
Python Web Scraping Cookbook
Michael Heydt
- 364 páginas
- English
- ePUB (apto para móviles)
- Disponible en iOS y Android
Python Web Scraping Cookbook
Michael Heydt
Información del libro
Untangle your web scraping complexities and access web data with ease using Python scriptsAbout This Book• Hands-on recipes for advancing your web scraping skills to expert level.• One-Stop Solution Guide to address complex and challenging web scraping tasks using Python.• Understand the web page structure and collect meaningful data from the website with ease Who This Book Is ForThis book is ideal for Python programmers, web administrators, security professionals or someone who wants to perform web analytics would find this book relevant and useful. Familiarity with Python and basic understanding of web scraping would be useful to take full advantage of this book.What You Will Learn• Use a wide variety of tools to scrape any website and data—including BeautifulSoup, Scrapy, Selenium, and many more• Master expression languages such as XPath, CSS, and regular expressions to extract web data• Deal with scraping traps such as hidden form fields, throttling, pagination, and different status codes• Build robust scraping pipelines with SQS and RabbitMQ• Scrape assets such as images media and know what to do when Scraper fails to run• Explore ETL techniques of build a customized crawler, parser, and convert structured and unstructured data from websites• Deploy and run your scraper-as-aservice in AWS Elastic Container ServiceIn DetailPython Web Scraping Cookbook is a solution-focused book that will teach you techniques to develop high-performance scrapers and deal with crawlers, sitemaps, forms automation, Ajax-based sites, caches, and more.You'll explore a number of real-world scenarios where every part of the development/product life cycle will be fully covered. You will not only develop the skills to design and develop reliable, performance data flows, but also deploy your codebase to an AWS. If you are involved in software engineering, product development, or data mining (or are interested in building data-driven products), you will find this book useful as each recipe has a clear purpose and objective.Right from extracting data from the websites to writing a sophisticated web crawler, the book's independent recipes will be a godsend on the job. This book covers Python libraries, requests, and BeautifulSoup. You will learn about crawling, web spidering, working with AJAX websites, paginated items, and more. You will also learn to tackle problems such as 403 errors, working with proxy, scraping images, LXML, and more.By the end of this book, you will be able to scrape websites more efficiently and to be able to deploy and operate your scraper in the cloud.Style and approachThis book is a rich collection of recipes that will come in handy when you are scraping a website using Python.Addressing your common and not-so-common pain points while scraping website, this is a book that you must have on the shelf.
Preguntas frecuentes
Información
Making the Scraper as a Service Real
- Creating and configuring an Elastic Cloud trial account
- Accessing the Elastic Cloud cluster with curl
- Connecting to the Elastic Cloud cluster with Python
- Performing an Elasticsearch query with the Python API
- Using Elasticsearch to query for jobs with specific skills
- Modifying the API to search for jobs by skill
- Storing configuration in the environment
Creating an AWS IAM user and a key pair for ECS - Configuring Docker to authenticate with ECR
- Pushing containers into ECR
- Creating an ECS cluster
- Creating a task to run our containers
- Starting and accessing the containers in AWS
Introduction
Creating and configuring an Elastic Cloud trial account
How to do it
- Open your browser and navigate to https://www.elastic.co/cloud/as-a-service/signup. You will see a page similar to the following:

- Enter your email and press the Start Free Trial button. When the email arrives, verify yourself. You will be taken to a page to create your cluster:

- I'll be using AWS (not Google) in the Oregon (us-west-2) region in other examples, so I'll pick both of those for this cluster. You can pick a cloud and region that works for you. You can leave the other options as it is, and just press create. You will then be presented with your username and password. Jot those down. The following screenshot gives an idea of how it displays the username and password:
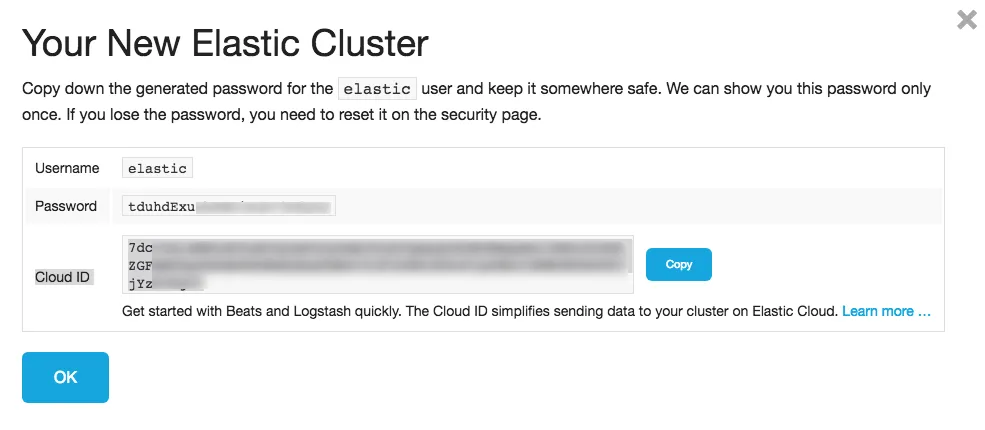
- Next, you will be presented with your endpoints. The Elasticsearch URL is what's important to us:

- And that's it - you are ready to go (at least for 14 days)!
Accessing the Elastic Cloud cluster with curl
How to do it
- When you signed up for Elastic Cloud, you were given various endpoints and variables, such as username and password. The URL was similar to the following:
https://<account-id>.us-west-2.aws.found.io:9243
- We'll use a slight variant of the following URL to communicate and authenticate with Elastic Cloud:
https://<username>:<password>@<account-id>.us-west-2.aws.found.io:9243
- Currently, mine is (it will be disabled by the time you read this):
https://elastic:tduhdExunhEWPjSuH73O6yLS@d7c72d3327076cc4daf5528103c46a27.us-west-2.aws.found.io:9243
- Basic authentication and connectivity can be checked with curl:
$ curl https://elastic:tduhdExunhEWPjSuH73O6yLS@7dc72d3327076cc4daf5528103c46a27.us-west-2.aws.found.io:9243
{
"name": "instance-0000000001",
"cluster_name": "7dc72d3327076cc4daf5528103c46a27",
"cluster_uuid": "g9UMPEo-QRaZdIlgmOA7hg",
"version": {
"number": "6.1.1",
"build_hash": "bd92e7f",
"build_date": "2017-12-17T20:23:25.338Z",
"build_snapshot": false,
"lucene_version": "7.1.0",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
Michaels-iMac-2:pems michaelheydt$
Connecting to the Elastic Cloud cluster with Python
Getting ready
How to do it
- Execute the file as a Python script:
$ python elasticcloud_starwars.py
- This will loop through up to 20 characters and drop them into the sw index with a document type of people. The code is straightforward (replace the URL with yours):
from elasticsearch import Elasticsearch
import requests
import json
if __name__ == '__main__':
es = Elasticsearch(
[
"https://elastic:tdu...