
Hands-On Web Scraping with Python
Perform advanced scraping operations using various Python libraries and tools such as Selenium, Regex, and others
Anish Chapagain
- 350 pages
- English
- ePUB (adapté aux mobiles)
- Disponible sur iOS et Android
Hands-On Web Scraping with Python
Perform advanced scraping operations using various Python libraries and tools such as Selenium, Regex, and others
Anish Chapagain
À propos de ce livre
Collect and scrape different complexities of data from the modern Web using the latest tools, best practices, and techniques
Key Features
- Learn different scraping techniques using a range of Python libraries such as Scrapy and Beautiful Soup
- Build scrapers and crawlers to extract relevant information from the web
- Automate web scraping operations to bridge the accuracy gap and manage complex business needs
Book Description
Web scraping is an essential technique used in many organizations to gather valuable data from web pages. This book will enable you to delve into web scraping techniques and methodologies.The book will introduce you to the fundamental concepts of web scraping techniques and how they can be applied to multiple sets of web pages. You'll use powerful libraries from the Python ecosystem such as Scrapy, lxml, pyquery, and bs4 to carry out web scraping operations. You will then get up to speed with simple to intermediate scraping operations such as identifying information from web pages and using patterns or attributes to retrieve information. This book adopts a practical approach to web scraping concepts and tools, guiding you through a series of use cases and showing you how to use the best tools and techniques to efficiently scrape web pages. You'll even cover the use of other popular web scraping tools, such as Selenium, Regex, and web-based APIs.By the end of this book, you will have learned how to efficiently scrape the web using different techniques with Python and other popular tools.
What you will learn
- Analyze data and information from web pages
- Learn how to use browser-based developer tools from the scraping perspective
- Use XPath and CSS selectors to identify and explore markup elements
- Learn to handle and manage cookies
- Explore advanced concepts in handling HTML forms and processing logins
- Optimize web securities, data storage, and API use to scrape data
- Use Regex with Python to extract data
- Deal with complex web entities by using Selenium to find and extract data
Who this book is for
This book is for Python programmers, data analysts, web scraping newbies, and anyone who wants to learn how to perform web scraping from scratch. If you want to begin your journey in applying web scraping techniques to a range of web pages, then this book is what you need! A working knowledge of the Python programming language is expected.
]]>
Foire aux questions
Informations
Section 1: Introduction to Web Scraping
- Chapter 1, Web Scraping Fundamentals
Web Scraping Fundamentals
- Why is there a growing need or demand for data?
- How are we going to manage and fulfill the requirement for data with resources from the World Wide Web (WWW)?
- Introduction to web scraping
- Understanding web development and technologies
- Data finding techniques
Introduction to web scraping
Understanding web development and technologies
HTTP
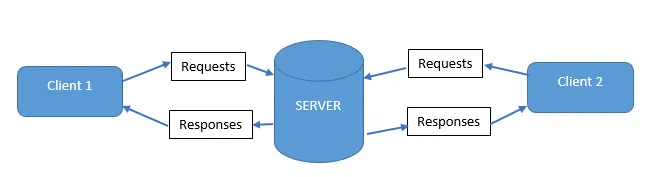
- GET: This is a common method for requesting information. It is considered a safe method, as the resource state is not altered. Also, it is used to provide query strings such as http://www.test-domain.com/, requesting information from servers based on the id and display parameters sent with the request.
- POST: This is used to make a secure request to a server. The requested resource state can be altered. Data posted or sent to the requested URL is not visible in the URL, but rather transferred with the request body. It's used...