
Deep Learning with Structured Data
Mark Ryan
- 264 pages
- English
- ePUB (adapté aux mobiles)
- Disponible sur iOS et Android
Deep Learning with Structured Data
Mark Ryan
À propos de ce livre
Deep Learning with Structured Data teaches you powerful data analysis techniques for tabular data and relational databases. Summary
Deep learning offers the potential to identify complex patterns and relationships hidden in data of all sorts. Deep Learning with Structured Data shows you how to apply powerful deep learning analysis techniques to the kind of structured, tabular data you'll find in the relational databases that real-world businesses depend on. Filled with practical, relevant applications, this book teaches you how deep learning can augment your existing machine learning and business intelligence systems.Purchase of the print book includes a free eBook in PDF, Kindle, and ePub formats from Manning Publications. About the technology
Here's a dirty secret: Half of the time in most data science projects is spent cleaning and preparing data. But there's a better way: Deep learning techniques optimized for tabular data and relational databases deliver insights and analysis without requiring intense feature engineering. Learn the skills to unlock deep learning performance with much less data filtering, validating, and scrubbing. About the book
Deep Learning with Structured Data teaches you powerful data analysis techniques for tabular data and relational databases. Get started using a dataset based on the Toronto transit system. As you work through the book, you'll learn how easy it is to set up tabular data for deep learning, while solving crucial production concerns like deployment and performance monitoring. What's inside When and where to use deep learning
The architecture of a Keras deep learning model
Training, deploying, and maintaining models
Measuring performance About the reader
For readers with intermediate Python and machine learning skills. About the author
Mark Ryan is a Data Science Manager at Intact Insurance. He holds a Master's degree in Computer Science from the University of Toronto. Table of Contents 1 Why deep learning with structured data?2 Introduction to the example problem and Pandas dataframes3 Preparing the data, part 1: Exploring and cleansing the data4 Preparing the data, part 2: Transforming the data5 Preparing and building the model6 Training the model and running experiments7 More experiments with the trained model8 Deploying the model9 Recommended next steps
Foire aux questions
Informations
1 Why deep learning with structured data?
- A high-level overview of deep learning
- Benefits and drawbacks of deep learning
- Introduction to the deep learning software stack
- Structured versus unstructured data
- Objections to deep learning with structured data
- Advantages of deep learning with structured data
- Introduction to the code accompanying this book
1.1 Overview of deep learning
- Fraudsters can find ways to work around the traditional rules-based approaches to fraud detection (http://mng.bz/emQw).
- A deep learning approach that is part of an industrial-strength pipeline—in which the model performance is frequently assessed and the model is automatically retrained if its performance drops below a given threshold—can adapt to changes in fraud patterns.
- A deep learning approach has the potential to provide near-real-time assessment of new transactions.
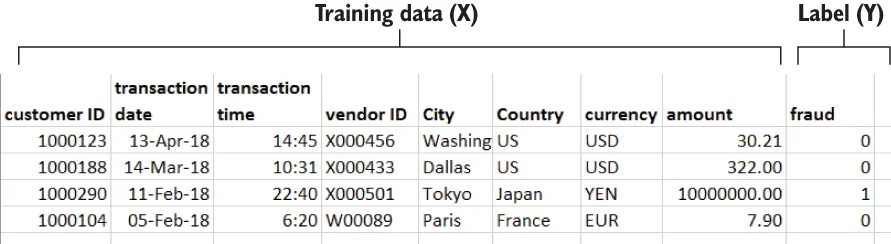
0 (meaning “not a fraud”), and that when one of our customers or vendors reports a fraudulent transaction, the value in the fraud column for that transaction in the table is set to 1.- Deep learning is a machine learning approach in which multilayer artificial neural networks are trained by setting weights and offsets at each layer by optimizing a loss function (the delta between the actual outcome [the values in the fraud column] and the predicted outcome) through the use of gradient-based optimization and backpropagation.
- Neural networks in a deep learning model have a series of layers, starting with the input layer, followed by several hidden layers, and culminating with an output layer.
- In each of these layers, the output of the previous layer (or, in the case of the first layer, the training data, which for our example is the dataset columns from customer ID, date, time, vendor ID, City, Country, currency and amount) goes through a series of operations (multiplication by a matrix of weights, addition of an offset [bias], and application of a nonlinear activation function) to produce the input for the next layer. In figure 1.2, each circle (node) has its own set of weights. The inputs are multiplied by those weights, the bias is added, and an activation function is applied to the result to produce the output that is taken in by the next layer.
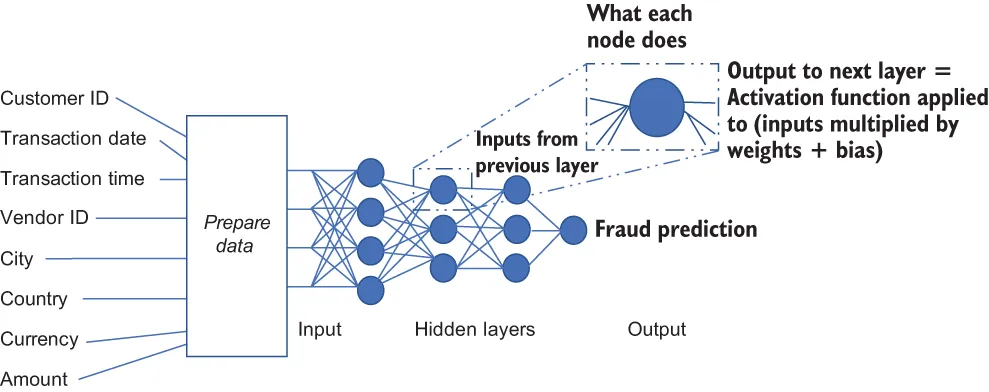 Figure 1.2 Multilayered neural networkThe final output layer generates the prediction of the model based on the input. In our example of predicting credit card fraud, the output indicates whether the model predicts a fraud (output of
Figure 1.2 Multilayered neural networkThe final output layer generates the prediction of the model based on the input. In our example of predicting credit card fraud, the output indicates whether the model predicts a fraud (output of1) or not a fraud (output of0) for a given transaction. - Deep learning works by iteratively updating the weights in the network to minimize the loss function (the function that defines the aggregate difference between the predictions of the model and the actual result values in the training dataset). As the weights are adjusted, the model’s predictions in aggregate get closer to the actual result values in the fraud column of the input table. With each training iteration, the weights are adjusted based on the gradient of the loss function.
- You can think of the gradient of the loss function as being roughly equivalent to the slope of a hill. If you make small, incremental steps in the direction opposite the slope of the hill, you will eventually get to the bottom of the hill. By making small changes to the weights in the direction opposite to the gradient for each iteration through the network, you reduce the loss function bit by bit. A process called backpropagation is used to get the gradient of the loss function, which can then be appl...