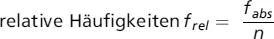Der Band gibt für die Soziale Arbeit einen umfassenden Überblick über die forschungsmethodischen und statistischen Grundlagen erfahrungswissenschaftlichen Arbeitens. Zunächst werden quantitative und qualitative Methoden der Datenerhebung dargestellt. Darauf folgt die Behandlung der deskriptiven und inferenzstatistischen Auswertungsverfahren sowie eine kurze Einführung in SPSS. Einzelne Kapitel befassen sich mit den Themen Fragebogenentwicklung, Evaluationsmethoden sowie Berichterstellung und Publikation von Forschungsergebnissen. Der Band ist als Lehrbuch für Studierende, Lehrende und an Forschung interessierte Praktikerinnen und Praktiker der Sozialen Arbeit und angrenzender Disziplinen konzipiert. Er bietet für die Erstellung einer empirischen Untersuchung im Rahmen einer Bachelor- oder Masterarbeit wertvolle Hilfen.
375,005 Studierende vertrauen auf uns
Zugang zu über 1,5 Millionen Titeln zu einem fairen monatlichen Preis.
Mit unseren Lerntools kannst du noch effizienter lernen.
Während die beschreibende Statistik (oder deskriptive Statistik) das Ziel verfolgt, empirische (d. h. auf erfahrungswissenschaftlichem Wege gewonnene) Daten einer Stichprobe durch Kennwerte (wie z. B. Mittelwerte) und meist unter Verwendung bestimmter Veranschaulichungshilfen (wie z. B. Tabellen oder Graphiken) zusammenzufassen, zu ordnen und übersichtlich darzustellen, strebt die schlussfolgernde Statistik (oder Inferenzstatistik) Aussagen über eine Population (Grundgesamtheit) an, die über die Stichprobe hinausgehen und eine Überprüfung zuvor formulierter Hypothesen (Aussagen, Annahmen) auf der Grundlage von Wahrscheinlichkeitsaussagen (z. B. Signifikanztest) ermöglichen. Im vorliegenden Kapitel wird auf diese beiden großen Teilbereiche der Statistik näher eingegangen. Mögliche Fehler und Fallen, die bei der Durchführung deskriptiver und inferenzstatistischer Analysen auftreten können, werden in Kapitel 11 dargestellt.
6.1 Deskriptive Statistik
Deskriptive Studien können zu unterschiedlichen Datensätzen führen. Sie können beispielsweise in Bezug auf die folgenden Aspekte variieren:
• Umfang der Stichprobe: Die Stichprobe kann sehr groß sein (im Extremfall umfasst sie die Population) oder sehr klein (im Extremfall beinhaltet sie nur eine einzelne Person wie bei Einzelfalluntersuchungen).
• Anzahl der Variablen: Die Studie kann sich nur auf eine einzelne abhängige Variable beziehen (sog. univariate Designs) oder auf mehrere abhängige Variablen (multivariate Designs).
• Messzeitpunkte der Variablen: Auch kann die Studie nur einen einzigen Messzeitpunkt berücksichtigen (sog. Querschnittsstudie) oder zwei oder mehr Messzeitpunkte umfassen (Messwiederholungstudie; liegen die Messzeitpunkte weiter auseinander spricht man auch von einer Längsschnittstudie).
In diesem Abschnitt steht die Berechnung von Statistiken einzelner Variablen aus Querschnittsuntersuchungen im Vordergrund, einschließlich ihrer Darstellung mittels Tabellen und Graphiken. Dieses Vorgehen wird auch als univariate Statistik bezeichnet. Allerdings kommt es in der deskriptiven Statistik recht häufig vor, dass zwei (oder mehr) Variablen gleichzeitig in die Betrachtung einbezogen werden. Bei der simultanen Berücksichtigung von zwei Variablen spricht man von bivariater Statistik, bei mehreren Variablen von multivariater Statistik. Die Berechnung und Darstellung bi- und multivariater Statistiken sowie die Analyse von Messwiederholungsdaten werden in den Kapiteln 7 und 8 behandelt. Lehrbücher zur Einführung insbesondere in die uni- und bivariate Statistik stammen von Clauss & Ebner (1995), Benninghaus (2005) und Holling & Gidega (2011).
Häufigkeiten von Variablenausprägungen
Liegen für Variablenausprägungen sprachliche Umschreibungen vor, wie z. B. »weiblich« und »männlich« für die Geschlechtsvariable, spricht man von Wertekategorien. Für die statistische Auswertung mittels SPSS werden diesen Wertekategorien nachträglich numerische Größen (Zahlen) zugewiesen (Kodierung; z. B. 1 = weiblich, 2 = männlich). Werte hingegen stellen Variablenausprägungen dar, für die es keine sprachliche Umschreibung gibt, wie z. B. bei der Altersvariablen (das Alter wird bereits in Zahlen angegeben) oder bei Einstellungsskalen und Testverfahren. Häufigkeiten geben an, wie oft die ermittelten Wertekategorien oder Werte bei den untersuchten Personen auftreten (vgl. Weinbach & Grinnell, 2000).
Nehmen wir als Beispiel den Fall, dass das individuelle Ausmaß an Empathie bei einer Stichprobe von n = 26 Schülerinnen und Schülern erfasst wurde (z. B. mit Hilfe des »Fragebogens zur Erfassung von Empathie« von Leibetseder, Laireiter, Riepler & Köller, 2001; ein Beispielitem für die Skala »Betroffenheit« lautet: »Es macht mich traurig, in einer Gruppe einen einsamen Menschen zu sehen«). Anschließend wurden die Werte der Probanden, die zwischen 1 = sehr niedrig und 7 = sehr hoch rangieren, in SPSS eingegeben (
Kap. 4.1). Die Häufigkeiten der Empathiewerte kann anschließend anhand von Tabellen und/oder Graphiken veranschaulicht werden.
Häufigkeitstabellen
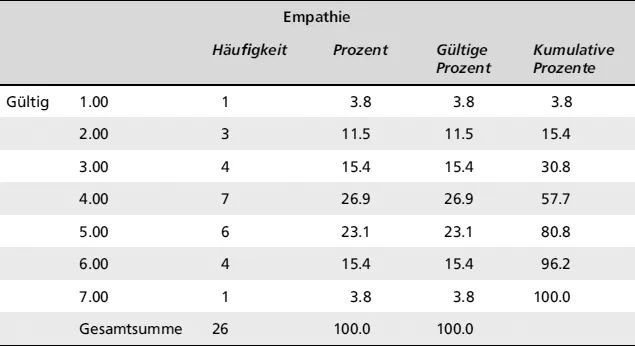
Zur Darstellung von Häufigkeiten in Form einer Tabelle ist im Menü von SPSS der Befehl Analysieren → Deskriptive Statistiken → Häufigkeiten aufzurufen. In dem sich öffnenden Fenster wird dann die Variable »Empathie« ausgewählt. Da die Option »Häufigkeitstabellen anzeigen« in der SPSS-Voreinstellung bereits markiert ist, kann die Berechnung direkt durch Klicken auf OK gestartet werden. Der Output enthält neben Informationen zur Anzahl gültiger und fehlender Werte die resultierende Häufigkeitstabelle, die in Tabelle 6 dargestellt ist.
Während in der ersten Spalte von Tabelle 6 diejenigen Variablenwerte angezeigt werden, die im Datensatz tatsächlich vorhanden sind (d. h. für jeden Wert der siebenstufigen Empathieskala gibt es mindestens eine »gültige« Person in der Stichprobe), finden sich in Spalte 2 die »Häufigkeiten« der einzelnen Werte (meist durch f für engl. frequencies abgekürzt) sowie (in der letzten Zeile) die Gesamtanzahl der Werte (Gesamtsumme = 26). Diese Angaben werden auch als »absolute Häufigkeiten« (fabs)
Tab. 6: Univariate SPSS-Häufigkeitstabelle am Beispiel von »Empathie«
bezeichnet. Spalte 3 (»Prozent«) hingegen zeigt, wie häufig ein bestimmter Wert prozentual (auf 100 % berechnet) im Datensatz auftritt. Diese Angaben kennzeichnen die »relativen Häufigkeiten« (frel), d. h. den Anteil der Personen einer Stichprobe, bei dem eine bestimmte Merkmalsausprägung vorliegt. Die Berechnung der relativen Häufigkeiten erfolgt durch Formel 1.
Formel 1: Berechnung der relativen Häufigkeiten
Beachte: frel bezeichnet die relativen Häufigkeiten, fabs die absoluten Häufigkeiten und n die Anzahl der Personen. Sollen die relativen Häufigkeiten auf Prozent bezogen werden, sind sie zusätzlich mit 100 zu multiplizieren. Nähere Erläuterungen finden sich im Text.
Bezogen auf den Skalenwert 2 der Empathieskala ergibt sich zum Beispiel folgende Rechnung: relative Häufigkeit frel = 3/26 = 0.115. Multipliziert man diesen Wert anschließend mit 100, gelangt man zur prozentualen Häufigkeit von 11.5 (
Tab. 6). Während sich die prozentualen Häufigkeiten (die häufig mit f % abgekürzt werden) auf alle Antworten einschließlich eventuell fehlender Werte beziehen, sind fehlende Werte bei den »gültigen Prozent« in Spalte 4 von der Berechnung ausgeschlossen. Da im vorliegenden Datensatz keine fehlenden Werte enthalten sind, fallen beide Spalten in Tabelle 6 identisc...
Inhaltsverzeichnis
Deckblatt
Titelseite
Impressum
Inhalt
Vorwort
I Forschungsmethoden
II Statistik
Literaturverzeichnis
Stichwortverzeichnis
Häufig gestellte Fragen
Ja, du kannst dein Abo jederzeit über den Tab Abo in deinen Kontoeinstellungen auf der Perlego-Website kündigen. Dein Abo bleibt bis zum Ende deines aktuellen Abrechnungszeitraums aktiv. Erfahre, wie du dein Abo kündigen kannst
Nein, Bücher können nicht als externe Dateien, z. B. PDFs, zur Verwendung außerhalb von Perlego heruntergeladen werden. Du kannst jedoch Bücher in der Perlego-App herunterladen, um sie offline auf deinem Smartphone oder Tablet zu lesen. Erfahre, wie du Bücher herunterladen kannst, um sie offline zu lesen
Perlego bietet zwei Pläne an: Essential und Complete
Essential ist ideal für Lernende und Fachkräfte, die es genießen, eine Vielzahl von Themen zu erkunden. Greife auf die Essential Library mit über 800.000 vertrauenswürdigen Titeln und Bestsellern in den Bereichen Wirtschaft, persönliche Weiterentwicklung und Geisteswissenschaften zu. Enthält unbegrenzte Lesezeit und Standard-Vorlesestimme.
Complete: Perfekt für fortgeschrittene Lernende und Forschende, die vollen, uneingeschränkten Zugriff benötigen. Entsperre über 1,5 Millionen Bücher zu Hunderten von Themen, einschließlich akademischen und spezialisierten Titeln. Der Complete-Plan enthält außerdem fortschrittliche Funktionen wie Premium Vorlesen und Forschungsassistent.
Beide Pläne sind mit monatlicher, halbjährlicher oder jährlicher Abrechnungskadenz verfügbar.
Wir sind ein Online-Lehrbuch-Abonnement-Service, bei dem du für weniger als den Preis eines einzelnen Buchs pro Monat Zugriff auf eine gesamte Online-Bibliothek erhältst. Bei über 1,5 Millionen Büchern zu mehr als 990 Themen bist du bestens versorgt! Erfahre mehr über unsere Mission
Achte auf das Symbol zum Vorlesen bei deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Erfahre mehr über die Funktion „Vorlesen“
Ja! Du kannst die Perlego-App sowohl auf iOS- als auch auf Android-Geräten nutzen, damit du jederzeit und überall lesen kannst – sogar offline. Perfekt für den Weg zur Arbeit oder wenn du unterwegs bist. Bitte beachte, dass wir Geräte, auf denen die Betriebssysteme iOS 13 und Android 7 oder noch ältere Versionen ausgeführt werden, nicht unterstützen können. Mehr über die Verwendung der App erfahren
Ja, du kannst auf Forschungsmethoden und Statistik für die Soziale Arbeit von Mathias Blanz im PDF- und/oder ePUB-Format sowie auf andere beliebte Bücher in Social Sciences & Social Work zugreifen. In unserem Katalog stehen über 1,5 Millionen Bücher zur Verfügung.