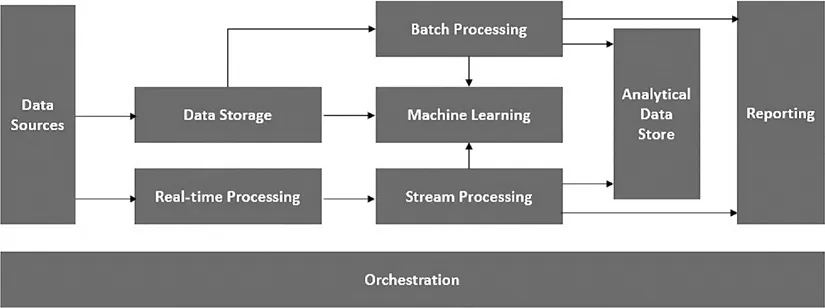
Machine learning (ML) and deep learning (DL) algorithms are invaluable resources for Industry 4.0 and allied areas and are considered as the future of computing. A subfield called neural networks, to recognize and understand patterns in data, helps a machine carry out tasks in a manner similar to humans. The intelligent models developed using ML and DL are effectively designed and are fully investigated – bringing in practical applications in many fields such as health care, agriculture and security. These algorithms can only be successfully applied in the context of data computing and analysis. Today, ML and DL have created conditions for potential developments in detection and prediction.
Apart from these domains, ML and DL are found useful in analysing the social behaviour of humans. With the advancements in the amount and type of data available for use, it became necessary to build a means to process the data and that is where deep neural networks prove their importance. These networks are capable of handling a large amount of data in such fields as finance and images. This book also exploits key applications in Industry 4.0 including:
· Fundamental models, issues and challenges in ML and DL.
· Comprehensive analyses and probabilistic approaches for ML and DL.
· Various applications in healthcare predictions such as mental health, cancer, thyroid disease, lifestyle disease and cardiac arrhythmia.
· Industry 4.0 applications such as facial recognition, feather classification, water stress prediction, deforestation control, tourism and social networking.
· Security aspects of Industry 4.0 applications suggest remedial actions against possible attacks and prediction of associated risks.
- Information is presented in an accessible way for students, researchers and scientists, business innovators and entrepreneurs, sustainable assessment and management professionals.
This book equips readers with a knowledge of data analytics, ML and DL techniques for applications defined under the umbrella of Industry 4.0. This book offers comprehensive coverage, promising ideas and outstanding research contributions, supporting further development of ML and DL approaches by applying intelligence in various applications.