Phishing Detection Using Content-Based Image Classification
Shekhar Khandelwal, Rik Das
This is a test
This is a test
Partager le livre
130 pages
English
ePUB (adapté aux mobiles)
Disponible sur iOS et Android
eBook - ePub
Phishing Detection Using Content-Based Image Classification
Shekhar Khandelwal, Rik Das
Détails du livre
Aperçu du livre
Table des matières
Citations
À propos de ce livre
Phishing Detection Using Content-Based Image Classification is an invaluable resource for any deep learning and cybersecurity professional and scholar trying to solve various cybersecurity tasks using new age technologies like Deep Learning and Computer Vision. With various rule-based phishing detection techniques at play which can be bypassed by phishers, this book provides a step-by-step approach to solve this problem using Computer Vision and Deep Learning techniques with significant accuracy.
The book offers comprehensive coverage of the most essential topics, including:
Programmatically reading and manipulating image data
Extracting relevant features from images
Building statistical models using image features
Using state-of-the-art Deep Learning models for feature extraction
Build a robust phishing detection tool even with less data
Dimensionality reduction techniques
Class imbalance treatment
Feature Fusion techniques
Building performance metrics for multi-class classification task
Another unique aspect of this book is it comes with a completely reproducible code base developed by the author and shared via python notebooks for quick launch and running capabilities. They can be leveraged for further enhancing the provided models using new advancement in the field of computer vision and more advanced algorithms.
Foire aux questions
Comment puis-je résilier mon abonnement ?
Il vous suffit de vous rendre dans la section compte dans paramètres et de cliquer sur « Résilier l’abonnement ». C’est aussi simple que cela ! Une fois que vous aurez résilié votre abonnement, il restera actif pour le reste de la période pour laquelle vous avez payé. Découvrez-en plus ici.
Puis-je / comment puis-je télécharger des livres ?
Pour le moment, tous nos livres en format ePub adaptés aux mobiles peuvent être téléchargés via l’application. La plupart de nos PDF sont également disponibles en téléchargement et les autres seront téléchargeables très prochainement. Découvrez-en plus ici.
Quelle est la différence entre les formules tarifaires ?
Les deux abonnements vous donnent un accès complet à la bibliothèque et à toutes les fonctionnalités de Perlego. Les seules différences sont les tarifs ainsi que la période d’abonnement : avec l’abonnement annuel, vous économiserez environ 30 % par rapport à 12 mois d’abonnement mensuel.
Qu’est-ce que Perlego ?
Nous sommes un service d’abonnement à des ouvrages universitaires en ligne, où vous pouvez accéder à toute une bibliothèque pour un prix inférieur à celui d’un seul livre par mois. Avec plus d’un million de livres sur plus de 1 000 sujets, nous avons ce qu’il vous faut ! Découvrez-en plus ici.
Prenez-vous en charge la synthèse vocale ?
Recherchez le symbole Écouter sur votre prochain livre pour voir si vous pouvez l’écouter. L’outil Écouter lit le texte à haute voix pour vous, en surlignant le passage qui est en cours de lecture. Vous pouvez le mettre sur pause, l’accélérer ou le ralentir. Découvrez-en plus ici.
Est-ce que Phishing Detection Using Content-Based Image Classification est un PDF/ePUB en ligne ?
Oui, vous pouvez accéder à Phishing Detection Using Content-Based Image Classification par Shekhar Khandelwal, Rik Das en format PDF et/ou ePUB ainsi qu’à d’autres livres populaires dans Informatique et Ingénierie de l'informatique. Nous disposons de plus d’un million d’ouvrages à découvrir dans notre catalogue.
Phishing is a cybercrime intended to trap innocent web users into a counterfeit website, which is visually similar to its legitimate counterpart. Initially, users are redirected to phishing websites through various social and technical routing techniques. Unaware of the illegitimacy of the website, the users may then provide their personal information such as user id, password, credit card details or bank account details, to name a few. The phishers use such information to steal money from banks, damage a brand’s image or even commit graver crimes like identity theft. Although many phishing detection and prevention techniques are available in the existing literature, the advent of smart machine learning and deep learning methods has widened their scope in the cyber-security world.
Structure
In this chapter, we will cover the following topics:
Basics of phishing in cybersecurity
Phishing detection techniques
List (whitelist/blacklist)-based
Heuristics (predefined rules)-based
Visual similarity-based
Race between phishers and anti-phishers
Computer vision-based phishing detection approach
Objective
After studying this chapter, you should know what phishing is and how it affects everyone who has a web footprint. You will learn about the various ways phishers attack web users and how users can protect themselves from phishing attacks. You will also know the various phishing detection mechanisms that play a vital role in protecting web users from phishing attacks.
Basics of Phishing in Cybersecurity
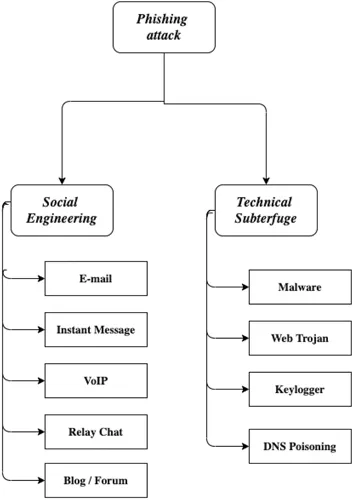
Phishing is a term derived from fishing, by replacing “f” with “ph”, but contextually they mean the same (Phishing Definition & Meaning | What Is Phishing?, n.d.). Just as fish get trapped in fishing nets, so too are innocent web users being trapped by phishing websites. Phishing websites are counterfeit websites that are visually similar to their legitimate counterparts. Web users are redirected to phishing websites by various means. Figure 1.1 depicts the various techniques employed by phishers to circulate spam messages that contain links to phishing websites.
FIGURE 1.1 Types of phishing attacks.
Jain and Gupta (2017) stated that spreading infected links is the starting point of any phishing attack. Once users have received the infected links in their inbox through any of the phishing attack mechanisms shown in Figure 1.1, whether they click on those links or not depends on the users’ awareness. Hence, at the outset, user awareness is the most important, yet most ignored, anti-phishing mechanism.
But to protect users from phishing attacks, anti-phishers have explored many technical anti-phishing mechanisms by considering even novice and technically inept users.
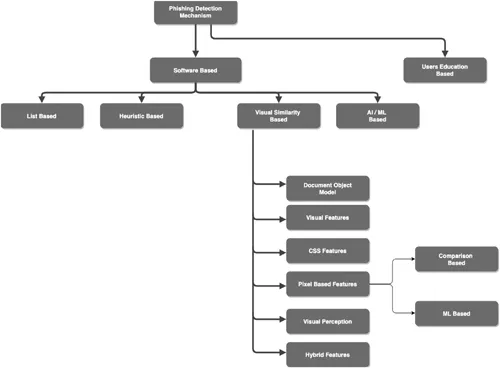
Phishing Detection Techniques
Phishing detection mechanisms are broadly categorized into four groups, as depicted in Figure 1.2 (Khonji et al., 2013):
FIGURE 1.2 Phishing detection mechanisms.
List (whitelist/blacklist)-based
Heuristics (pre-defined rules)-based
Visual similarity-based
AI/ML-based
List (Whitelist/Blacklist)-Based
In a list-based anti-phishing mechanism, a whitelist and blacklist of URLs are created and are compared against a suspicious website URL to conclude whether the website under scrutiny is a phishing website or a legitimate one (Jain & Gupta, 2016) (Prakash et al., 2010).
There are various limitations with the list-based approach, namely:
It is dependent on a third-party service provider that captures and maintains such lists, like Google safe browsing API (Google Safe Browsing | Google Developers, n.d.).
Adding a newly deployed phishing website to the white/blacklist is a process that takes time. First such a website has to be identified, and then it has to be listed. Since the average lifetime of a phishing website is 24–32 hours, hence zero-day phishing attacks, this is a serious limitation (Zero-Day (Computing) – Wikipedia, n.d.).
Heuristics (Pre-Defined Rules)-Based
In heuristic-based approaches, various website features like image, text, URL and DNS records are extracted and used to build a rule-based engine or a machine learning-based classifier to classify a given website as phishing or legitimate. Although heuristic-based approaches are among quite effective anti-phishing mechanisms, some of their drawbacks have been pointed out by Varshney et al. (2016):
The time and computational resources required for training are too high.
Heuristic-based applications cannot be used as a browser plugin.
The approach would be ineffective once scammers discovered the key features that can be used to bypass the rules.
Visual Similarity-Based
Visual similarity-based techniques are very useful in detecting phishing since phishing websites look similar to their legitimate counterparts. These techniques use visual features like text content, text format, DOM (Document Object Model) features, CSS features, website images, etc., to detect phishing. Here, DOM-, CSS-, HTML tags- and pixel-based features are compared to their legitimate counterparts in order to make a decision.
Within pixel-based techniques, there are two broad categories through which phishing detection is achieved. One approach is through comparison of visual signatures of suspicious website images with the stored visual signatures of legitimate websites. For example, hand-crafted image features like SIFT (Scale Invariant Feature Transform) (Lowe, 2004), SURF (Speeded Up Robust Features) (Bay et al., 2006), HOG (Histogram of Oriented Gradient) (Li et al., 2016), LBP (Local Binary Patterns) (Nhat & Hoang, 2019), DAISY (Tola et al., 2010) and MPEG7 (Rayar, 2017) are extracted from the legitimate websites and stored in a local datastore, which is used as a baseline for comparing similar features from the websites under scrutiny. And based on the comparison result, the phishing website is classified. Another approach is machine learning- or deep learning classifier-based, where image features of phishing and legitimate webpages are extracted and used to build a classifier for phishing detection.
Race between Phishers and Anti-Phishers
Phishers are continually upgrading their skills and devising new and innovative ways to bypass all the security layers and deceive innocent users. For example, many heuristic-based approaches validate if the website under suspicion is SSL-enabled or not, to determine whether it is a legitimate website or a phishing website. However, nowadays, the number of phishing websites hosted on HTTPS is also increasing significantly.
Similarly, for other significant predictors of a phishing website, phishers may find ways to bypass all the rules employed to detect phishing, which is evident from the upward trend of phishing attacks attempted in recent years. Hence, if phishers find a way to bypass list-based, heuristic-based and hybrid anti-phishing detection mechanisms, to redirect the users to the phishing website, then the image processing-based anti-phishing techniques play a vital role in providing the final security layer to the web users. In this book, we propose numerous machine learning and deep learning methods that manually extract features using computer vision techniques for phishing detection. However, there are two major limitations of these methods. First, these methods utilize a comparison-based technique that requires creating a large datastore of baseline values of legitimate websites. Second, these methods rely on manual hand-crafted feature extraction techniques.
Studies and statistics suggest that phishing is still a pressing issue in the world of cybercrime. Despite all the research, innovations and developments made in phishing detection mechanisms, revenue losses through phishing attacks are humongous, and therefore there is a pressing need to continue research on various aspects of phishing, as anti-phishers are in an arms race with phishers. And in order to win this race, anti-phishers need to think outside the box and close all the doors before phishers enter users’ premises for theft.
Assume that phishers are able to make users bypass all the list-based, heuristic-based and user awareness-based approaches, and finally made the user to land on the phishing website. At this stage, by analyzing the website image, using image processing techniques to classify whether the website in question is legitimate or phishing, can be considered as a final resort to warn users for phishing attack.
Additionally, list-based approaches cannot protect users from zero-day attacks, and heuristics-based approaches are only go...