1. This book will attempt to provide a wide range of research and development work under the umbrella of Intelligent Computing. Aim of this book is to motivate research and applications of advanced Intelligent Computing. This book will try to gather original contributions from prospective authors specially solicited on topics covered under broad areas such as Linguistic Computing, Statistical Computing, Data Computing and Ambient Applications. Some of the topics will cover industrial issues/applications and academic research into intelligent computing. 2. Deep Learning architectures are being increasingly used in day to day applications where traditional machine learning and deep learning algorithms were used. Their improved accuracy, effectiveness in handling large data as well as reduced redundancy have major impact on growing application in the relevant field creating a demand for such a book in the market 3. This is an edited book that covers a very wide are of AI applications, so it will be difficult to specify principle competitive books. This book could be unique in terms of the subject are that the book trying to cover
Preguntas frecuentes
¿Cómo cancelo mi suscripción?
Simplemente, dirígete a la sección ajustes de la cuenta y haz clic en «Cancelar suscripción». Así de sencillo. Después de cancelar tu suscripción, esta permanecerá activa el tiempo restante que hayas pagado. Obtén más información aquí.
¿Cómo descargo los libros?
Por el momento, todos nuestros libros ePub adaptables a dispositivos móviles se pueden descargar a través de la aplicación. La mayor parte de nuestros PDF también se puede descargar y ya estamos trabajando para que el resto también sea descargable. Obtén más información aquí.
¿En qué se diferencian los planes de precios?
Ambos planes te permiten acceder por completo a la biblioteca y a todas las funciones de Perlego. Las únicas diferencias son el precio y el período de suscripción: con el plan anual ahorrarás en torno a un 30 % en comparación con 12 meses de un plan mensual.
¿Qué es Perlego?
Somos un servicio de suscripción de libros de texto en línea que te permite acceder a toda una biblioteca en línea por menos de lo que cuesta un libro al mes. Con más de un millón de libros sobre más de 1000 categorías, ¡tenemos todo lo que necesitas! Obtén más información aquí.
¿Perlego ofrece la función de texto a voz?
Busca el símbolo de lectura en voz alta en tu próximo libro para ver si puedes escucharlo. La herramienta de lectura en voz alta lee el texto en voz alta por ti, resaltando el texto a medida que se lee. Puedes pausarla, acelerarla y ralentizarla. Obtén más información aquí.
¿Es Design of Intelligent Applications using Machine Learning and Deep Learning Techniques un PDF/ePUB en línea?
Sí, puedes acceder a Design of Intelligent Applications using Machine Learning and Deep Learning Techniques de Ramchandra Sharad Mangrulkar, Antonis Michalas, Narendra Shekokar, Meera Narvekar, Pallavi Vijay Chavan, Ramchandra Sharad Mangrulkar, Antonis Michalas, Narendra Shekokar, Meera Narvekar, Pallavi Vijay Chavan en formato PDF o ePUB, así como a otros libros populares de Informatik y Künstliche Intelligenz (KI) & Semantik. Tenemos más de un millón de libros disponibles en nuestro catálogo para que explores.
Data Acquisition and Preparation for Artificial Intelligence and Machine Learning Applications
Kallol Bosu Roy Choudhuri
Cognizant Technology Solutions
Ramchandra S. Mangrulkar
University of Mumbai
Contents
1.1 Introduction
1.2 Reference Architecture
1.2.1 Data Sources
1.2.2 Data Storage
1.2.3 Batch Processing
1.2.4 Real-Time Message Ingestion
1.2.5 Stream Processing
1.2.6 Machine Learning
1.2.7 Analytical Data Store
1.2.8 Analytics and Reports
1.2.9 Orchestration
1.3 Data Acquisition Layer
1.3.1 File Systems
1.3.2 Databases
1.3.3 Applications
1.3.4 Devices
1.3.5 Enterprise Data Gateway
1.3.6 Field Gateway
1.3.7 Data Integration Services
1.3.8 Data Ingestion Services
1.4 Data Ingestion Layer
1.4.1 Data Storage Layer
1.4.2 Landing Layer
1.4.3 Cleansed Layer
1.4.4 Processed Layer
1.4.5 Data Processing Layer
1.4.6 Data Processing Engine
1.4.7 Data Processing Programs
1.4.8 Scheduling Engine
1.4.9 Scheduling Scripts
1.5 Data Quality and Cleansing Layer
1.5.1 Master Data Management (MDM) System
1.5.2 Master Data Management (MDM) Referencing Programs
1.5.3 Data Quality Check Programs
1.5.4 Rejected/Quarantined Layer
Bibliography
1.1 Introduction
This chapter introduces the essential concepts of data acquisition, ingestion, data quality, cleansing and preparation. Data forms the basis of all decision-making processes. AI and ML being heavily dependent on accurate and reliable data, these stages are important prerequisites to build any AI and ML application. Before data can be effectively fed into a ML model or an AI algorithm, the data goes through the following stages such as:
Data acquisition
Data ingestion
Data quality and cleansing
In the following sections of this chapter, we will understand what each of the above stages in data processing means. We will also study the various components and concepts involved in successfully executing each phase of the data processing.
1.2 Reference Architecture
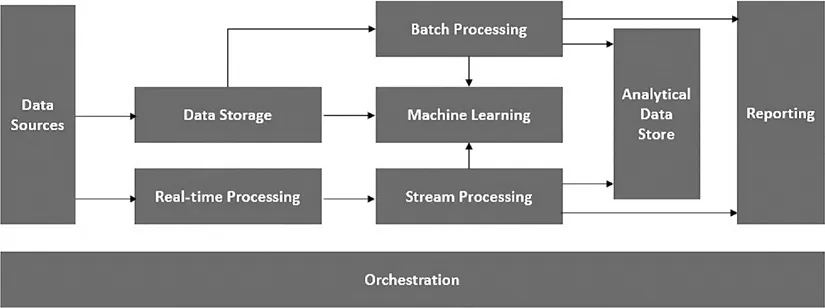
In the next few sections, we will look at each of the above stages in more detail. Before proceeding further, let us look at the below diagram that depicts the general reference architecture for data collection, ingestion, cleansing and preparation for AI and ML applications (Figure 1.1).
FIGURE 1.1 AI/ML data processing reference architecture.
Figure 1.1, gives the details about the different stages. The first stage is to establish data ingestion components from the source, followed by cleansing the raw data and then preparing the data for training a ML model or feeding it as an input for AI applications. The various components of the reference architecture are listed below:
Data sources
Data storage
Batch processing
Real-time message ingestion
Stream processing
ML
Analytical data store
Analytics and reports
Orchestration
In the below sections, we will look at each of these data processing components.
1.2.1 Data Sources
For AI/ML applications, data can be sourced from various types of sources. The data is first collected (acquired), followed by storage and further processing. Usually, data can come from the following types of source systems:
Application data stores such as relational databases (SQL Server, Oracle, MySQL and so on), or it can also be NoSQL databases (Cassandra, MongoDB, PostgreSQL and so on)
Log files and flat files generated by various types of business applications, monitoring and logging software (Splunk, ELK and so on)
IoT devices that produce data
1.2.2 Data Storage
Data acquired from various sources comes in various types of file formats such as XML, JSON, CSV, ORC, AVRO and Parquet to name a few popular file types. In AI/ML applications, the data is so huge that usually the data is stored in the form of files on affordable commodity storage media governed by powerful file system management software. This type of data is known as big data, and the underlying hardware storage media coupled with the file system management software is known as a data lake. Hadoop is an example of a big data lake system.
1.2.3 Batch Processing
The acquired data keeps accumulating in the data lake. At regular intervals, the accumulated data is processed by scheduled workflows and processes. These scheduled workflows and processes are known as batch processes, while the process of scheduled processing of the accumulated data at regular intervals is known as batch processing. Owing to the massive amount of data to be processed, often, parallel computing is employed to achieve efficiency and speed. Apache Spark is an example of a big data parallel computing engine.
1.2.4 Real-Time Message Ingestion
At times, usually in the case of IoT device data, there is an immediate need to process the data. This type of data is processed immediately in order to extract vital time-sensitive information, such as remote monitoring of manufacturing equipment. In such cases, it will not be enough to have scheduled workflows waiting to process the incoming data at regular intervals. Instead, processes are triggered as soon as new data arrives. This process of immediate (near real time) data processing is known as real-time processing.
Sometimes, a trade-off between batch processing and real-time processing may be required for certain systems. In such cases, the concept of micro-batching is employed. Micro-batching is a technique where the scheduled workflows are executed at shorter intervals of, say, every 5 minutes (instead of hourly or daily).
1.2.5 Stream Processing
Once the real-time messages have been ingested from IoT device sources or applications, there may be requirements to operate directly on the real-time data. The processing of data in real time enables the discovery of critical time-sensitive information, such as predicting a health emergency from a heart patient’s Fitbit data in real time. Apache Storm and Spark Streaming are the examples of stream data processing components.
1.2.6 Machine Learning
The processed data is fed into ML components for the purpose of model training and tuning. Often, it may not be possible to feed the raw data into a ML model. There may be many inaccuracies, outliers, string values, special characters and so on that if addressed before the data can be used by a ML process. The ML components use the cleansed and processed data for various learning purposes.
1.2.7 Analytical Data Store
After the data has been cleansed, the data is stored in a central data store for consumption by various downstream processes. Analytical data stores are often referred to as data warehouses where processed data is properly organized and generally stored in the form of fact dimensional models. Data from the tables in the analytical data stores is used in various downstream reports. Examples of some modern popular analytical data stores are SQL Data Warehouse, Amazon Redshift and Google BigQuery.