Si vous avez lu la partie précédente, vous savez désormais comment construire de beaux modèles de machine learning. Vous l’avez vu, ce n’est pas si difficile et vous vous sentez certainement prêt à aller en découdre sur l’un des challenges Kaggle en cours. Mais attention, prenez encore quelques instants pour lire ce qui suit afin d’éviter de tomber dans l’un des pièges classiques du débutant. Souvenez-vous d’un phénomène que nous avons évoqué précédemment, notamment lorsque nous avons parlé de la régression polynomiale : l’overfitting.
En effet, il est souvent très facile de construire un modèle qui restitue très bien les données utilisées pour son estimation. Il est néanmoins bien plus difficile de faire en sorte que ce modèle puisse se généraliser, c’est-à-dire qu’il soit capable de prédire de façon satisfaisante de nouvelles observations, non utilisées lors du calcul du modèle. Pour trouver un juste équilibre entre apprentissage du modèle et capacité prédictive, il est indispensable de mettre en place un dispositif qui permette d’évaluer globalement la qualité d’un modèle.
La présentation de ce dispositif est l’objet de ce chapitre, composé de deux parties. La première introduit la notion de validation croisée, qui est un dispositif d’évaluation d’un modèle ; la seconde présente un ensemble d’indicateurs (aussi appelés métriques de performance) que vous pourrez utiliser pour mesurer effectivement la qualité de vos modèles.
À partir d’un jeu de données initial, que feriez-vous pour à la fois constituer un modèle et tester sa capacité prédictive sur des données non utilisées pour la modélisation (sans attendre de nouvelles observations, bien sûr !) ? La première réponse qui vient à l’esprit est assez évidente : diviser les données en deux groupes. L’un des groupes est utilisé pour la modélisation, l’autre est utilisé pour effectuer une prévision sur des données « fraîches ». C’est effectivement l’approche de base que l’on peut adopter. On crée un échantillon d’entraînement, sur lequel on va constituer le modèle, et un échantillon de test, sur lequel on va tester le modèle. Pour évaluer la qualité du modèle et de sa performance en prévision, on utilise une métrique de performance P (nous en reparlerons dans la deuxième partie de ce chapitre). Bien évidemment, on se doute que Ptest sera inférieur à Pentraînement. En pratique, on a l’habitude de prendre 70 % des données pour l’échantillon d’entraînement (appelons-le mentraînement) et 30 % des données pour l’échantillon de test (mtest).
Voilà pour l’approche de base… Mais si on allait plus loin ? En effet, on pourrait avoir envie d’utiliser cette séparation des données pour faire le meilleur modèle possible. On pourrait ainsi essayer différents choix de variables, plusieurs paramétrages d’un modèle (rappelez-vous les différentes manières de customiser les modèles) sur mentraînement et voir lequel performe le mieux sur mtest. C’est une idée effectivement perspicace, puisqu’elle nous permettrait de trouver celui, parmi tous les possibles, qui va maximiser Ptest (car c’est généralement ça que l’on attend d’un modèle). De plus, comme l’indique Hyndman dans son blog1, c’est une approche pragmatique pour choisir un modèle : efficace, concrète, et bien plus simple que l’emploi de tests statistiques de comparaison de modèles.
Néanmoins, pourrait-on alors dire à juste titre qu’on a bien testé que le modèle se généralise bien ? Pas vraiment, puisqu’il aurait été choisi de façon à maximiser la qualité de prévision sur mtest, donc il ne serait plus complètement vrai d’affirmer qu’il a été testé sur des données toutes fraîches et innocentes !
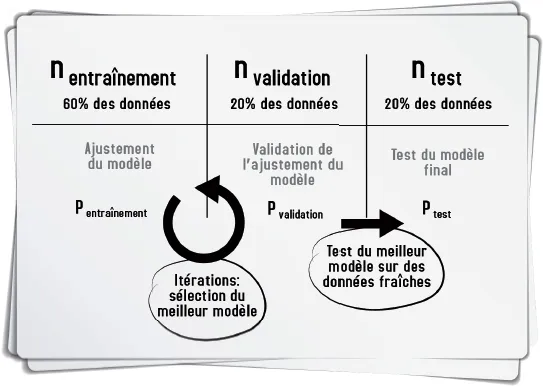
Pour sortir de ce dilemme, le data scientist choisit généralement de diviser ses données en trois :
• un jeu d’entraînement, bien sûr (mentraînement) ;
• un jeu dit de validation (mvalidation) : celui-ci va être utilisé pour tester les différents modèles paramétrés sur mentraînement (il remplace le mtest précédent) ;
• et un vrai jeu de test (mtest), qu’on garde de côté et qui ne sera utilisé que tout à la fin du processus de modélisation, afin de tester le plus honnêtement possible la capacité de généralisation du modèle retenu.
La qualité de l’ajustement ou de la prévision est calculée pour chacun des jeux de données, à partir de la métrique P retenue. En pratique, on prend souvent 60 % des données pour mentraînement, 20 % pour mvalidation et 20 % pour mtest. Ces principes sont résumés dans la figure 14-1.
Comme l’explique Hyndman dans son blog déjà cité, ces questions de séparation des données préoccupent plus les praticiens du machine learning que les statisticiens plus traditionnels. Cela peut s’entrendre : l’objectif du statisticien est avant tout de comprendre les processus stochastiques à l’œuvre dans les données, en essayant de contrôler les effets des variables du modèle. En machine learning, on se préoccupe moins de ces questions que de la capacité du modèle à faire la meilleure prédiction possible sur de nouvelles données, quitte à utiliser un modèle boîte noire.
La mécanique de la validation peut sembler bien évidente, pour ne pas dire basique : on coupe le jeu de données en trois paquets de données pour entraîner, valider et tester. En réalité, il existe beaucoup d’alternatives permettant de sophistiquer cette approche : on parle alors de validation croisée.