Edge Computing and Capability-Oriented Architecture
Haishi Bai, Boris Scholl
This is a test
This is a test
Partager le livre
164 pages
English
ePUB (adapté aux mobiles)
Disponible sur iOS et Android
eBook - ePub
Edge Computing and Capability-Oriented Architecture
Haishi Bai, Boris Scholl
Détails du livre
Aperçu du livre
Table des matières
Citations
À propos de ce livre
Fueled by ubiquitous computing ambitions, the edge is at the center of confluence of many emergent technological trends such as hardware-rooted trust and code integrity, 5G, data privacy and sovereignty, blockchains and distributed ledgers, ubiquitous sensors and drones, autonomous systems and real-time stream processing. Hardware and software pattern maturity have reached a tipping point so that scenarios like smart homes, smart factories, smart buildings, smart cities, smart grids, smart cars, smart highways are in reach of becoming a reality. While there is a great desire to bring born-in-the-cloud patterns and technologies such as zero-downtime software and hardware updates/upgrades to the edge, developers and operators alike face a unique set of challenges due to environmental differences such as resource constraints, network availability and heterogeneity of the environment.
The first part of the book discusses various edge computing patterns which the authors have observed, and the reasons why these observations have led them to believe that there is a need for a new architectural paradigm for the new problem domain. Edge computing is examined from the app designer and architect's perspectives. When they design for edge computing, they need a new design language that can help them to express how capabilities are discovered, delivered and consumed, and how to leverage these capabilities regardless of location and network connectivity. Capability-Oriented Architecture is designed to provide a framework for all of these.
This book is for everyone who is interested in understanding what ubiquitous and edge computing means, why it is growing in importance and its opportunities to you as a technologist or decision maker. The book covers the broad spectrum of edge environments, their challenges and how you can address them as a developer or an operator. The book concludes with an introduction to a new architectural paradigm called capability-based architecture, which takes into consideration the capabilities provided by an edge environment.
.
Foire aux questions
Comment puis-je résilier mon abonnement ?
Il vous suffit de vous rendre dans la section compte dans paramètres et de cliquer sur « Résilier l’abonnement ». C’est aussi simple que cela ! Une fois que vous aurez résilié votre abonnement, il restera actif pour le reste de la période pour laquelle vous avez payé. Découvrez-en plus ici.
Puis-je / comment puis-je télécharger des livres ?
Pour le moment, tous nos livres en format ePub adaptés aux mobiles peuvent être téléchargés via l’application. La plupart de nos PDF sont également disponibles en téléchargement et les autres seront téléchargeables très prochainement. Découvrez-en plus ici.
Quelle est la différence entre les formules tarifaires ?
Les deux abonnements vous donnent un accès complet à la bibliothèque et à toutes les fonctionnalités de Perlego. Les seules différences sont les tarifs ainsi que la période d’abonnement : avec l’abonnement annuel, vous économiserez environ 30 % par rapport à 12 mois d’abonnement mensuel.
Qu’est-ce que Perlego ?
Nous sommes un service d’abonnement à des ouvrages universitaires en ligne, où vous pouvez accéder à toute une bibliothèque pour un prix inférieur à celui d’un seul livre par mois. Avec plus d’un million de livres sur plus de 1 000 sujets, nous avons ce qu’il vous faut ! Découvrez-en plus ici.
Prenez-vous en charge la synthèse vocale ?
Recherchez le symbole Écouter sur votre prochain livre pour voir si vous pouvez l’écouter. L’outil Écouter lit le texte à haute voix pour vous, en surlignant le passage qui est en cours de lecture. Vous pouvez le mettre sur pause, l’accélérer ou le ralentir. Découvrez-en plus ici.
Est-ce que Edge Computing and Capability-Oriented Architecture est un PDF/ePUB en ligne ?
Oui, vous pouvez accéder à Edge Computing and Capability-Oriented Architecture par Haishi Bai, Boris Scholl en format PDF et/ou ePUB ainsi qu’à d’autres livres populaires dans Computer Science et Systems Architecture. Nous disposons de plus d’un million d’ouvrages à découvrir dans notre catalogue.
As the dust settled, the crew of the Invincible woke up from their deep sleep and gazed through the fogged portholes at the barren landscape of Regis III. Their mission was to investigate the loss of Condor, a sister ship, on this seemingly lifeless planet. To their surprise, they soon discovered that the planet was inhabited by insect-like tiny machines that moved in swarms. When they were in small groups, they were pretty much harmless. However, when they felt threatened, they could form huge clouds and overwhelm their opponents with swift attacks and huge surges of electromagnetic interference that apparently wiped out not only the electronics but also memories.
As the Invincible crew stepped into their unknown fate in Stanisław Lem's 1964 science fiction, the Invincible, the situation on planet Earth in a parallel universe was far less devastating. Here on Earth, people have been fascinated by an idea of Smartdust, which is comprised with tiny microelectromechanical systems (MEMS) that can be scattered in the real world without being noticed. They can remain dormant for months or even years and be activated by an external energy source (such as a probing laser from a flyby airplane). The amount of the energy carried by the laser beam is just enough to wake them up, collect some environmental data and send the data back to the prober. They can be used to plot accurate local maps of chemical or radioactive contaminations, temperature patterns, soil moisture and PH values, ground vibrations and many other environmental information.
Smartdust represents the philosophy of the initial wave of edge computing – to extract value from connected data sentinels. Many Internet of Things (IoT) projects are centered around this idea. In such projects, devices are used as collectors of data, which are then fed into a data pipeline that aggregates data from multiple devices and performs various analyses to extract values, such as pattern and anomaly detection, trend analysis, prediction and optimization. Because this pattern is so dominant in edge computing, some believe “edge” simply means “edge of cloud”. As we explained in Chapter 1, this is a rather limited view of edge computing. However, it does indicate that a close collaboration between cloud and edge plays an important role in many edge computing solutions.
In this chapter, we’ll examine several common patterns of edge-cloud collaborations. Especially, we’ll focus on how data and compute are concentrated toward the cloud in these patterns. In the next chapter, we’ll examine the other direction – how compute and data are dispersed into edge.
3.1 DATA COLLECTION PATTERNS
The main goal of this pattern is to facilitate data collection from edge devices to cloud. Although there are often device management, configuration management and command & control aspects associated with these solutions, this pattern differs from others because it's not focused to push compute to edge but to get data back to cloud.
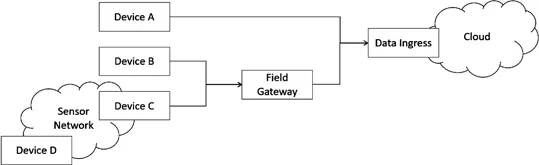
Figure 3.1 illustrates a high-level architecture of the data collection pattern. On the cloud side, a data ingress endpoint is configured to accept data from devices. This ingress endpoint is invoked by either direct invocations or a messaging bus. Devices are connected to the ingress in several different ways. Device A is directly connected to the ingress endpoint; Device B and Device C are connected through a field gateway (or a base station), which aggregates data from multiple sensors and provides additional capabilities such as batching, ordering and filtering. Finally, Device D's connection is bridged by a local sensor network such as Zigbee, wireless sensor network, Narrowband Internet of Things (NB-IoT) and LoRaWAN before it reaches either the field gateway or the cloud.
Figure 3.1Data collection pattern.
Next, we’ll examine some of the popular data collection products and techniques and examine how they establish and maintain scalable and reliable data pipelines to collect data from edge to cloud.
3.1.1 Data collection through messaging
Collecting device data through messaging is a popular choice. Systems like Azure IoT Edge, AWS IoT Core and Apache Kafka all support collecting device data as messages. And there are widely adopted messaging protocols such as Advanced Message Queueing Protocol (AMQP) and Message Queuing Telemetry Transport (MQTT).
In such systems, a publish-subscribe pattern is often used to decouple data sources and data consumers. Data sources publish messages to topics. And data consumers subscribe to topics that they are interested in. Messages are queued on topics for consumers to pick up. Messages are appended to the end of topic queues, creating hot write zones on disks. For better scalability, topics can be segmented into multiple partitions. This allows more efficient parallel writes to the same topic. However, the price is that ordering of messages across partitions is often not guaranteed in such cases.
On the consumer side, a consumer maintains a persistent marker that points to the last message it has processed. The marker allows a consumer to pick where it has left off – when it crashed, for example. Further, multiple consumers can be organized into a consumer group. Consumers in a consumer group read from the same topic partition. This allows a partition to be drained quicker. The consumers in the same group also serve as backups of each other. When one consumer fails, others can keep the message pipe going.
Most messaging systems ensure at-least-once delivery, which means any message is guaranteed to be delivered to a consumer at least once (but could also be delivered multiple times). In some cases, the delivery guarantee can be relaxed to best-effort, in which messages can be discarded after a few failed delivery attempts. In systems that require near real-time reactions to temporal data, using a best-effort policy can help the system from becoming too bogged down by a few malformed messages or spotty networks. Generally speaking, achieving exactly-once delivery is very difficult in a fault-tolerant system. Hence consumers need to be designed to handle duplicated messages gracefully, such as by implementing stateful idempotent functions that can be invoked with the same input many times and always generate the same output. For completeness, there's also an at-most-once delivery, in which a message may or may not be delivered but never duplicated. Think of sending a package to your friend – the package may never arrive, and it will never be duplicated.
Messages are sent to topics either in batches or as a stream (or batch-of-1) of messages. Batches help to improve throughput and streams helps to reduce latency. Based on your scenario, you may choose between the two modes and adjust batch sizes to achieve the best result.
The messaging system decouples message sender and consumers, in the sense that senders and consumers don’t directly invoke each other. They can be scaled and hosted independently from each other. And replacing a sender or consumer (even dynamically) doesn’t affect the other party. However, message senders and consumers are still coupled by data schemas, as consumers need to understand what the senders are sending to make sense of the data. Many messaging systems have envelops or metadata associated with message payloads so that consumers can infer important information about the message payload – such as schema version – before attempting to process the message.
When a messaging system is used, it's required to be secured, reliable and scalable. Maintaining a production-grade messaging system is not an easy task. Cloud-based message systems hide most of the operational complexity from you and offer highly scalable and reliable messaging buses for your solutions. Some messaging systems are also integrated with device management systems so that devices can authenticate with the backend system with provisioned device identities. All these characteristics make cloud-based messaging systems a preferred choice of IoT scenarios.
3.1.2 Data collection through ingress endpoints
Data collection can also be performed through direct service invocations to a data ingress endpoint through common protocols such as Hypertext Transfer Protocol (HTTP) and File Transfer Protocol (FTP). This approach is most suitable for situations in which you need to upload large data files that exceed the size limit of common messaging systems.
Dedicated ingress data points are also used for streaming scenarios, such as streaming surveillance camera feeds to cloud through media streaming protocols such as Real-Time Streaming Protocol (RTSP), Real-Time Messaging Protocol (RTMP), HTTP Live Streaming (HLS) and MPEG-DASH.
Using a messaging system often needs a client library that supports the specific protocol or backend. Such libraries are not always available on all devices. On the other hand, for internet-enabled devices, making Transmission Control Protocol (TCP) or HTTP connection is a fundamental capability. Using an ingress endpoint with REST API lowers the bar of a device connecting to the backend. A REST API is efficient for scenarios of many devices making occasional connections to the backend.
An ingress endpoint can be scaled out by simple load balancing or partitioning. In the case of simple load balancing, the ingress endpoint is backed by multiple service instances behind a load balancer, and client requests are distributed evenly to backend instances. In the case of partitioning, service instances are partitioned by certain key values and matching data elements are routed to corresponding partitions.
An ingress service is often stateless, which means it doesn’t save any local states. To ensure availability of an ingress endpoint, multiple ingress service instances are used as backups of each other. Once the data is received, a service instance often saves it to a high-available data store, such as a replicated key-value store, for persistence. Please see the next section for more details on how data continues with a server-side pipeline once it's ingested.
Ingress endpoints are sometimes used in conjunction with a messaging system. In such a configuration, the ingress endpoint provides a simpler REST API for the devices. It also abstracts the messaging platform and messaging protocol from the devices.
3.1.3 Bulk data transportation and in-context data processing
The bulk data transportation pattern is originally used to allow customers to transfer large amount (terabytes or petabytes) of data through a specialized data transfer device that can be physically shipped between the customers and the cloud. Later, the pattern evolved to allow certain compute tasks to be carried out on these devices locally to provide fast, private, in-context data processing.
Amazon Web Services (AWS) Snowball devices, including Snowmobile, Snowball and Snowball Edge, are pre-built, secured hardware with storage and compu...