Pentaho Data Integration Quick Start Guide
Create ETL processes using Pentaho
María Carina Roldán
- 178 pagine
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
Pentaho Data Integration Quick Start Guide
Create ETL processes using Pentaho
María Carina Roldán
Informazioni sul libro
Get productive quickly with Pentaho Data Integration
Key Features
- Take away the pain of starting with a complex and powerful system
- Simplify your data transformation and integration work
- Explore, transform, and validate your data with Pentaho Data Integration
Book Description
Pentaho Data Integration(PDI) is an intuitive and graphical environment packed with drag and drop design and powerful Extract-Transform-Load (ETL) capabilities. Given its power and flexibility, initial attempts to use the Pentaho Data Integration tool can be difficult or confusing. This book is the ideal solution.
This book reduces your learning curve with PDI. It provides the guidance needed to make you productive, covering the main features of Pentaho Data Integration. It demonstrates the interactive features of the graphical designer, and takes you through the main ETL capabilities that the tool offers.
By the end of the book, you will be able to use PDI for extracting, transforming, and loading the types of data you encounter on a daily basis.
What you will learn
- Design, preview and run transformations in Spoon
- Run transformations using the Pan utility
- Understand how to obtain data from different types of files
- Connect to a database and explore it using the database explorer
- Understand how to transform data in a variety of ways
- Understand how to insert data into database tables
- Design and run jobs for sequencing tasks and sending emails
- Combine the execution of jobs and transformations
Who this book is for
This book is for software developers, business intelligence analysts, and others involved or interested in developing ETL solutions, or more generally, doing any kind of data manipulation.
Domande frequenti
Informazioni
Transforming Data
- Transforming data in different ways
- Sorting and aggregating data
- Filtering rows
- Looking up for data
Transforming data in different ways
Extracting data from existing fields
Rank City Cost of Living Index Rent Index Cost of Living Plus Rent Index Groceries Index Restaurant Price Index Local Purchasing Power Index
1 Zurich, Switzerland 141.25 66.14 105.03 149.86 135.76 142.70
2 Geneva, Switzerland 134.83 71.70 104.38 138.98 129.74 130.96
3 Basel, Switzerland 130.68 49.68 91.61 127.54 127.22 139.01
4 Bern, Switzerland 128.03 43.57 87.30 132.70 119.48 112.71
5 Lausanne, Switzerland 127.50 52.32 91.24 126.59 132.12 127.95
6 Reykjavik, Iceland 123.78 57.25 91.70 118.15 133.19 88.95
...
- Create a new transformation and use a Text file input step to read the cost_of_living_europe.txt file.
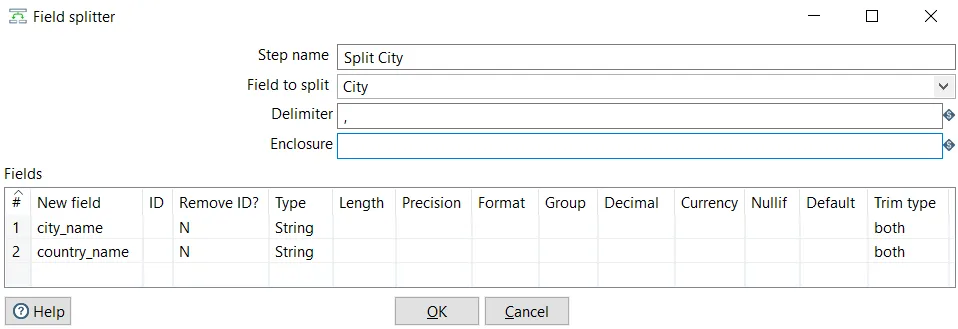
- Drag a Split Fields step from the Transform category and create a hop from the Text file input towards the Split Fields step.
- Double-click the step and configure it, as shown in the following screenshot:
- Close the window and run a preview. You will see the following:

Food Price
Milk (regular), (0.25 liter) 0.19 €
Loaf of Fresh White Bread (125.00 g) 0.24 €
Rice (white), (0.10 kg) 0.09 €
Eggs (regular) (2.40) 0.33 €
Local Cheese (0.10 kg) 0.89 €
Chicken Breasts (Boneless, Skinless), (0.15 kg) 0.86 €
...
- Create a new transformation and use a Text file input step to read the recommended_food.txt file.
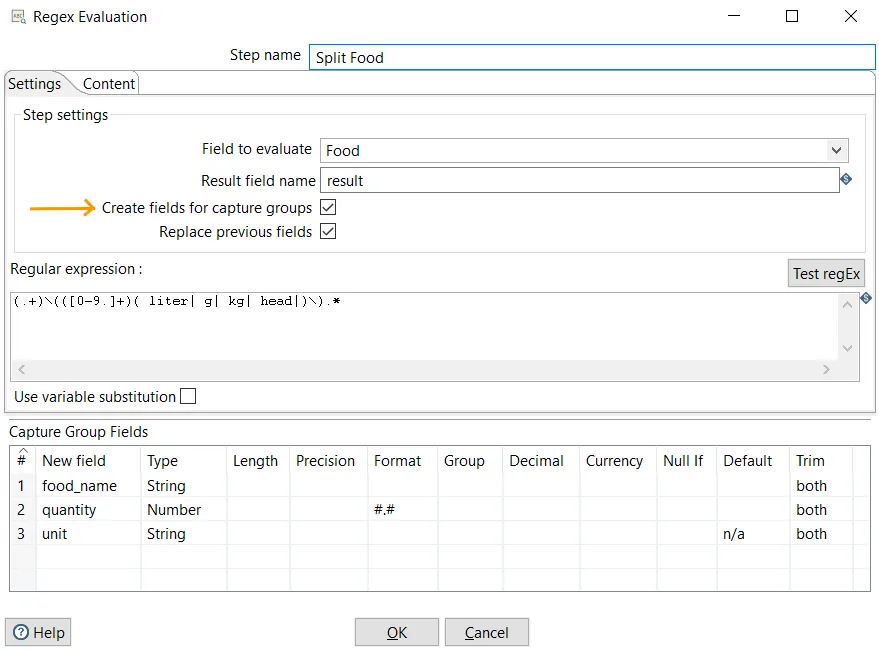
- Drag a Regex Evaluation step from the Scripting category and create a hop from the Text file input toward this new step.
- Double-click the step and configure it as shown in the following screenshot. Don't forget to check the Create fields for capture groups option:
- Close the window and run a preview. You will see the following: