Distributed Machine Learning with Python
Guanhua Wang
- 284 pagine
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
Distributed Machine Learning with Python
Guanhua Wang
Informazioni sul libro
Build and deploy an efficient data processing pipeline for machine learning model training in an elastic, in-parallel model training or multi-tenant cluster and cloudKey Features• Accelerate model training and interference with order-of-magnitude time reduction• Learn state-of-the-art parallel schemes for both model training and serving• A detailed study of bottlenecks at distributed model training and serving stagesBook DescriptionReducing time cost in machine learning leads to a shorter waiting time for model training and a faster model updating cycle. Distributed machine learning enables machine learning practitioners to shorten model training and inference time by orders of magnitude. With the help of this practical guide, you'll be able to put your Python development knowledge to work to get up and running with the implementation of distributed machine learning, including multi-node machine learning systems, in no time. You'll begin by exploring how distributed systems work in the machine learning area and how distributed machine learning is applied to state-of-the-art deep learning models. As you advance, you'll see how to use distributed systems to enhance machine learning model training and serving speed. You'll also get to grips with applying data parallel and model parallel approaches before optimizing the in-parallel model training and serving pipeline in local clusters or cloud environments. By the end of this book, you'll have gained the knowledge and skills needed to build and deploy an efficient data processing pipeline for machine learning model training and inference in a distributed manner.What you will learn• Deploy distributed model training and serving pipelines• Get to grips with the advanced features in TensorFlow and PyTorch• Mitigate system bottlenecks during in-parallel model training and serving• Discover the latest techniques on top of classical parallelism paradigm• Explore advanced features in Megatron-LM and Mesh-TensorFlow• Use state-of-the-art hardware such as NVLink, NVSwitch, and GPUsWho this book is forThis book is for data scientists, machine learning engineers, and ML practitioners in both academia and industry. A fundamental understanding of machine learning concepts and working knowledge of Python programming is assumed. Prior experience implementing ML/DL models with TensorFlow or PyTorch will be beneficial. You'll find this book useful if you are interested in using distributed systems to boost machine learning model training and serving speed.
Domande frequenti
Informazioni
Section 1 – Data Parallelism
- Chapter 1, Splitting Input Data
- Chapter 2, Parameter Server and All-Reduce
- Chapter 3, Building a Data Parallel Training and Serving Pipeline
- Chapter 4, Bottlenecks and Solutions
Chapter 1: Splitting Input Data
- Single-node training is too slow
- Data parallelism – the high-level bits
- Hyperparameter tuning
Single-node training is too slow
- Input pre-processing
- Training
- Validation
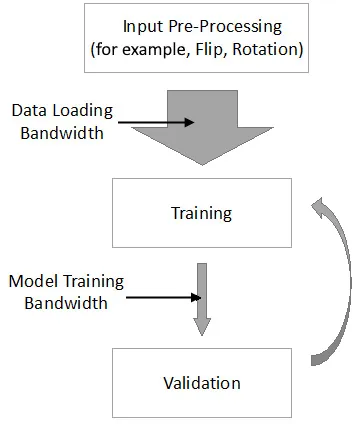
The mismatch between data loading bandwidth and model training bandwidth
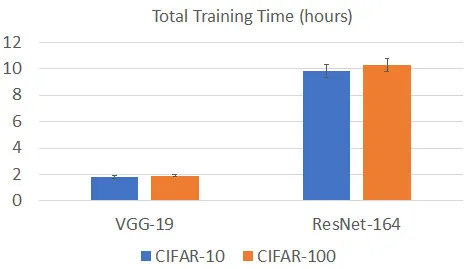
Single-node training time on popular datasets