![]()
PARTIE 1
Les modèles de calcul de l’écosystème Hadoop
![]()
1
Les modèles de calcul batch
Diviser pour mieux régner.
Le calcul dans un cluster exige que toutes les requêtes qui y arrivent soient totalement parallèles, c’est-à-dire que les tâches puissent s’exécuter de façon indépendante afin d’être réparties sur les nœuds du cluster. Si ce n’est pas le cas, il est impossible d’utiliser un cluster, encore moins un cluster Hadoop. Avant de penser à Hadoop, il faut donc commencer par se demander si le problème est parallélisable.
Par définition, tous les problèmes ne sont pas complètement parallélisables ; Google a créé le MapReduce pour répondre à des problématiques qui sont embarrasingly parallel. Contrairement à ce qu’on pourrait croire, cela ne veut pas dire « embarrassantes à paralléliser », mais plutôt « parallélisables à l’excès » : le MapReduce a été créé pour gérer l’exécution des problèmes qui sont très simples à paralléliser.
Un « problème facilement parallélisable » est un programme qui ne demande aucun effort particulier pour être découpé en tâches indépendantes. Par définition, ce type de problèmes s’exécute en batch, ce qui est plutôt une bonne nouvelle, puisque – dans la majorité des problématiques impliquant une grosse volumétrie des données – ces dernières ont une structure extrêmement régulière et qu’il n’y a pas d’exigence particulière sur les temps de réponse. Des exemples de telles problématiques incluent l’indexation des pages web, le reporting périodique, l’interrogation des modèles relationnels de données, les tests de performance, l’interrogation de graphes et l’analyse textuelle. Le MapReduce offre l’opportunité d’exploiter le parallélisme sur ces types de problématiques.
Cependant, toutes les problématiques ne sont pas simples à paralléliser. Les travaux d’apprentissage statistique, par exemple, exigent le passage itératif de l’algorithme sur les données, ce qui rend l’utilisation du MapReduce inadapté. Dans ce chapitre, nous allons vous expliquer le fonctionnement du MapReduce et des modèles alternatifs qui le complètent, en l’occurrence Mahout et Hama. L’objectif est que vous compreniez comment un problème « embarrasingly parallel » s’exécute dans le cluster.
Principes du traitement parallèle en batch
Avant d’entrer dans les détails du fonctionnement d’un modèle de calcul, il faut comprendre la notion de batch, puisque pratiquement tous les problèmes « embarrasingly parallel » s’exécutent sur ce mode.
Dans un ordinateur, l’endroit où les données sont stockées a une incidence vitale sur la capacité de paralléliser le traitement.
•Dans l’ordinateur, les données sont stockées soit sur le disque dur, soit en mémoire centrale (RAM). Lorsque les données sont chargées en RAM, le traitement est plus rapide, mais il est très difficile à paralléliser. De plus, compte tenu de la taille limitée de la RAM, le volume de données qu’on peut y analyser est limité.
Lorsqu’on traite les données à partir de la RAM, on fait de l’in-memory processing ou traitement en mémoire.
•Si les données sont stockées sur le disque dur, les traitements sont faciles à paralléliser ; on pourra traiter de plus gros volumes, mais les temps de réponse des traitements seront plus longs.
Lorsqu’on effectue un traitement à partir du disque dur, on fait ce qu’on appelle techniquement du batch processing, c’est-à-dire du traitement par lots ou traitement sur disque.
Dans ce chapitre, nous nous intéresserons aux principes du batch processing et à son impact sur le parallélisme des calculs, avant d’entrer dans les détails de l’in-memory processing au chapitre suivant.
Le traitement sur disque ou batch processing
Pour comprendre le traitement sur disque, il faut connaître les principes fondamentaux du traitement des données dans un ordinateur. Par principes, nous entendons des lois qui ne changent pas, ni avec le temps, ni avec la technologie. Quatre principes régissent le traitement de données dans un ordinateur.
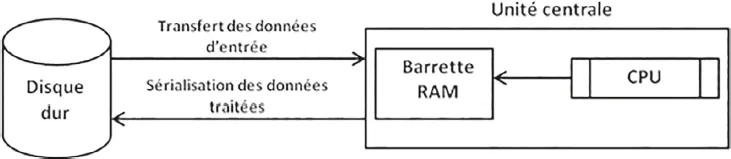
Figure 1-1 – Architecture du traitement des données dans un ordinateur
•1er principe : tout traitement informatique des données implique toujours la participation de trois composants de l’ordinateur : le disque dur, la mémoire centrale et le microprocesseur.
Comme le montre la figure 1-1, au départ de tout traitement informatique, il y a la donnée (par ricochet, le fichier contenant les données). Initialement stockée sur le disque dur, elle est ensuite transférée (on dit « chargée » ou « montée ») vers la mémoire centrale de l’ordinateur appelée RAM (Random Access Memory – mémoire à accès direct ou mémoire vive). Physiquement, la RAM a la forme d’une barrette. C’est à elle qu’on fait référence quand on parle de « mémoire ». Par la suite, la CPU (Central Processing Unit, ou microprocesseur) effectue le traitement spécifié par l’utilisateur sur les données dans la RAM. Enfin, les données traitées sont renvoyées sur le disque dur ; on dit qu’elles sont sérialisées ou qu’on les fait persister. En effet, contrairement à la RAM dont le stockage temporaire induit l’effacement des données après mise hors tension de l’ordinateur, le disque dur, quant à lui, conserve les données traitées.
•2e principe : le microprocesseur traite toujours les données à partir de la RAM. Toujours !
Le microprocesseur se rend toujours dans la RAM pour effectuer les traitements (il y a accès directement) ; il ne peut pas recevoir directement les données venant du disque dur.
•3e principe : la mémoire RAM garde son contenu le temps d’une session.
Au redémarrage de l’ordinateur, son contenu est vidé. Cela signifie que toute donnée en RAM, traitée ou non, doit être conservée sur le disque dur, sinon elle sera supprimée au démarrage de l’ordinateur. La RAM n’a pas été prévue pour un stockage permanent,...