Data Science Methods and Tools for Research and Practice
Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter, Julia Lane, Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter, Julia Lane
This is a test
This is a test
Buch teilen
391 Seiten
English
ePUB (handyfreundlich)
Über iOS und Android verfügbar
eBook - ePub
Big Data and Social Science
Data Science Methods and Tools for Research and Practice
Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter, Julia Lane, Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter, Julia Lane
Angaben zum Buch
Buchvorschau
Inhaltsverzeichnis
Quellenangaben
Über dieses Buch
Big Data and Social Science: Data Science Methods and Tools for Research and Practice, Second Edition shows how to apply data science to real-world problems, covering all stages of a data-intensive social science or policy project. Prominent leaders in the social sciences, statistics, and computer science as well as the field of data science provide a unique perspective on how to apply modern social science research principles and current analytical and computational tools. The text teaches you how to identify and collect appropriate data, apply data science methods and tools to the data, and recognize and respond to data errors, biases, and limitations.
Features:
Takes an accessible, hands-on approach to handling new types of data in the social sciences
Presents the key data science tools in a non-intimidating way to both social and data scientists while keeping the focus on research questions and purposes
Illustrates social science and data science principles through real-world problems
Links computer science concepts to practical social science research
Promotes good scientific practice
Provides freely available workbooks with data, code, and practical programming exercises, through Binder and GitHub
New to the Second Edition:
Increased use of examples from different areas of social sciences
New chapter on dealing with Bias and Fairness in Machine Learning models
Expanded chapters focusing on Machine Learning and Text Analysis
Revamped hands-on Jupyter notebooks to reinforce concepts covered in each chapter
This classroom-tested book fills a major gap in graduate- and professional-level data science and social science education. It can be used to train a new generation of social data scientists to tackle real-world problems and improve the skills and competencies of applied social scientists and public policy practitioners. It empowers you to use the massive and rapidly growing amounts of available data to interpret economic and social activities in a scientific and rigorous manner.
Häufig gestellte Fragen
Wie kann ich mein Abo kündigen?
Gehe einfach zum Kontobereich in den Einstellungen und klicke auf „Abo kündigen“ – ganz einfach. Nachdem du gekündigt hast, bleibt deine Mitgliedschaft für den verbleibenden Abozeitraum, den du bereits bezahlt hast, aktiv. Mehr Informationen hier.
(Wie) Kann ich Bücher herunterladen?
Derzeit stehen all unsere auf Mobilgeräte reagierenden ePub-Bücher zum Download über die App zur Verfügung. Die meisten unserer PDFs stehen ebenfalls zum Download bereit; wir arbeiten daran, auch die übrigen PDFs zum Download anzubieten, bei denen dies aktuell noch nicht möglich ist. Weitere Informationen hier.
Welcher Unterschied besteht bei den Preisen zwischen den Aboplänen?
Mit beiden Aboplänen erhältst du vollen Zugang zur Bibliothek und allen Funktionen von Perlego. Die einzigen Unterschiede bestehen im Preis und dem Abozeitraum: Mit dem Jahresabo sparst du auf 12 Monate gerechnet im Vergleich zum Monatsabo rund 30 %.
Was ist Perlego?
Wir sind ein Online-Abodienst für Lehrbücher, bei dem du für weniger als den Preis eines einzelnen Buches pro Monat Zugang zu einer ganzen Online-Bibliothek erhältst. Mit über 1 Million Büchern zu über 1.000 verschiedenen Themen haben wir bestimmt alles, was du brauchst! Weitere Informationen hier.
Unterstützt Perlego Text-zu-Sprache?
Achte auf das Symbol zum Vorlesen in deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Weitere Informationen hier.
Ist Big Data and Social Science als Online-PDF/ePub verfügbar?
Ja, du hast Zugang zu Big Data and Social Science von Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter, Julia Lane, Ian Foster, Rayid Ghani, Ron S. Jarmin, Frauke Kreuter, Julia Lane im PDF- und/oder ePub-Format sowie zu anderen beliebten Büchern aus Mathematics & Probability & Statistics. Aus unserem Katalog stehen dir über 1 Million Bücher zur Verfügung.
The world has changed for empirical social scientists. The new types of “big data” have generated an entire new research field—that of data science. That world is dominated by computer scientists who have generated new ways of creating and collecting data, developed new analytical techniques, and provided new ways of visualizing and presenting information. The results have been to change the nature of the work that social scientists do.
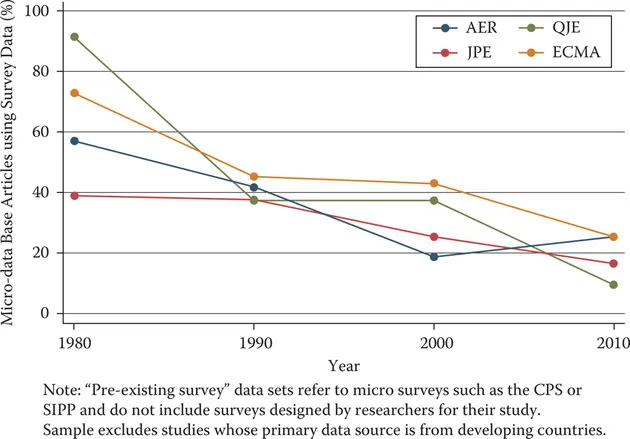
Social scientists have been enthusiastic in responding to the new opportunity. Python and R are becoming as, and hopefully more, well-known as SAS and Stata—indeed, the 2018 Nobel Laureate in Economics, Paul Romer, is a Python convert (Kopf, 2018). Research also has changed. Researchers draw on data that are “found” rather than “made” by federal agencies; those publishing in leading academic journals are much less likely today to draw on preprocessed survey data (Figure 1.1). Social science workflows can become more automated, replicable, and reproducible (Yarkoni et al., 2019).
Figure 1.1. Use of pre-existing survey data in publications in leading journals, 1980–2010 (Chetty, 2012)
Policy also has changed. The Foundations of Evidence-based Policy Act, which was signed into law in 2019, requires agencies to utilize evidence and data in making policy decisions (Hart, 2019). The Act, together with the Federal Data Strategy (Office of Management and Budget, 2019), establishes both Chief Data Officers to oversee the collection, use of, and access to many new types of data and a learning agenda to build the data science capacity of agency staff.
In addition, the jobs have changed. The new job title of “data scientist” is highlighted in job advertisements on CareerBuilder.com and Burningglass—supplanting the demand for statisticians, economists, and other quantitative social scientists if starting salaries are useful indicators. At the federal level, the Office of Personnel Management has created a new data scientist job title.
The goal of this book is to provide social scientists with an understanding of the key elements of this new science, the value of the tools, and the opportunities for doing better work. The goal is also to identify the many ways in which the analytical toolkits possessed by social scientists can enhance the generalizability and usefulness of the work done by computer scientists.
We take a pragmatic approach, drawn on our experience of working with data to tackle a wide variety of policy problems. Most social scientists set out to solve a real world social or economic problem: they frame the problem, identify the data, conduct the analysis, and then draw inferences. At all points, of course, the social scientist needs to consider the ethical ramifications of their work, particularly respecting privacy and confidentiality. The book follows the same structure. We chose a particular problem—the link between research investments and innovation—because that is a major social science policy issue, and one in which social scientists have been addressing the use of big data techniques.
1.2Defining big data and its value
There are almost as many definitions of big data as there are new types of data. One approach is to define big data as anything too big to fit onto your computer. Another approach is to define it as data with high volume, high velocity, and great variety. We choose the description adopted by the American Association of Public Opinion Research: “The term ‘Big Data’ is an imprecise description of a rich and complicated set of characteristics, practices, techniques, ethical issues, and outcomes all associated with data” (Japec et al., 2015).
►This topic will be discussed in more detail in Chapter 5.
The value of the new types of data for social science is quite substantial. Personal data have been hailed as the “new oil” of the 21st century (Greenwood et al., 2014). Policymakers have found that detailed data on human beings can be used to reduce crime (Lynch, 2018), improve health delivery (Pan et al., 2017), and better manage cities (Glaeser, 2019). Society can gain as well—much cited work shows data-driven businesses are 5% more productive and 6% more profitable than their competitors (Brynjolfsson et al., 2011). Henry Brady provides a succinct overview when he says, “Burgeoning data and innovative methods facilitate answering previously hard-to-tackle questions about society by offering new ways to form concepts from data, to do descriptive inference, to make causal inferences, and to generate predictions. They also pose challenges as social scientists must grasp the meaning of concepts and predictions generated by convoluted algorithms, weigh the relative value of prediction versus causal inference, and cope with ethical challenges as their methods, such as algorithms for mobilizing voters or determining bail, are adopted by policy makers” (Brady, 2019).
Example: New potential for social science
The billion prices project is a great example of how researchers can use new web-scraping techniques to obtain online prices from hundreds of websites and thousands of webpages to build datasets customized to fit specific measurement and research needs in ways that were unimaginable 20 years ago (Cavallo and Rigobon, 2016); other great examples include the way in which researchers use text analysis of political speeches to study political polarization (Peterson and Spirling, 2018) or of Airbnb postings to obtain new insights into racial discrimination (Edelman et al., 2017).
Of course, these new sources come with their own caveats and biases that need to be considered when drawing inferences. We will cover this later in the book in more detail.
But most interestingly, the new data can change the way we think about behavior. For example, in a study of environmental effects on health, researchers combine information on public school cafeteria deliveries with children’s school health records to show that simply putting water jets in cafeterias reduced milk consumption and also reduced childhood obesity (Schwartz et al., 2016). Another study which sheds new light into the role of peers on productivity finds that the productivity of a cashier increases if they are within eyesight of a highly productive cashier but not otherwise (Mas and Moretti, 2009). Studies such as these show ways in which clever use of data can lead to greater understanding of the effects of complex environmental inputs on human behavior.
New types of data also can enable us to study and examine small groups—the tails of a distribution—in a way that is not possible with small data. Much of the interest in human behavior is driven by those tails, such as health care costs by small numbers of ill people (Stanton and Rutherford, 2006) or economic activity and employment by a small number of firms (Evans, 1987; Jovanovic, 1982).
Our excitement about the value of new types of data must be accompanied by a recognition of the lessons learned by statisticians and social scientists from their past experience with surveys and small scale data collection. The next sections provide a brief overview.
1.3The importance of inference
It is critically important to be able to use data to generalize from the data source to the population. That requirement exists, regardless of the data source. Statisticians and social scientists have developed methodologies for survey data to overcome problems in the data-generating process. A guiding principle for survey methodologists is the total survey error framework, and statistical methods for weighting, calibration, and other forms of adjustment are commonly used to mitigate errors in the survey process. Likewise for “broken” experimental data, techniques such as propensity score adjustment and principal stratification are widely used to fix flaws in the data-generating process.
If we take a look across the social sciences, including economics, public policy, sociology, management, (parts of) psychology, and the like, their scientific activities can be grouped into three categories with three different inferential goals: Description, Causation, and Prediction.
1.3.1Description
The job of many social scientists is to provide descriptive statements about the population of interest. These could be univariate, bivariate, or even multivariate statements.
Usually, descriptive statistics are created based on census data or sample surveys to create some summary statistics such as a mean, a median, or a graphical distribution to describe the population of interest. In the case of a census, the work ends there. With sample surveys, the point estimates come with measures of uncertainties (standard errors). The estimation ...