
Python Deep Learning
Exploring deep learning techniques and neural network architectures with PyTorch, Keras, and TensorFlow, 2nd Edition
Ivan Vasilev, Daniel Slater, Gianmario Spacagna, Peter Roelants, Valentino Zocca
- 386 pages
- English
- ePUB (adapté aux mobiles)
- Disponible sur iOS et Android
Python Deep Learning
Exploring deep learning techniques and neural network architectures with PyTorch, Keras, and TensorFlow, 2nd Edition
Ivan Vasilev, Daniel Slater, Gianmario Spacagna, Peter Roelants, Valentino Zocca
À propos de ce livre
Learn advanced state-of-the-art deep learning techniques and their applications using popular Python libraries
Key Features
- Build a strong foundation in neural networks and deep learning with Python libraries
- Explore advanced deep learning techniques and their applications across computer vision and NLP
- Learn how a computer can navigate in complex environments with reinforcement learning
Book Description
With the surge in artificial intelligence in applications catering to both business and consumer needs, deep learning is more important than ever for meeting current and future market demands. With this book, you'll explore deep learning, and learn how to put machine learning to use in your projects.This second edition of Python Deep Learning will get you up to speed with deep learning, deep neural networks, and how to train them with high-performance algorithms and popular Python frameworks. You'll uncover different neural network architectures, such as convolutional networks, recurrent neural networks, long short-term memory (LSTM) networks, and capsule networks. You'll also learn how to solve problems in the fields of computer vision, natural language processing (NLP), and speech recognition. You'll study generative model approaches such as variational autoencoders and Generative Adversarial Networks (GANs) to generate images. As you delve into newly evolved areas of reinforcement learning, you'll gain an understanding of state-of-the-art algorithms that are the main components behind popular games Go, Atari, and Dota.By the end of the book, you will be well-versed with the theory of deep learning along with its real-world applications.
What you will learn
- Grasp the mathematical theory behind neural networks and deep learning processes
- Investigate and resolve computer vision challenges using convolutional networks and capsule networks
- Solve generative tasks using variational autoencoders and Generative Adversarial Networks
- Implement complex NLP tasks using recurrent networks (LSTM and GRU) and attention models
- Explore reinforcement learning and understand how agents behave in a complex environment
- Get up to date with applications of deep learning in autonomous vehicles
Who this book is for
This book is for data science practitioners, machine learning engineers, and those interested in deep learning who have a basic foundation in machine learning and some Python programming experience. A background in mathematics and conceptual understanding of calculus and statistics will help you gain maximum benefit from this book.
]]>
Foire aux questions
Informations
Reinforcement Learning Theory
- RL paradigms
- RL as a Markov decision process
- Finding optimal policies with Dynamic Programming
- Monte Carlo methods
- Temporal difference methods
- Value function approximation
- Experience replay
- Q-learning in action
RL paradigms
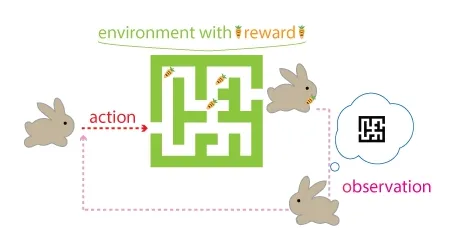
- Agent: The entity for which we are trying to learn actions. In the game, this is the player who tries to find their way through the maze.
- Environment: The world in which the agent operates. Here, this is the maze (grid) itself.
- State: All of the information available to the agent about its current envi...