![]()
| 1 | Genetic mutations and biomarkers |
Basic principles in cell biology
The human body is constituted of trillions of cells, the fundamental building blocks of all living organisms. Cells provide structure for the body, take in nutrients from food, convert those nutrients into energy and carry out specific functions. The nucleus functions as the cell’s control center, sending instructions to the cell to grow, mature, divide or die (apoptosis).
DNA is the body’s hereditary material – it can be duplicated during the process of cell division. Most of the cellular DNA is packaged into thread-like structures called chromosomes, which are found in the nucleus. Humans have 23 pairs of chromosomes, giving a total of 46 chromosomes. Each chromosome is made up of DNA tightly coiled many times around proteins called histones that support its structure (Figure 1.1). At each end of a chromosome there is a telomere, a region of repetitive nucleotide sequences. Telomeres protect the end of the chromosome from deterioration or fusion with neighboring chromosomes.
Figure 1.1 The DNA molecules are wrapped around complexes of histone proteins and ‘packed’ into the chromosomes. Telomeres at the ends of the chromosome comprise long stretches of repeated TTAGGG sequences, which help stabilize the chromosomes.
A small amount of DNA can be found in the mitochondria – this is referred to as mitochondrial DNA (mtDNA) (see later).
DNA bases. The information in DNA is stored as a code made up of four chemical bases: adenine (A), guanine (G), cytosine (C) and thymine (T). Human DNA comprises about 3 billion bases. It is essential to appreciate that more than 99% of those bases are the same in all people. The sequence of these bases controls the information available for building, developing and preserving the body.
Nucleotides and DNA structure. DNA bases pair up with each other, A with T and C with G, to form a unit called a base pair (bp). Each base is also attached to a sugar molecule and a phosphate molecule. Together, a base, sugar and phosphate are called a nucleotide. Nucleotides are arranged in two long strands that form a double helix (Figure 1.2). Although the circumstances of the discovery of DNA structure in the 1950s are fairly well known, they are usefully summarized in a 2019 article on Watson and Crick’s original paper in Nature.1
Figure 1.2 (a) Double-stranded DNA forms a double helix. The two strands are joined by hydrogen bonds between the bases. The sugar–phosphate backbones run in opposite directions, so a 3' end on one strand aligns with a 5' end on the other strand. (b) A ball-and-stick model of a single base (adenine in this figure) with part of the helix backbone. Gray, carbon; white, hydrogen; blue, nitrogen; red, oxygen; and orange, phosphate.
An essential property of DNA is that it replicates, or makes copies of itself. Each strand of DNA in the double helix can serve as a pattern for duplicating the sequence of bases. This process is vital during cell division because each new cell must have an exact copy of the DNA present in the mother cell.
A codon is a sequence of three DNA or RNA nucleotides that matches a specific amino acid or stop signal during protein synthesis. DNA and RNA molecules are written in a language of four nucleotides; meanwhile, the language of proteins includes 20 amino acids. Codons provide the key that permits these two languages to be translated into each other. Each codon corresponds to a single amino acid (or stop signal), and the full set of codons is called the genetic code.
A gene is a sequence of nucleotides in DNA or RNA that encodes the creation of a gene product, either RNA or protein. Genes are built up of DNA. Some genes act as instructions to make proteins. However, many genes do not code for proteins. In humans, genes can differ in size ranging from a few hundred DNA bases to more than 2 million bases. The Human Genome Project calculated that humans have between 20 000 and 25 000 genes. In most genes, coding regions (exons) are interrupted by non-coding regions (introns) (Figure 1.3).
Figure 1.3 A gene comprises exons, which are expressed, and introns, which are spliced from the RNA. UTR, untranslated region.
An intron is any nucleotide sequence within a gene that is removed by RNA splicing during the maturation of the final RNA product. Introns are non-coding regions of an RNA transcript that are eliminated by splicing before translation.
An exon is any part of a gene that will encode a part of the final mature RNA produced by that gene after the introns have been removed by RNA splicing. The term exon refers to both the DNA sequence within a gene and the corresponding sequence in an RNA transcript. In RNA splicing, introns are removed and exons are covalently joined to generate the mature messenger RNA (mRNA).
All exons constitute the exome – the sequences which, when transcribed, remain within the mature RNA after introns are removed by RNA splicing.
Gene expression is the process by which information from a gene is utilized to synthesize a functional gene product. These products are often proteins, but for non-protein-coding genes such as transfer RNA (tRNA) or small nuclear RNA (snRNA) genes, the product is a functional RNA.
During transcription, the whole gene is copied into a pre-mRNA, which includes exons and introns. During the process of RNA splicing, introns are removed and exons linked to form a contiguous coding sequence.
Non-coding DNA. Only about 1% of DNA is made up of protein-coding genes; the other 99% is non-coding. Although non-coding DNA does not provide instructions for making proteins, it is essential to the function of cells, particularly the control of gene activity.2
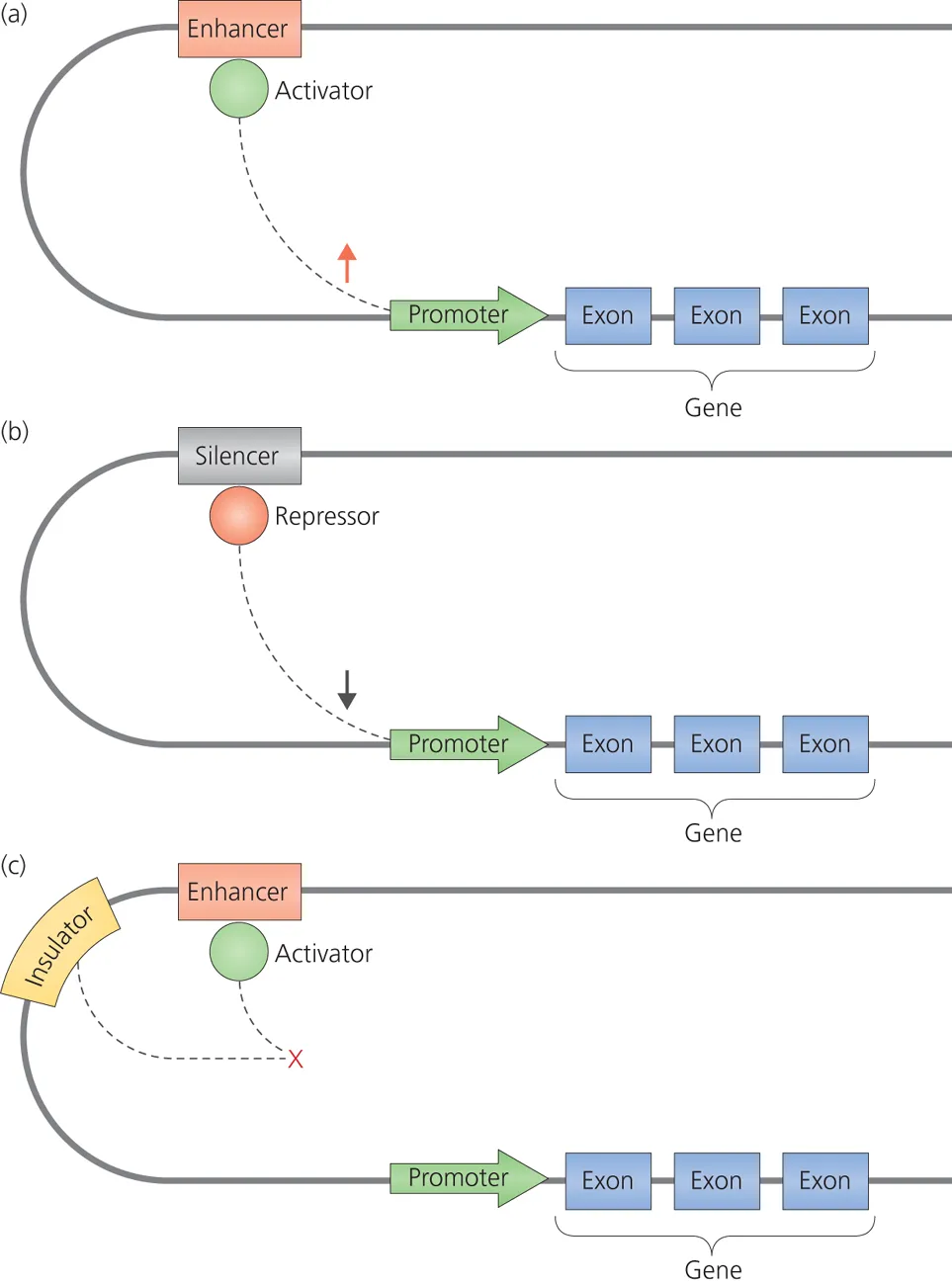
Non-coding DNA contains sequences that work as regulatory elements, determining when and where genes are turned on and off. Such elements provide sites for specialized proteins called transcription factors to bind and either activate or repress the process by which the information from genes is turned into proteins during transcription. These processes are very relevant in cancer genetics. Non-coding DNA contains many types of regulatory elements, including promoters, enhancers, silencers and insulators (Figure 1.4).
Figure 1.4 Non-coding DNA can control gene activity. (a) Enhancer DNA provides binding sites for activators that increase gene transcription. (b) Silencer DNA binds repressor proteins that reduce transcription. (c) An enhancer-blocker sequence blocks the activity of the activator. The promoter sequence lies in front of the gene.
Promoters provide binding sites for the protein machinery that carries out transcription. Promoters are typically found just ahead of the gene on the DNA strand.
Enhancers provide binding sites for proteins that help activate transcription. Enhancers can be found on the DNA strand before or after the gene they control, or sometimes at a distance from the gene.
Silencers provide binding sites for proteins that repress transcription. Like enhancers, silencers can be found before or after the gene they control and can be some distance away on the DNA strand.
Insulators provide binding sites for proteins that control transcription in several ways. Enhancer-blocker insulators prevent enhancers from aiding in transcription. Barrier insulators prevent structural changes in the DNA that would otherwise repress gene activity. Some insulators can function as both an enhancer blocker and a barrier.
RNA molecules. Other regions of non-coding DNA encode specific types of RNA molecules. Examples include tRNA and ribosomal RNA (rRNA).
•tRNA is an adaptor molecule composed of RNA, typically 76–90 nucleotides in length, which serves as the physical connection between the mRNA and the amino acid sequence of proteins.
•rRNAs help assemble amino acids into a chain that forms a protein.
Other specialized RNA molecules include microRNAs (miRNAs), short lengths of RNA that block the process of protein production, and long non-coding RNAs (lncRNAs), which are more extended lengths of RNA that have various regulatory functions in gene activity.
The cell cycle. When a cell is actively dividing, it goes through a four-stage process called the cell cycle, comprising two G (gap or growth) phases, the S phase and the M phase. Together, the G and S phases are known as the interphase. In the first G phase, G1, the cell grows and proteins and RNA are synthesized. The centromere (see below) and other centrosomal components are made. The chromosomes are duplicated in the S phase, and the cell quality-checks the duplication in the second G phase, G2. The cell then undergoes mitosis – the M phase – with the duplicated genetic material pulled to opposite ends of the cell, which then divides to produce two daughter cells.
The centromere is a unique region of a chromosome, usually near the middle. During mitosis, the centromeres can be observed as a constriction of the chromosome. At the centromeric constriction, the two halves of the chromosome, the sister chromatids, are held together until they are pulled in opposite directions.
When the centromere divides, the chromatids become separate chromosomes. The centromere contains specific typ...