GPU Parallel Program Development using CUDA teaches GPU programming by showing the differences among different families of GPUs. This approach prepares the reader for the next generation and future generations of GPUs. The book emphasizes concepts that will remain relevant for a long time, rather than concepts that are platform-specific. At the same time, the book also provides platform-dependent explanations that are as valuable as generalized GPU concepts.
The book consists of three separate parts; it starts by explaining parallelism using CPU multi-threading in Part I. A few simple programs are used to demonstrate the concept of dividing a large task into multiple parallel sub-tasks and mapping them to CPU threads. Multiple ways of parallelizing the same task are analyzed and their pros/cons are studied in terms of both core and memory operation.
Part II of the book introduces GPU massive parallelism. The same programs are parallelized on multiple Nvidia GPU platforms and the same performance analysis is repeated. Because the core and memory structures of CPUs and GPUs are different, the results differ in interesting ways. The end goal is to make programmers aware of all the good ideas, as well as the bad ideas, so readers can apply the good ideas and avoid the bad ideas in their own programs.
Part III of the book provides pointer for readers who want to expand their horizons. It provides a brief introduction to popular CUDA libraries (such as cuBLAS, cuFFT, NPP, and Thrust), the OpenCL programming language, an overview of GPU programming using other programming languages and API libraries (such as Python, OpenCV, OpenGL, and Apple's Swift and Metal, ) and the deep learning library cuDNN.
Domande frequenti
Come faccio ad annullare l'abbonamento?
È semplicissimo: basta accedere alla sezione Account nelle Impostazioni e cliccare su "Annulla abbonamento". Dopo la cancellazione, l'abbonamento rimarrà attivo per il periodo rimanente già pagato. Per maggiori informazioni, clicca qui
È possibile scaricare libri? Se sì, come?
Al momento è possibile scaricare tramite l'app tutti i nostri libri ePub mobile-friendly. Anche la maggior parte dei nostri PDF è scaricabile e stiamo lavorando per rendere disponibile quanto prima il download di tutti gli altri file. Per maggiori informazioni, clicca qui
Che differenza c'è tra i piani?
Entrambi i piani ti danno accesso illimitato alla libreria e a tutte le funzionalità di Perlego. Le uniche differenze sono il prezzo e il periodo di abbonamento: con il piano annuale risparmierai circa il 30% rispetto a 12 rate con quello mensile.
Cos'è Perlego?
Perlego è un servizio di abbonamento a testi accademici, che ti permette di accedere a un'intera libreria online a un prezzo inferiore rispetto a quello che pagheresti per acquistare un singolo libro al mese. Con oltre 1 milione di testi suddivisi in più di 1.000 categorie, troverai sicuramente ciò che fa per te! Per maggiori informazioni, clicca qui.
Perlego supporta la sintesi vocale?
Cerca l'icona Sintesi vocale nel prossimo libro che leggerai per verificare se è possibile riprodurre l'audio. Questo strumento permette di leggere il testo a voce alta, evidenziandolo man mano che la lettura procede. Puoi aumentare o diminuire la velocità della sintesi vocale, oppure sospendere la riproduzione. Per maggiori informazioni, clicca qui.
GPU Parallel Program Development Using CUDA è disponibile online in formato PDF/ePub?
Sì, puoi accedere a GPU Parallel Program Development Using CUDA di Tolga Soyata in formato PDF e/o ePub, così come ad altri libri molto apprezzati nelle sezioni relative a Mathematics e Mathematics General. Scopri oltre 1 milione di libri disponibili nel nostro catalogo.
THIS book is a self-sufficient GPU and CUDA programming textbook. I can imagine the surprise of somebody who purchased a GPU programming book and the first chapter is named “Introduction to CPU Parallel Programming.” The idea is that this book expects the readers to be sufficiently good at a low-level programming language, like C, but not in CPU parallel programming. To make this book a self-sufficient GPU programming resource for somebody that meets this criteria, any prior CPU parallel programming experience cannot be expected from the readers, yet it is not difficult to gain sufficient CPU parallel programming skills within a few weeks with an introduction such as Part I of this book.
No worries, in these few weeks of learning CPU parallel programming, no time will be wasted toward our eventual goal of learning GPU programming, since almost every concept that I introduce here in the CPU world will be applicable to the GPU world. If you are skeptical, here is one example for you: The thread ID, or, as we will call it tid, is the identifier of an executing thread in a multi-threaded program, whether it is a CPU or GPU thread. All of the CPU parallel programs we write will use the tid concept, which will make the programs directly transportable to the GPU environment. Don’t worry if the term thread is not familiar to you. Half the book is about threads, as it is the backbone of how CPUs or GPUs execute multiple tasks simultaneously.
1.1 EVOLUTION OF PARALLEL PROGRAMMING
A natural question that comes to one’s mind is: why even bother with parallel programming? In the 1970s, 1980s, even part of the 1990s, we were perfectly happy with single-threaded programming, or, as one might call it, serial programming. You wrote a program to accomplish one task. When done, it gave you an answer. Task is done … Everybody was happy … Although the task was done, if you were, say, doing a particle simulation that required millions, or billions of computations per second, or any other image processing computation that works on thousands of pixels, you wanted your program to work much faster, which meant that you needed a faster CPU.
Up until the year 2004, the CPU makers IBM, Intel, and AMD gave you a faster processor by making it work at a higher speed, 16 MHz, 20 MHz, 66 MHz, 100 MHz, and eventually 200, 333, 466 MHz … It looked like they could keep increasing the CPU speeds and provide higher performance every year. But, in 2004, it was obvious that continuously increasing the CPU speeds couldn’t go on forever due to technological limitations. Something else was needed to continuously deliver higher performances. The answer of the CPU makers was to put two CPUs inside one CPU, even if each CPU worked at a lower speed than a single one would. For example, two CPUs (cores, as they called them) working at 200 MHz could do more computations per second cumulatively, as compared to a single core working at 300 MHz (i.e., 2 × 200 > 300, intuitively).
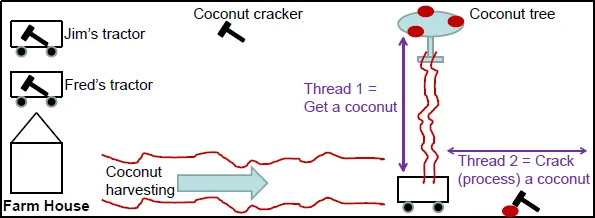
FIGURE 1.1 Harvesting each coconut requires two consecutive 30-second tasks (threads). Thread 1: get a coconut. Thread 2: crack (process) that coconut using the hammer.
Even if the story of “multiple cores within a single CPU” sounded like a dream come true, it meant that the programmers would now have to learn the parallel programming methods to take advantage of both of these cores. If a CPU could execute two programs at the same time, this automatically implied that a programmer had to write those two programs. But, could this translate to twice the program speed? If not, then our 2 × 200 > 300 thinking is flawed. What if there wasn’t enough work for one core? So, only truly a single core was busy, while the other one was doing nothing? Then, we are better off with a single core at 300 MHz. Numerous similar questions highlighted the biggest problem with introducing multiple cores, which is the programming that can allow utilizing those cores efficiently.
1.2 MORE CORES, MORE PARALLELISM
Programmers couldn’t simply ignore the additional cores that the CPU makers introduced every year. By 2015, INTEL had an 8-core desktop processor, i7-5960X [11], and 10-core workstation processors such as Xeon E7-8870 [14] in the market. Obviously, this multiple-core frenzy continued and will continue in the foreseeable future. Parallel programming turned from an exotic programming model in early 2000 to the only acceptable programming model as of 2015. The story doesn’t stop at desktop computers either. On the mobile processor side, iPhones and Android phones all have two or four cores. Expect to see an ever-increasing number of cores in the mobile arena in the coming years.
So, what is a thread? To answer this, let’s take a look at the 8-core INTEL CPU i7-5960X [11] one more time. The INTEL archive says that this is indeed an 8C/16T CPU. In other words, it has 8 cores, but can execute 16 threads. You also hear parallel programming being incorrectly referred to as multi-core programming. The correct terminology is multi-threaded programming. This is because when the CPU makers started designing multi-core architectures, they quickly realized that it wasn’t difficult to add the capability to execute two tasks within one core by sharing some of the core resources, such as cache memory.
ANALOGY 1.1: Cores versus Threads.
Figure 1.1 shows two brothers, Fred and Jim, who are farmers that own two tractors. They drive from their farmhouse to where the coconut trees are every day. They harvest the coconuts and bring them back to their farmhouse. To harvest (process) the coconuts, they use the hammer inside their tractor. The harvesting process requires two separate consecutive tasks, each taking 30 seconds: Task 1 go from the tractor to the tree, bringing one coconut at a time, and Task 2 crack (process) them by using the hammer, and store them in the tractor. Fred alone can process one coconut per minute, and Jim can also process one coconut per minute. Combined, they can process two coconuts per minute.
One day, Fred’s tractor breaks down. He leaves the tractor with the repair shop, forgetting that the coconut cracker is inside his tractor. It is too late by the time he gets to the farmhouse. But, they still have work to do. With only Jim’s tractor, and a single coconut cracker inside it, can they still process two coconuts per minute?
1.3 CORES VERSUS THREADS
Let’s look at our Analogy 1.1, which is depicted in Figure 1.1. If harvesting a coconut requires the completion of two consecutive tasks (we will call them threads): Th...
Indice dei contenuti
Stili delle citazioni per GPU Parallel Program Development Using CUDA
APA 6 Citation
Soyata, T. (2018). GPU Parallel Program Development Using CUDA (1st ed.). CRC Press. Retrieved from https://www.perlego.com/book/2193254/gpu-parallel-program-development-using-cuda-pdf (Original work published 2018)
Chicago Citation
Soyata, Tolga. (2018) 2018. GPU Parallel Program Development Using CUDA. 1st ed. CRC Press. https://www.perlego.com/book/2193254/gpu-parallel-program-development-using-cuda-pdf.
Harvard Citation
Soyata, T. (2018) GPU Parallel Program Development Using CUDA. 1st edn. CRC Press. Available at: https://www.perlego.com/book/2193254/gpu-parallel-program-development-using-cuda-pdf (Accessed: 15 October 2022).
MLA 7 Citation
Soyata, Tolga. GPU Parallel Program Development Using CUDA. 1st ed. CRC Press, 2018. Web. 15 Oct. 2022.