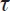![]()
PARTE III
ESTUDIOS NO EXPERIMENTALES
¿Bajo qué condiciones podemos usar el grupo de control,
E[
Yi(0)|
Di = 0], como una aproximación adecuada del valor esperado de la variable de resultado entre los participantes en ausencia del programa,
E[
Yi(0)|
Di = 0], al estimar
ATT? En estudios no experimentales o cuasi experimentales en los cuales los datos disponibles no provienen de una asignación aleatoria al programa, se requiere de ciertos supuestos de identificación que nos permitan solucionar el sesgo de autoselección. En esta parte del libro, se discuten varias metodologías que implementan diversas correcciones bajo conjuntos diferentes de supuestos.
Los métodos estudiados en esta parte del libro son el de emparejamiento (propensity score matching), variables instrumentales, regresión discontinua, funciones de control, modelos estructurales y análisis de intensidad. La pertinencia de cada uno de ellos depende de la calidad de los datos y de las características de los programas a evaluar.
La estimación de impacto a través de los métodos de mínimos cuadrados ordinarios y de emparejamiento se basa en el supuesto de que la selección se da únicamente en variables observables. Por tanto, controlan únicamente por el sesgo en esta dimensión. Otros métodos proveen fuentes de variación exógena del tratamiento que pueden ser explotadas para estimar el efecto del tratamiento bajo supuestos relativamente débiles, controlando tanto por sesgo de selección en variables observables como en no observables o no disponibles. Los métodos de variables instrumentales y variables de control corrigen por selección en variables no observables (o no disponibles en la base de datos) al explotar la variación exógena generada por un instrumento excluido. El método de regresión discontinua es un caso especial de una fuente de variación exógena del tratamiento, que se puede aplicar cuando la probabilidad de participación en el tratamiento cambia discontinuamente con una variable continua observada.
Otra posibilidad para evaluar el efecto de políticas económicas es utilizar modelos de comportamiento económicos explícitos, en vez de estimar las formas reducidas de dichos modelos. El método de la estimación de modelos estructurales asume que los individuos toman decisiones con base en modelos de optimización explícitos y estima los parámetros estructurales de dichos modelos. Con éstos se puede simular, en principio, cualquier cambio en el ambiente económico que enfrenta el individuo, por lo cual se pueden evaluar tanto los programas existentes, como variaciones de éstos o incluso programas hipotéticos.
Ninguna metodología es una “bala de plata”; cada método tiene ventajas y desventajas. Por ejemplo, la selección de un instrumento apropiado en los métodos de variables instrumentales y funciones de control, tanto como la selección del conjunto de variables observables sobre las cuales condicionar la estimación en los métodos de mínimos cuadrados ordinarios o emparejamiento, se basan en una decisión a priori difícil de validar. La identificación en la estimación de modelos estructurales requiere supuestos explícitos acerca de las formas funcionales (por ejemplo, de las funciones de utilidad) y acerca de las distribuciones paramétricas de los términos de error. En general, no resulta fácil demostrar que el modelo escogido es plausible y que por tanto, es válido utilizarlo para simular las decisiones de los agentes bajo estudio.
![]()
6
EL MÈTODO DE EMPAREJAMIENTO
Una posible estrategia de identificación es asumir que, dado un conjunto de variables observables X que no están determinadas por el tratamiento (o programa), los resultados potenciales, Yi(0) y Yi(1), son independientes de la asignación al tratamiento (o programa). Este supuesto implica que todas estas variables que afectan simultáneamente la asignación al tratamiento y los resultados potenciales (Yi) son observadas por el investigador e incluidas en el modelo que se estima.
Suponga que queremos estimar el impacto de la intervención comparando las variables de resultado del grupo de tratamiento y del grupo de control:
Los primeros dos términos son el efecto promedio sobre los tratados (average treatment on the treated), tATT = E[Yi(1)|Di = 1] – E[Yi(0)|Di = 1], pues identifican el efecto del programa sobre el grupo de tratamiento menos lo que habría sido la situación del grupo de tratados si no hubieran participado en el programa. Los dos últimos términos miden el sesgo de selección: la diferencia entre el contrafactual y la variable de resultado para el grupo de control.
Es decir, el impacto, estimado como la diferencia en el promedio de las variables de resultado del grupo de tratamiento y del grupo de control, estará compuesto por el efecto verdadero del programa y el sesgo de selección. ¿Cómo separar estos dos componentes? Una posibilidad es asumir que el sesgo de selección se debe únicamente a diferencias en características observables.
Formalmente, si la selección en el programa se basa únicamente en características observables, se establece que
y se denomina la condición de independencia condicional (CI).
Lo que este supuesto hace es asegurar que al condicionar en las variables observables X, E(Yi(0)|Di = 1,X) = E(Yi(0)|Di = 0, X) y, por tanto, que el sesgo de selección es igual a cero. Así, calcular el impacto del programa como la diferencia en el promedio de las variables de resultado del grupo de tratamiento y del grupo de control, condicionando en las variables observadas, genera una estimación insesgada del efecto verdadero del programa.
Vale la pena recalcar que el supuesto CI implica que la participación en el programa no está determinada por variables no observadas (o no medidas) que también determinen las variables de resultados potenciales (Yi). Esto excluiría casos en los cuales la decisión de participación en el programa está influenciada por variables no observables o no disponibles en la base de datos, como la habilidad cognitiva innata de los participantes o, en el caso del programa Canasta, la dedicación de la madre a la crianza de sus niños, la mayoría de las cuales no sólo no están contenidas en las encuestas sino que serían muy difíciles de medir, aun si se tuviera esa intención. Por esta razón, el supuesto de CI se considera como fuerte y su incumplimiento puede inducir sesgos en el estimador por emparejamiento.
La versión más sencilla de esta metodología consiste en encontrar un “clon” de cada individuo tratado en el grupo de control y contrastar las variables de resultado de ambos. Donde clon quiere decir un individuo (o grupo de individuos) con exactamente las mismas características observables X, por ejemplo, ingreso, educación, edad, sexo, o cualquier variable que sea pertinente para el programa bajo estudio. Para el caso de Canasta, querríamos emparejar niños según características como edad, sexo, nivel de pobreza, número de hijos en el hogar, nivel educativo del padre y de la madre, entre otras. En general, la metodología se puede entender como una manera de ponderar las observaciones del grupo de control para que la distribución de características observables X sea lo más parecida posible a la del grupo de tratamiento.
Note que la implementación del estimador puede resultar computacionalmente compleja si hay un gran número de variables con base en las cuales estamos emparejando, es decir, si el vector X tiene una dimensión muy grande (la maldición de la dimensionalidad). Una posibilidad, cuando la dimensión de X no es muy grande, es comparar la diferencia en la variable de resultados para cada celda conformada por todos los posibles valores de X.
El efecto del programa es entonces el promedio ponderado de los efectos en cada celda. Este emparejamiento no paramétrico no es práctico si X es de dimensión grande. Cuando el vector X contiene muchas variables, en vez de emparejar con base en un vector de características observadas X, se puede emparejar individuos con base en su probabilidad estimada de participación en el programa, dadas sus características observables P(X), donde
Es decir, el clon adecuado para cada individuo del grupo de tratamiento será aquel del grupo de control con una probabilidad de participación en el programa suficientemente cercana. Todos los estimadores por emparejamiento contrastan la variable de resultado de un individuo tratado con los resultados de uno o más miembros del grupo de control que más se parezcan al individuo tratado, con base en la medida P(X).
La ventaja de emparejar a partir de P(X), a diferencia de X, es que P(X) es un escalar, mientras que X puede tener una dimensión muy grande. Rosenbaum y Rubin (1983) mostraron que si emparejar con base en X genera estimadores consistentes, entonces emparejar con base en P(X) también producirá estimadores consistentes del efecto del programa. La función P(X) se conoce con el nombre de propensity score o probabilidad de participación.
Para construir un buen grupo de control es necesario que cualquier combinación de características observadas en el grupo de tratamiento exista también en el grupo de control. Las variables observables de un individuo están resumidas en su probabilidad de participación P(X). Por tanto, un individuo será un control adecuado de un beneficiario del programa si el primero tiene una probabilidad de participar en el programa muy parecida a la del segundo. Esto implica que el método de emparejamiento (propensity score matching, PSM) sólo se puede calcular en la región de soporte común,41 para asegurar que los grupos de tratamiento y control sean muy parecidos.
La condición de soporte común (SC) establece que individuos con el mismo vector de variables X tienen probabilidad positiva de ser tanto participantes como no participantes en el programa. Es decir, no se pueden utilizar individuos con combinaciones de X tales que exhiben probabilidades positivas de ser participantes pero nulas de ser no participantes (o viceversa). Formalmente, la condición de SC implica que:
Si esta condición no se cumple, se podría predecir perfectamente la participación en el programa, es decir, sería posible encontrar una combinación particular de características que predice perfectamente la participación en el programa y, por tanto, no existiría un individuo que fuera un buen control, en el sentido de tener una probabilidad de participación muy parecida.
La condición de SC implica que sólo se utilizan en la estimación individuos del grupo de control que tengan probabilidades de participación P(X) similares a las probabilidades de participación del grupo de tratamiento. Por ejemplo, si existen individuos del grupo de control con probabilidades de participación bajísimas, pero ningún individuo tratado exhibe una probabilidad de participación t...