
Data Mining: Concepts and Techniques
Jiawei Han, Micheline Kamber, Jian Pei
This is a test
Buch teilen
- 744 Seiten
- English
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
eBook - ePub
Data Mining: Concepts and Techniques
Jiawei Han, Micheline Kamber, Jian Pei
Angaben zum Buch
Buchvorschau
Inhaltsverzeichnis
Quellenangaben
Über dieses Buch
Data Mining: Concepts and Techniques provides the concepts and techniques in processing gathered data or information, which will be used in various applications. Specifically, it explains data mining and the tools used in discovering knowledge from the collected data. This book is referred as the knowledge discovery from data (KDD). It focuses on the feasibility, usefulness, effectiveness, and scalability of techniques of large data sets. After describing data mining, this edition explains the methods of knowing, preprocessing, processing, and warehousing data. It then presents information about data warehouses, online analytical processing (OLAP), and data cube technology. Then, the methods involved in mining frequent patterns, associations, and correlations for large data sets are described. The book details the methods for data classification and introduces the concepts and methods for data clustering. The remaining chapters discuss the outlier detection and the trends, applications, and research frontiers in data mining.
This book is intended for Computer Science students, application developers, business professionals, and researchers who seek information on data mining.
- Presents dozens of algorithms and implementation examples, all in pseudo-code and suitable for use in real-world, large-scale data mining projects
- Addresses advanced topics such as mining object-relational databases, spatial databases, multimedia databases, time-series databases, text databases, the World Wide Web, and applications in several fields
- Provides a comprehensive, practical look at the concepts and techniques you need to get the most out of your data
Häufig gestellte Fragen
Wie kann ich mein Abo kündigen?
Gehe einfach zum Kontobereich in den Einstellungen und klicke auf „Abo kündigen“ – ganz einfach. Nachdem du gekündigt hast, bleibt deine Mitgliedschaft für den verbleibenden Abozeitraum, den du bereits bezahlt hast, aktiv. Mehr Informationen hier.
(Wie) Kann ich Bücher herunterladen?
Derzeit stehen all unsere auf Mobilgeräte reagierenden ePub-Bücher zum Download über die App zur Verfügung. Die meisten unserer PDFs stehen ebenfalls zum Download bereit; wir arbeiten daran, auch die übrigen PDFs zum Download anzubieten, bei denen dies aktuell noch nicht möglich ist. Weitere Informationen hier.
Welcher Unterschied besteht bei den Preisen zwischen den Aboplänen?
Mit beiden Aboplänen erhältst du vollen Zugang zur Bibliothek und allen Funktionen von Perlego. Die einzigen Unterschiede bestehen im Preis und dem Abozeitraum: Mit dem Jahresabo sparst du auf 12 Monate gerechnet im Vergleich zum Monatsabo rund 30 %.
Was ist Perlego?
Wir sind ein Online-Abodienst für Lehrbücher, bei dem du für weniger als den Preis eines einzelnen Buches pro Monat Zugang zu einer ganzen Online-Bibliothek erhältst. Mit über 1 Million Büchern zu über 1.000 verschiedenen Themen haben wir bestimmt alles, was du brauchst! Weitere Informationen hier.
Unterstützt Perlego Text-zu-Sprache?
Achte auf das Symbol zum Vorlesen in deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Weitere Informationen hier.
Ist Data Mining: Concepts and Techniques als Online-PDF/ePub verfügbar?
Ja, du hast Zugang zu Data Mining: Concepts and Techniques von Jiawei Han, Micheline Kamber, Jian Pei im PDF- und/oder ePub-Format sowie zu anderen beliebten Büchern aus Informatik & Datenbanken. Aus unserem Katalog stehen dir über 1 Million Bücher zur Verfügung.
Information
1
Introduction
Publisher Summary
This chapter introduces the book which deals with data mining (also known as knowledge discovery from data, or KDD). Data mining is the process of discovering interesting patterns from massive amounts of data. As a knowledge discovery process, it typically involves data cleaning, data integration, data selection, data transformation, pattern discovery, pattern evaluation, and knowledge presentation. The major dimensions of data mining are data, knowledge, technologies, and applications. The book focuses on fundamental data mining concepts and techniques for discovering interesting patterns from data in various applications. Prominent techniques for developing effective, efficient, and scalable data mining tools are focused on. This chapter discusses why data mining is in high demand and how it is part of the natural evolution of information technology. It defines data mining with respect to the knowledge discovery process. Next, data mining from many aspects, such as the kinds of data that can be mined, the kinds of knowledge to be mined, the kinds of technologies to be used and targeted applications are discussed which helps gain a multidimensional view of data mining. Data mining can be conducted on any kind of data as long as the data are meaningful for a target application, such as database data, data warehouse data, transactional data, and advanced data types. Finally major data mining research and development issues are outlined.
This book is an introduction to the young and fast-growing field of data mining (also known as knowledge discovery from data, or KDD for short). The book focuses on fundamental data mining concepts and techniques for discovering interesting patterns from data in various applications. In particular, we emphasize prominent techniques for developing effective, efficient, and scalable data mining tools.
This chapter is organized as follows. In Section 1.1, you will learn why data mining is in high demand and how it is part of the natural evolution of information technology. Section 1.2 defines data mining with respect to the knowledge discovery process. Next, you will learn about data mining from many aspects, such as the kinds of data that can be mined (Section 1.3), the kinds of knowledge to be mined (Section 1.4), the kinds of technologies to be used (Section 1.5), and targeted applications (Section 1.6). In this way, you will gain a multidimensional view of data mining. Finally, Section 1.7 outlines major data mining research and development issues.
1.1 Why Data Mining?
Necessity, who is the mother of invention. – Plato
We live in a world where vast amounts of data are collected daily. Analyzing such data is an important need. Section 1.1.1 looks at how data mining can meet this need by providing tools to discover knowledge from data. In Section 1.1.2, we observe how data mining can be viewed as a result of the natural evolution of information technology.
1.1.1 Moving toward the Information Age
“We are living in the information age” is a popular saying; however, we are actually living in the data age. Terabytes or petabytes1 of data pour into our computer networks, the World Wide Web (WWW), and various data storage devices every day from business, society, science and engineering, medicine, and almost every other aspect of daily life. This explosive growth of available data volume is a result of the computerization of our society and the fast development of powerful data collection and storage tools. Businesses worldwide generate gigantic data sets, including sales transactions, stock trading records, product descriptions, sales promotions, company profiles and performance, and customer feedback. For example, large stores, such as Wal-Mart, handle hundreds of millions of transactions per week at thousands of branches around the world. Scientific and engineering practices generate high orders of petabytes of data in a continuous manner, from remote sensing, process measuring, scientific experiments, system performance, engineering observations, and environment surveillance.
Global backbone telecommunication networks carry tens of petabytes of data traffic every day. The medical and health industry generates tremendous amounts of data from medical records, patient monitoring, and medical imaging. Billions of Web searches supported by search engines process tens of petabytes of data daily. Communities and social media have become increasingly important data sources, producing digital pictures and videos, blogs, Web communities, and various kinds of social networks. The list of sources that generate huge amounts of data is endless.
This explosively growing, widely available, and gigantic body of data makes our time truly the data age. Powerful and versatile tools are badly needed to automatically uncover valuable information from the tremendous amounts of data and to transform such data into organized knowledge. This necessity has led to the birth of data mining. The field is young, dynamic, and promising. Data mining has and will continue to make great strides in our journey from the data age toward the coming information age.
1.1.2 Data Mining as the Evolution of Information Technology
Data mining can be viewed as a result of the natural evolution of information technology. The database and data management industry evolved in the development of several critical functionalities (Figure 1.1): data collection and database creation, data management (including data storage and retrieval and database transaction processing), and advanced data analysis (involving data warehousing and data mining). The early development of data collection and database creation mechanisms served as a prerequisite for the later development of effective mechanisms for data storage and retrieval, as well as query and transaction processing. Nowadays numerous database systems offer query and transaction processing as common practice. Advanced data analysis has naturally become the next step.
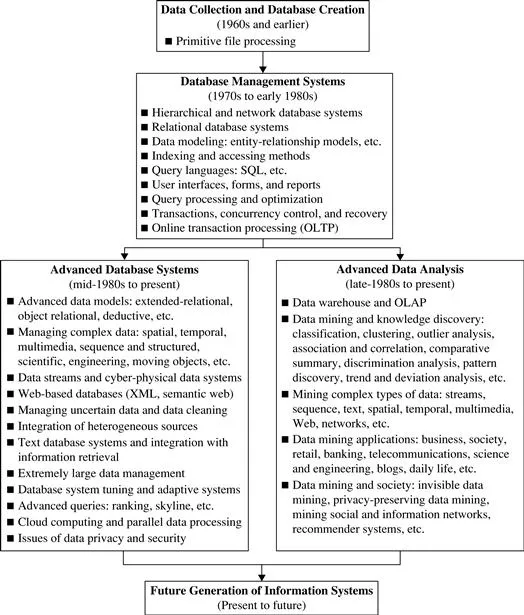
Figure 1.1 The evolution of database system technology.
Since the 1960s, database and information technology has evolved systematically from primitive file processing systems to sophisticated and powerful database systems. The research and development in database systems since the 1970s progressed from early hierarchical and network database systems to relational database systems (where data are stored in relational table structures; see Section 1.3.1), data modeling tools, and indexing and accessing methods. In addition, users gained convenient and flexible data access through query languages, user interfaces, query optimization, and transaction management. Efficient methods for online transaction processing (OLTP), where a query is viewed as a read-only transaction, contributed substantially to the evolution and wide acceptance of relational technology as a major tool for efficient storage, retrieval, and management of large amounts of data.
After the establishment of database management systems, database technology moved toward the development of advanced database systems, data warehousing, and data mining for advanced data analysis and web-based databases. Advanced database systems, for example, resulted from an upsurge of research from the mid-1980s onward. These systems incorporate new and powerful data models such as extended-relational, object-oriented, object-relational, and deductive models. Application-oriented database systems have flourished, including spatial, temporal, multimedia, active, stream and sensor, scientific and engineering databases, knowledge bases, and office information bases. Issues related to the distribution, diversification, and sharing of data have been studied extensively.
Advanced data analysis sprang up from the late 1980s onward. The steady and dazzling progress of computer hardware technology in the past three decades led to large supplies of powerful and affordable computers, data collection equipment, and storage media. This technology provides a great boost to the database and information industry, and it enables a huge number of databases and information repositories to be available for transaction management, information retrieval, and data analysis. Data can now be stored in many different kinds of databases and information repositories.
One emerging data repository architecture is the data warehouse (Section 1.3.2). This is a repository of multiple heterogeneous data sources organized under a unified schema at a single site to facilitate management decision making. Data warehouse technology includes data cleaning, data integration, and online analytical processing (OLAP)—that is, analysis techniques with functionalities such as summarization, consolidation, and aggregation, as well as the ability to view information from different angles. Although OLAP tools support multidimensional analysis and decision making, additional data analysis tools are required for in-depth analysis—for example, data mining tools that provide data classification, clustering, outl...