
Scala and Spark for Big Data Analytics
Md. Rezaul Karim, Sridhar Alla
- 898 páginas
- English
- ePUB (apto para móviles)
- Disponible en iOS y Android
Scala and Spark for Big Data Analytics
Md. Rezaul Karim, Sridhar Alla
Información del libro
Harness the power of Scala to program Spark and analyze tonnes of data in the blink of an eye!About This Book• Learn Scala's sophisticated type system that combines Functional Programming and object-oriented concepts• Work on a wide array of applications, from simple batch jobs to stream processing and machine learning• Explore the most common as well as some complex use-cases to perform large-scale data analysis with SparkWho This Book Is ForAnyone who wishes to learn how to perform data analysis by harnessing the power of Spark will find this book extremely useful. No knowledge of Spark or Scala is assumed, although prior programming experience (especially with other JVM languages) will be useful to pick up concepts quicker.What You Will Learn• Understand object-oriented & functional programming concepts of Scala• In-depth understanding of Scala collection APIs• Work with RDD and DataFrame to learn Spark's core abstractions• Analysing structured and unstructured data using SparkSQL and GraphX• Scalable and fault-tolerant streaming application development using Spark structured streaming• Learn machine-learning best practices for classification, regression, dimensionality reduction, and recommendation system to build predictive models with widely used algorithms in Spark MLlib & ML• Build clustering models to cluster a vast amount of data• Understand tuning, debugging, and monitoring Spark applications• Deploy Spark applications on real clusters in Standalone, Mesos, and YARNIn DetailScala has been observing wide adoption over the past few years, especially in the field of data science and analytics. Spark, built on Scala, has gained a lot of recognition and is being used widely in productions. Thus, if you want to leverage the power of Scala and Spark to make sense of big data, this book is for you.The first part introduces you to Scala, helping you understand the object-oriented and functional programming concepts needed for Spark application development. It then moves on to Spark to cover the basic abstractions using RDD and DataFrame. This will help you develop scalable and fault-tolerant streaming applications by analyzing structured and unstructured data using SparkSQL, GraphX, and Spark structured streaming. Finally, the book moves on to some advanced topics, such as monitoring, configuration, debugging, testing, and deployment.You will also learn how to develop Spark applications using SparkR and PySpark APIs, interactive data analytics using Zeppelin, and in-memory data processing with Alluxio.By the end of this book, you will have a thorough understanding of Spark, and you will be able to perform full-stack data analytics with a feel that no amount of data is too big.Style and approachFilled with practical examples and use cases, this book will hot only help you get up and running with Spark, but will also take you farther down the road to becoming a data scientist.
Preguntas frecuentes
Información
Collection APIs
- Scala collection APIs
- Types and hierarchies
- Performance characteristics
- Java interoperability
- Using Scala implicits
Scala collection APIs
- Easy to use: For example, it helps you eliminate the interference between iterators and collection updates. As a result, a small vocabulary consisting of 20-50 methods should be enough to solve most of your collection problem in your data analytics solution.
- Concise: You can use functional operations with a light-weight syntax and combine operations and, at the end, you will feel like that you're using custom algebra.
- Safe: Helps you deal with most errors while coding.
- Fast: most collection objects are carefully tuned and optimized; this enables you data computation in a faster way.
- Universal: Collections enable you to use and perform the same operations on any type, anywhere.
Types and hierarchies
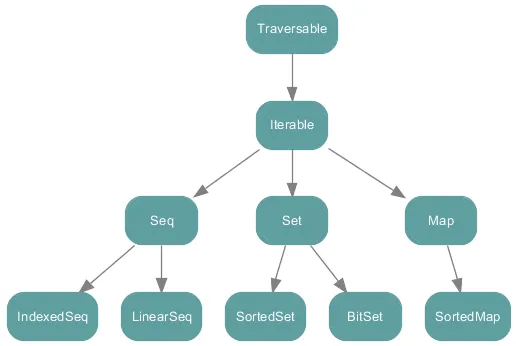
Traversable
def foreach[U](f: Elem => U): Unit