![]()
PARTIE 1
LES RUDIMENTS
![]()
CHAPITRE 1
L’interface et les commandes Mplus
L’objectif de ce chapitre est de présenter le téléchargement de la version démo de Mplus, l’interface Mplus et les commandes principales.
1.LE TÉLÉCHARGEMENT
Pour commencer la modélisation par équations structurelles, il faut d’abord télécharger Mplus sur le site Web des auteurs, soit <https://www.statmodel.com/demo.shtml>1. La huitième version de la démo existe pour Windows 7 et plus récent, Apple (Mac OS X 10.8, Mountain Lion et plus récent) et Linux (64-bit). La version démo est limitée à deux variables indépendantes, six variables dépendantes, deux niveaux (pour l’analyse multiniveau) et deux variables latentes pour l’analyse de séries temporelles (time series analysis). Ces caractéristiques ne sont pas trop limitatives pour une utilisation pédagogique ou la réalisation d’analyses de base. Se procurer la version payante peut cependant s’imposer lorsqu’on doit travailler avec un grand nombre de variables ou combler des besoins très particuliers d’analyses. Hormis les précédentes limitations, il est possible de réaliser des régressions linéaires avec des conséquents multivariés, des régressions logistiques, ordonnées, des analyses de trajectoires, des analyses factorielles exploratoires et confirmatoires, des analyses de trajectoires latentes, des analyses de survie et des analyses multiniveaux, bref plus qu’il n’en est couvert dans le présent ouvrage. Une fois téléchargé, Mplus doit être installé sur l’ordinateur; il sera possible par la suite de l’utiliser.
2.L’OUVERTURE
Pour ouvrir Mplus, cliquez sur l’icône ou le raccourci. Mplus ne s’ouvre pas automatiquement en cliquant sur une syntaxe (fichier .inp) ou une sortie (fichier .out), comme cela se fait avec un autre logiciel. Pour ce faire, il faut d’abord spécifier l’ouverture par défaut des fichiers d’extension .inp et .out avec Mplus.
Pour ouvrir une syntaxe, cliquez File → Open…, puis choisissez le fichier d’extension .inp que vous désirez ouvrir ou faites File → New pour ouvrir une toute nouvelle syntaxe. Une fois la sélection faite, Mplus ouvre le document demandé ou affiche une page blanche sur laquelle il est possible de rédiger une syntaxe.
3.LES COMMANDES
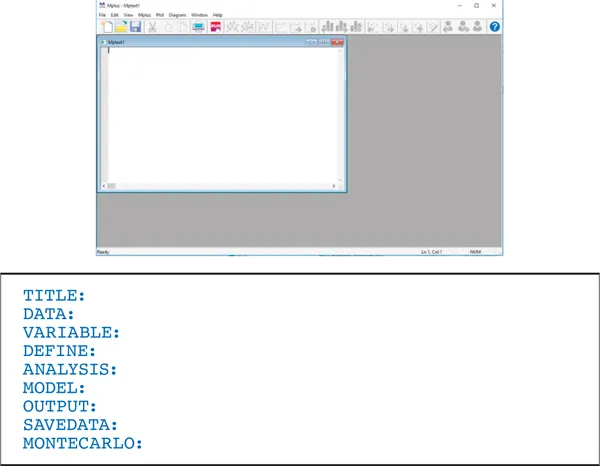
Les commandes principales sont énumérées ci-après. Il est impératif de terminer la commande avec un «:» sans espace entre la commande et le deux-points. La commande devient bleue lorsqu’elle est correctement tapée et reste noire autrement. Mplus ne différencie pas les lettres minuscules ou majuscules. Les commandes les plus fréquentes sont DATA:, VARIABLE:, ANALYSIS:, MODEL: et OUTPUT:. Une syntaxe Mplus peut rouler sans toutes ces commandes, mais DATA: et VARIABLE: sont primordiales.
4.QUELQUES PARTICULARITÉS DE MPLUS
À l’exception des commandes principales (en bleu), les autres se terminent par un «;» à la fin des arguments. Il est important de mettre les bonnes commandes aux bons endroits. Mplus ne tolère que des lignes de 90 caractères ou moins. Si une commande est trop longue, il faut la séparer en deux lignes et terminer la deuxième par «;» (c’est ainsi qu’une commande se termine dans le langage Mplus). Enfin, il est possible que certaines sous-commandes soient incompatibles entre elles, notamment pour l’échantillonnage complexe et pour l’utilisation de méthodes d’estimation particulières.
4.1.TITLE:
La commande TITLE: permet de donner un titre à la syntaxe. Cela peut être utile lorsqu’on souhaite tester plusieurs modèles (comme les analyses de classes latentes) et qu’on veut suivre rapidement les modifications. Autrement, elle n’a pas d’autres utilités.
4.2.DATA:
La commande DATA: permet d’indiquer à Mplus où se trouvent les données à utiliser. Il faut alors utiliser la fonction File is pour fournir la trajectoire à Mplus. Contrairement à SPSS et Excel, Mplus ne permet pas de visualiser directement les données; celles-ci ne sont pas à l’avant-plan. Notez que la fonction se termine par un «;».
Pour faciliter la gestion de la commande File is, il est recommandé de mettre le fichier de données dans le même dossier que la syntaxe (soit le dossier d’extension .inp). Dans ce cas, on peut utiliser plus simplement la commande suivante: File is donnees _ exemple.dat;, au lieu d’écrire l’emplacement exact du fichier (comme c’est le cas ci-dessous).
4.3.VARIABLE:
La commande suivante, VARIABLE:, permet de nommer les variables, d’indiquer les variables à utiliser, de préciser la nature des échelles des variables, de tenir compte des données manquantes et, plus tard, de gérer l’échantillonnage complexe. Les principales sous-commandes sont names are, missing are et usevariables are. Lorsqu’on nomme les variables avec names are, il importe que toutes les variables dans le fichier de données soient énumérées dans l’ordre (très important) en incluant celles qui ne seront pas utilisées dans l’analyse. Il convient aussi de nommer les variables de façon à se souvenir facilement de chacune d’elles, et ce, avec un maximum de huit caractères. Il n’est pas nécessaire que les noms de variables soient les mêmes que ceux utilisés dans la banque de départ (par exemple SPSS). Notez que toutes les commandes se terminent par un «;». Le point d’exclamation «!» permet d’ajouter des remarques qui ne seront pas lues par Mplus; elles apparaîtront en vert.
Par la suite, la fonction missing are indique quelle valeur représente une donnée manquante. Dans ce cas-ci, pour toutes les variables all, une donnée manquante est représentée par 999.
La troisième fonction, usevariables are, indique à Mplus les variables à utiliser dans le modèle à tester. Presque toutes les variables qui seront utilisées doivent s’y retrouver (sans quoi il y aura un message d’erreur). En revanche, celles qui ne seront pas utilisées ne doivent pas s’y retrouver, car Mplus fournira des résultats décevants. Mplus considère toutes les variables dans usevariables are comme faisant partie du modèle statistique et elles sont donc calculées dans les indices d’ajustement. Une variable nommée, mais non utilisée, sera traitée comme isolée (tous les liens avec les autres variables seront obligatoirement nuls) et cela appauvrit grandement les indices d’ajustement.
Enfin, dans l’exemple ci-dessus, la fonction categorical are est ajoutée pour définir les variables dépendantes comme catégorielles. Elle peut être utilisée pour signaler une variable dichotomique (binaire, par exemple, soit 0 ou 1), mais ce n’est pas impératif (dans certains cas, on voudra traiter la variable telle quelle). D’autres fonctions incluent count are (pour les données comptées), nominal are (pour des variables nominales) et censored are pour des données censurées.
On peut vouloir seulement utiliser un sous-groupe de données (par exemple en sélectionnant exclusivement des femmes ou encore des personnes ayant un QI de moins de 100) ou vouloir exclure des valeurs aberrantes. On recourt alors à la fonction useobservations are, suivie d’une condition logique désignant les participants. Cette fonction peut être utile, par exemple, lorsqu’on souhaite tester un modèle uniquement auprès des filles ou auprès de personnes ayant participé à une intervention donnée. Il peut y avoir plusieurs conditions. Chaque c...