
Hands-On Convolutional Neural Networks with TensorFlow
Solve computer vision problems with modeling in TensorFlow and Python.
Iffat Zafar, Giounona Tzanidou, Richard Burton, Nimesh Patel, Leonardo Araujo
- 272 pages
- English
- ePUB (adapté aux mobiles)
- Disponible sur iOS et Android
Hands-On Convolutional Neural Networks with TensorFlow
Solve computer vision problems with modeling in TensorFlow and Python.
Iffat Zafar, Giounona Tzanidou, Richard Burton, Nimesh Patel, Leonardo Araujo
À propos de ce livre
Learn how to apply TensorFlow to a wide range of deep learning and Machine Learning problems with this practical guide on training CNNs for image classification, image recognition, object detection and many computer vision challenges.
Key Features
- Learn the fundamentals of Convolutional Neural Networks
- Harness Python and Tensorflow to train CNNs
- Build scalable deep learning models that can process millions of items
Book Description
Convolutional Neural Networks (CNN) are one of the most popular architectures used in computer vision apps. This book is an introduction to CNNs through solving real-world problems in deep learning while teaching you their implementation in popular Python library - TensorFlow. By the end of the book, you will be training CNNs in no time!
We start with an overview of popular machine learning and deep learning models, and then get you set up with a TensorFlow development environment. This environment is the basis for implementing and training deep learning models in later chapters. Then, you will use Convolutional Neural Networks to work on problems such as image classification, object detection, and semantic segmentation.
After that, you will use transfer learning to see how these models can solve other deep learning problems. You will also get a taste of implementing generative models such as autoencoders and generative adversarial networks.
Later on, you will see useful tips on machine learning best practices and troubleshooting. Finally, you will learn how to apply your models on large datasets of millions of images.
What you will learn
- Train machine learning models with TensorFlow
- Create systems that can evolve and scale during their life cycle
- Use CNNs in image recognition and classification
- Use TensorFlow for building deep learning models
- Train popular deep learning models
- Fine-tune a neural network to improve the quality of results with transfer learning
- Build TensorFlow models that can scale to large datasets and systems
Who this book is for
This book is for Software Engineers, Data Scientists, or Machine Learning practitioners who want to use CNNs for solving real-world problems. Knowledge of basic machine learning concepts, linear algebra and Python will help.
Foire aux questions
Informations
Image Classification in TensorFlow
 |  |  |  |  |  |  |  |  |  |
- A look at the loss functions used for classification
- The Imagenet and CIFAR datasets
- Training a CNN to classify the CIFAR dataset
- Introduction to the data API
- How to initialize your weights
- How to regularize your models to get better results
CNN model architecture
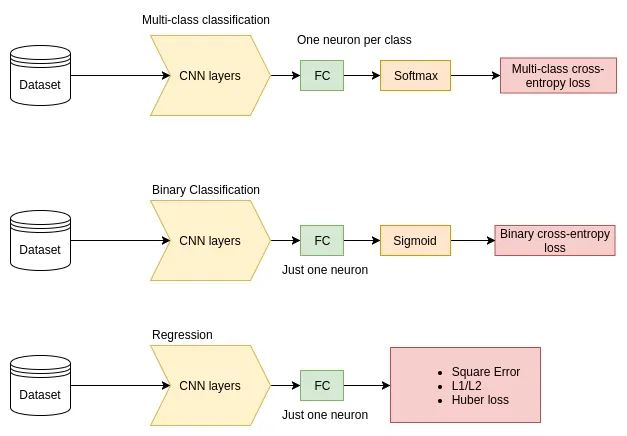
Cross-entropy loss (log loss)


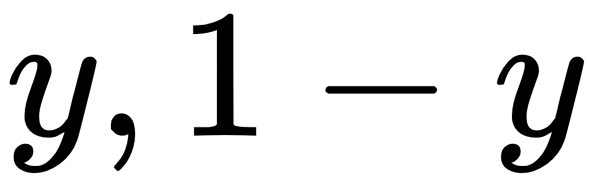

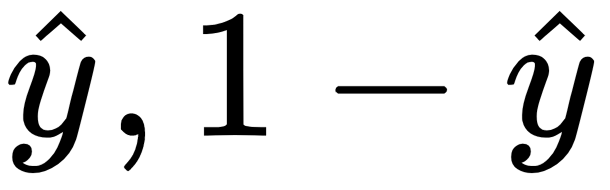

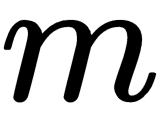

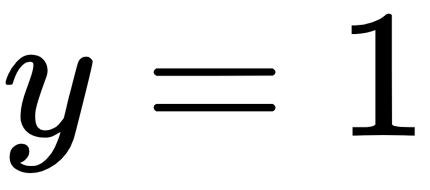

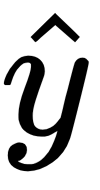
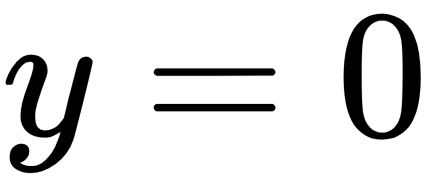

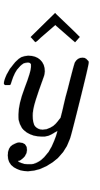
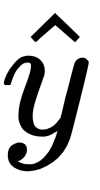
loss = tf.losses.sigmoid_cross_entropy(multi_class_labels=labels_in, logits=model_prediction)