![]()
Part 1 Mastering the data set
Engineering an effective machine learning system depends on a thorough understanding of the project data set. If you have prior experience building machine learning models, you might be tempted to skip this step. After all, shouldn’t the machine learning algorithms automate the learning of the patterns from the data? However, as you are going to observe throughout this book, machine learning systems that succeed in production depend on a practitioner who understands the project data set and then applies human insights about the data in ways that modern algorithms can’t.
![]()
1 Introduction to serverless machine learning
This chapter covers
- What serverless machine learning is and why you should care
- The difference between machine learning code and a machine learning platform
- How this book teaches about serverless machine learning
- The target audience for this book
- What you can learn from this book
A Grand Canyon—like gulf separates experimental machine learning code and production machine learning systems. The scenic view across the “canyon” is magical: when a machine learning system is running successfully in production it can seem prescient. The first time I started typing a query into a machine learning—powered autocomplete search bar and saw the system anticipate my words, I was hooked. I must have tried dozens of different queries to see how well the system worked. So, what does it take to trek across the “canyon?”
It is surprisingly easy to get started. Given the right data and less than an hour of coding time, it is possible to write the experimental machine learning code and re-create the remarkable experience I have had using the search bar that predicted my words. In my conversations with information technology professionals, I find that many have started to experiment with machine learning. Online classes in machine learning, such as the one from Coursera and Andrew Ng, have a wealth of information about how to get started with machine learning basics. Increasingly, companies that hire for information technology jobs expect entry-level experience with machine learning.1
While it is relatively easy to experiment with machine learning, building on the results of the experiments to deliver products, services, or features has proven to be difficult. Some companies have even started to use the word unicorn to describe the unreasonably hard-to-find machine learning practitioners with the skills needed to launch production machine learning systems. Practitioners with successful launch experience often have skills that span machine learning, software engineering, and many information technology specialties.
This book is for those who are interested in trekking the journey from experimental machine learning code to a production machine learning system. In this book, I will teach you how to assemble the components for a machine learning platform and use them as a foundation for your production machine learning system. In the process, you will learn:
-
How to use and integrate public cloud services, including the ones from Amazon Web Services (AWS), for machine learning, including data ingest, storage, and processing
-
How to assess and achieve data quality standards for machine learning from structured data
-
How to engineer synthetic features to improve machine learning effectiveness
-
How to reproducibly sample structured data into experimental subsets for exploration and analysis
-
How to implement machine learning models using PyTorch and Python in a Jupyter notebook environment
-
How to implement data processing and machine learning pipelines to achieve both high throughput and low latency
-
How to train and deploy machine learning models that depend on data processing pipelines
-
How to monitor and manage the life cycle of your machine learning system once it is put in production
Why should you invest the time to learn these skills? They will not make you a renowned machine learning researcher or help you discover the next ground-breaking machine learning algorithm. However, if you learn from this book, you can prepare yourself to deliver the results of your machine learning efforts sooner and more productively, and grow to be a more valuable contributor to your machine learning project, team, or organization.
1.1 What is a machine learning platform?
If you have never heard of the phrase “yak shaving” as it is used in the information technology industry,2 here’s a hypothetical example of how it may show up during a day in a life of a machine learning practitioner:
My company wants our machine learning system to launch in a month . . . but it is taking us too long to train our machine learning models . . . so I should speed things up by enabling graphical processing units (GPUs) for training . . . but our GPU device drivers are incompatible with our machine learning framework . . . so I need to upgrade to the latest Linux device drivers for compatibility . . . which means that I need to be on the new version of the Linux distribution.
There are many more similar possibilities in which you need to “shave a yak” to speed up machine learning. The contemporary practice of launching machine learning—based systems in production and keeping them running has too much in common with the yak-shaving story. Instead of focusing on the features needed to make the product a resounding success, too much engineering time is spent on apparently unrelated activities like re-installing Linux device drivers or searching the web for the right cluster settings to configure the data processing middleware.
Why is that? Even if you have the expertise of machine learning PhDs on your project, you still need the support of many information technology services and resources to launch the system. “Hidden Technical Debt in Machine Learning Systems,” a peer-reviewed article published in 2015 and based on insights from dozens of machine learning practitioners at Google, advises that mature machine learning systems “end up being (at most) 5% machine learning code” (http://mng.bz/01jl).
This book uses the phrase “machine learning platform” to describe the 95% that play a supporting yet critical role in the entire system. Having the right machine learning platform can make or break your product.
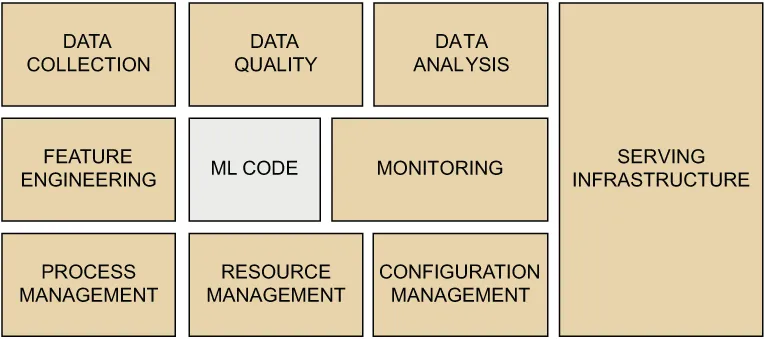
If you take a closer look at figure 1.1, you should be able to describe some of the capabilities you need from a machine learning platform. Obviously, the platform needs to ingest and store data, process data (which includes applying machine learning and other computations to data), and serve the insights discovered by machine learning to the users of the platform. The less obvious observation is that the platform should be able to handle multiple, concurrent machine learning projects and enable multiple users to run the projects in isolation from each other. Otherwise, replacing only the machine learning code translates to reworking 95% of the system.
Figure 1.1 Although machine learning code is what makes your machine learning system stand out, it amounts to only about 5% of the system code according to the experiences described in “Hidden Technical Debt in Machine Learning Systems” by Google’s Sculley et al. Serverless machine learning helps you assemble the other 95% using cloud-based infrastructure.
1.2 Challenges when designing a machine learning platform
How much data should the platform be able to store and process? AcademicTorrents.com is a website dedicated to helping machine learning practitioners get access to public data sets suitable for machine learning. The website lists over 50 TB of data sets, of which the largest are 1—5 TB in size. Kaggle, a website popular for hosting data science competitions, includes data sets as large as 3 TB. You might be tempted to ignore the largest data sets as outliers and focus on more common data sets that are at the scale of gigabytes. However, you should keep in mind that successes in machine learning are often due to reliance on larger data sets. “The Unreasonable Effectiveness of Data,” by Peter Norvig et al. (http://mng.bz/5Zz4), argues in favor of the machine learning systems that can take advantage of larger data sets: “simple models and a lot of data trump more elaborate models based on less data.”
A machine learning platform that is expected to operate on a scale of terabytes to petabytes of data for storage and processing must be built as a distributed computing system using multiple inter-networked servers in a cluster, each processing a part of the data set. Otherwise, a data set with hundreds of gigabytes to terabytes will cause out-of-memory problems when processed by a single server with a typical hardware configuration. Having a cluster of servers as part of a machine learning platform also addresses the input/output bandwidth limitations of individual servers. Most servers can supply a CPU with just a few gigabytes of data per second. This means that most types of data processing performed by a machine learning platform can be sped up by splitting up the data sets in chunks (sometimes called shards) that are processed in parallel by the servers in the cluster. The distributed systems design for a machine learning platform as described is commonly known as scaling out.
A significant portion of figure 1.1 is the serving part of the infrastructure used in the platform. This is the part that exposes the data insights produced by the machine learning code to the users of the platform. If you have ever had your email provider classify your emails as spam or not spam, or if you have ever used a product recommendation feature of your favorite e-commerce website, you have interacted as a user with the serving infrastructure part of a machine learning platform. The serving infrastructure for a major email or an e-commerce provider needs to be capable of making the decisions for millions of users around the globe, millions of times a second. Of course, not every machine learning platform needs to operate at this scale. However, if you are planning to deliver a product based on machine learning, you need to keep in mind that it is within the realm of possibility for digital products and services to reach hundreds of millions of users in months. For example, Pokemon Go, a machine learning—powered video game from Niantic, reached half a billion users in less than two months.
Is it prohibitively expensive to launch and operate a machine learning platform at scale? As recently as the 2000s, running a scalable machine learning platform would have required a significant upfront investment in servers, storage, networking as well as software and the expertise needed to build one. The first machine learning platform I worked on for a customer back in ...