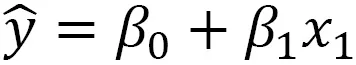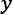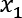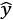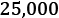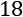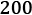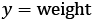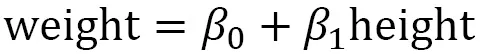Section 1: Introduction to Machine Learning Interpretation
In this section, you will recognize the importance of interpretability in business and understand its key aspects and challenges.
This section includes the following chapters:
- Chapter 1, Interpretation, Interpretability and Explainability; and why does it all matter?
- Chapter 2, Key Concepts of Interpretability
- Chapter 3, Interpretation Challenges
Chapter 1: Interpretation, Interpretability, and Explainability; and Why Does It All Matter?
We live in a world whose rules and procedures are governed by data and algorithms.
For instance, there are rules as to who gets approved for credit or released on bail, and which social media posts might get censored. There are also procedures to determine which marketing tactics are most effective and which chest x-ray features might diagnose a positive case of pneumonia.
You expect this because it is nothing new!
But not so long ago, rules and procedures such as these used to be hardcoded into software, textbooks, and paper forms, and humans were the ultimate decision-makers. Often, it was entirely up to human discretion. Decisions depended on human discretion because rules and procedures were rigid and, therefore, not always applicable. There were always exceptions, so a human was needed to make them.
For example, if you would ask for a mortgage, your approval depended on an acceptable and reasonably lengthy credit history. This data, in turn, would produce a credit score using a scoring algorithm. Then, the bank had rules that determined what score was good enough for the mortgage you wanted. Your loan officer could follow it or override it.
These days, financial institutions train models on thousands of mortgage outcomes, with dozens of variables. These models can be used to determine the likelihood that you would default on a mortgage with a presumed high accuracy. If there is a loan officer to stamp the approval or denial, it's no longer merely a guideline but an algorithmic decision. How could it be wrong? How could it be right?
Hold on to that thought because, throughout this book, we will be learning the answers to these questions and many more!
To interpret decisions made by a machine learning model is to find meaning in it, but furthermore, you can trace it back to its source and the process that transformed it. This chapter introduces machine learning interpretation and related concepts such as interpretability, explainability, black-box models, and transparency. This chapter provides definitions for these terms to avoid ambiguity and underpins the value of machine learning interpretability. These are the main topics we are going to cover:
- What is machine learning interpretation?
- Understanding the difference between interpretation and explainability
- A business case for interpretability
Let's get started!
Technical requirements
To follow the example in this chapter, you will need Python 3, either running in a Jupyter environment or in your favorite integrated development environment (IDE) such as PyCharm, Atom, VSCode, PyDev, or Idle. The example also requires the requests, bs4, pandas, sklearn , matplotlib, and scipy Python libraries. The code for this chapter is located here: https://github.com/PacktPublishing/Interpretable-Machine-Learning-with-Python/tree/master/Chapter01.
What is machine learning interpretation?
To interpret something is to explain the meaning of it. In the context of machine learning, that something is an algorithm. More specifically, that algorithm is a mathematical one that takes input data and produces an output, much like with any formula.
Let's examine the most basic of models, simple linear regression, illustrated in the following formula:
Once fitted to the data, the meaning of this model is that
predictions are a weighted sum of the
features with the
coefficients. In
this case, there's only one
feature or
predictor variable, and
the
variable is typically called
the
response or
target variable. A simple linear regression formula single-handedly
explains the transformation, which is performed on the input data
to produce the output
. The following example
can illustrate this concept in further detail.
Understanding a simple weight prediction model
If you go to this
web page maintained by the University of California,
http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_Dinov_020108_HeightsWeights, you can find a link to download a dataset of
synthetic records of weights and heights of
-year-olds. We won't use the entire dataset but only the sample table on the web page itself with
records. We scrape the table from the web page and fit a linear regression model to the data. The model uses the height to predict the weight.
In other words,
and
, so the formula for the linear regression model would be as follows:
You can find the code for this example here: https://github.com/PacktPublishing/Interpretable-Machine-Learning-with-Python/blob/master/Chapter01/WeightPrediction.ipynb.
To run this example, you need to install the following libraries:
- requests to fetch the web page
- bs4 (Beautiful Soup) to scrape the table from the web page
- pandas to load the table in to a dataframe
- sklearn (scikit-learn) to fit the linear regression model and calculate its error
- matplotlib to visualize the model
- scipy to test the correlation
You should load all of them first, as follows:
Import math
import requests
from bs4 import BeautifulSoup
import pandas as pd
from sklearn import linear_model
from sklearn.metrics import mean_absolute_error
import matplotlib.pyplot as plt
from scipy.stats import pearsonr
Once the libraries are all loaded, you use requests to fetch the contents of the web page, like this:
url = \
'http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_Dinov_020108_HeightsWeights'
page = requests.get(url)
Then, take these contents and scrape out just the contents of the table with BeautifulSoup, as follows:
soup = BeautifulSoup(page.content, 'html.parser')
tbl = soup.find("table",{"class":"wikitable"})
pandas can turn the raw HyperText Markup Language (HTML) contents...