Essential PySpark for Scalable Data Analytics
Sreeram Nudurupati
- 322 páginas
- English
- ePUB (apto para móviles)
- Disponible en iOS y Android
Essential PySpark for Scalable Data Analytics
Sreeram Nudurupati
Información del libro
Get started with distributed computing using PySpark, a single unified framework to solve end-to-end data analytics at scaleKey Features• Discover how to convert huge amounts of raw data into meaningful and actionable insights• Use Spark's unified analytics engine for end-to-end analytics, from data preparation to predictive analytics• Perform data ingestion, cleansing, and integration for ML, data analytics, and data visualizationBook DescriptionApache Spark is a unified data analytics engine designed to process huge volumes of data quickly and efficiently. PySpark is Apache Spark's Python language API, which offers Python developers an easy-to-use scalable data analytics framework. Essential PySpark for Scalable Data Analytics starts by exploring the distributed computing paradigm and provides a high-level overview of Apache Spark. You'll begin your analytics journey with the data engineering process, learning how to perform data ingestion, cleansing, and integration at scale. This book helps you build real-time analytics pipelines that help you gain insights faster. You'll then discover methods for building cloud-based data lakes, and explore Delta Lake, which brings reliability to data lakes. The book also covers Data Lakehouse, an emerging paradigm, which combines the structure and performance of a data warehouse with the scalability of cloud-based data lakes. Later, you'll perform scalable data science and machine learning tasks using PySpark, such as data preparation, feature engineering, and model training and productionization. Finally, you'll learn ways to scale out standard Python ML libraries along with a new pandas API on top of PySpark called Koalas. By the end of this PySpark book, you'll be able to harness the power of PySpark to solve business problems.What you will learn• Understand the role of distributed computing in the world of big data• Gain an appreciation for Apache Spark as the de facto go-to for big data processing• Scale out your data analytics process using Apache Spark• Build data pipelines using data lakes, and perform data visualization with PySpark and Spark SQL• Leverage the cloud to build truly scalable and real-time data analytics applications• Explore the applications of data science and scalable machine learning with PySpark• Integrate your clean and curated data with BI and SQL analysis toolsWho this book is forThis book is for practicing data engineers, data scientists, data analysts, and data enthusiasts who are already using data analytics to explore distributed and scalable data analytics. Basic to intermediate knowledge of the disciplines of data engineering, data science, and SQL analytics is expected. General proficiency in using any programming language, especially Python, and working knowledge of performing data analytics using frameworks such as pandas and SQL will help you to get the most out of this book.
Preguntas frecuentes
Información
Section 1: Data Engineering
- Chapter 1, Distributed Computing Primer
- Chapter 2, Data Ingestion
- Chapter 3, Data Cleansing and Integration
- Chapter 4, Real-Time Data Analytics
Chapter 1: Distributed Computing Primer
- Introduction Distributed Computing
- Distributed Computing with Apache Spark
- Big data processing with Spark SQL and DataFrames
Technical requirements
- Online Retail: https://archive.ics.uci.edu/ml/datasets/Online+Retail+II
- Image Data: https://archive.ics.uci.edu/ml/datasets/Rice+Leaf+Diseases
- Census Data: https://archive.ics.uci.edu/ml/datasets/Census+Income
- Country Data: https://public.opendatasoft.com/explore/dataset/countries-codes/information/
Distributed Computing
Introduction to Distributed Computing
Data Parallel Processing
- The actual data that needs to be processed
- The piece of code or business logic that needs to be applied to the data in order to process it
- First, bring the data to the machine where our code is running.
- Second, take our code to where our data is actually stored.
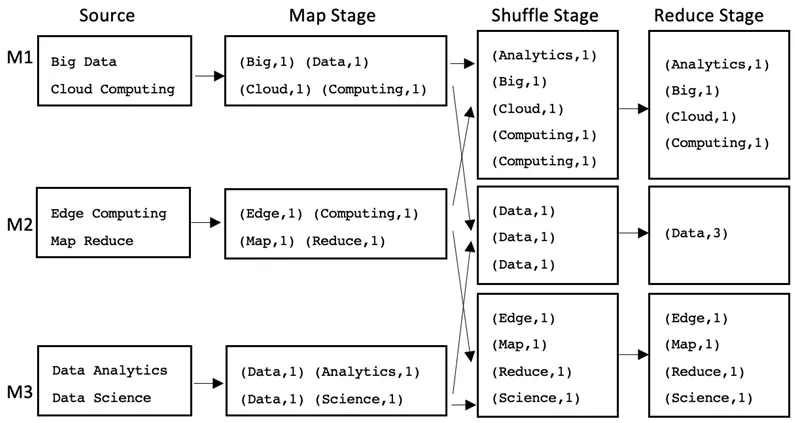
Data Parallel Processing using the MapReduce paradigm
- The Map stage
- The Shuffle stage
- The Reduce stage