![]()
Part I Beginning Digital Methods
![]()
One Positioning digital methods
Digital methods are research strategies for dealing with the ephemeral and unstable nature of online data
Digital methods for internet-related research
Digital methods are techniques for the study of societal change and cultural condition with online data. They make use of available digital objects such as the hyperlink, tag, time stamp, like, share, and retweet, and seek to learn from how the objects are treated by the methods built into the dominant devices online, such as Google Web Search. They endeavour to repurpose the online methods and services with a social research outlook. Ultimately the question is the location of the baseline, and whether the findings made may be grounded online.
Digital methods as a research practice are part of the computational turn in the humanities and social sciences, and as such may be positioned alongside other recent approaches, such as cultural analytics, culturomics, webometrics and altmetrics, where distinctions may be made about the types of data employed (natively digital or digitized) as well as method (written for the medium or migrated to it). The limitations of digital methods are also treated. Digital methods recognize the problems with web data, such as the impermanence of web services, and the instability of data streams, where for example APIs are reconfigured or discontinued. They also grapple with the quality of web data, and the challenges of longitudinal study, where for instance Twitter accounts and Facebook pages are deleted just as researchers are beginning to study the reach of Russian disinformation campaigning during the US presidential election (Albright, 2017).
When one raises the question of the web as a site for the study of social and cultural phenomena, a series of concerns arises. Web data are problematic. They have historical reputational issues, owing to the web’s representation and study as a medium of self-publication as well as one of dubious repute, inhabited by pornographers and conspiracy theorists (Dean, 1998). This was the cyberspace period, with an anything-goes web, where it often was treated analytically as a separate realm, even a ‘virtual society’ (Woolgar, 2003). Later, the web came to be known as an amateur production space for user-generated content (Jenkins, 2006). Nowadays the web is becoming a space for more than the study of online culture. Rather it has become a site to study a range of cultural and social issues, charting for example ‘concerns of the electorate’ from the ‘searches they conduct’, and ‘the spread of arguments … about political and other issues’, among other questions concerning society at large (Lazer et al., 2009: 722; Watts, 2007). Of course, it also remains a site to study online culture and undertake medium research. Digital methods are approaches to studying both, a point I return to when taking up the question of whether one can remove medium artefacts (such as manipulated search engine results or bots) and have a purified subject of study.
Scrutinizing web data
As indicated, however, the web has had the general difficulty of meeting the standards of good data (Borgman, 2009). As such, web data are also candidates for a shift, however slight, in methodological outlook. If web data are often considered messy and poor, where could their value lie? The question could be turned around. Where and how are web data handled routinely and deftly? Digital methods seek to learn from the so-called methods of the medium, that is, how online devices treat web data (Rogers, 2009). Thus, digital methods are, first, the study of the methods embedded in the devices treating online data (Rieder, 2012). How do search engines (such as Google) treat hyperlinks, clicks, timestamps and other digital objects? How do platforms (such as Facebook) treat profile interests as well as user interactions such as liking, sharing, commenting and liking comments?
Digital methods, however, seek to introduce a social research outlook to the study of online devices. ‘Nowcasting’ (however newfangled the term for real-time forecasting) is a good example and serves as a case of how search engine queries may be employed to study social change (Ginsberg et al., 2009). The location and intensity of flu and flu-related queries have been used to chart the rising and falling incidence of flu in specific places. The ‘places of flu’ is an imaginative use of web data for social research, extending the range of ‘trend’ research that engines have been known for to date under such names as Google Trends, Google Insights for Search, Yahoo Buzz Log, Yahoo Clues, Bing Webmaster Keyword Research, AOL Search Trends, YouTube Keyword Tool, YouTube Trends, and the Google AdWords Keyword Tool (Raehsler, 2012; US Centers for Disease Control and Prevention, 2014). It is also a case where the baseline is not web data or the web, but rather the (triangulated) findings from traditional flu surveillance techniques used by the Centers for Disease Control and Prevention in the United States and its equivalents in other countries. Search engine query data are checked against the offline baseline of data from hospitals, clinics, laboratories, state agencies, and others. The offline becomes the check against which the quality of the online is measured.
For those seeking to employ web data to study social phenomena, the webometrician, Mike Thelwall, has suggested precisely such a course of action: ground the findings offline. Given the messiness of web data as well as the (historical) scepticism that accompanies its use in social research (as mentioned above), Thelwall et al. (2005: 81) relate the overall rationale for a research strategy that calls for offline correlation:
One issue is the messiness of Web data and the need for data cleansing heuristics. The uncontrolled Web creates numerous problems in the interpretation of results … Indeed a sceptical researcher could claim the obstacles are so great that all Web analyses lack value. One response to this is to demonstrate that Web data correlate significantly with some non-Web data in order to prove that the Web data are not wholly random.
Online groundedness
Digital methods raise the question of the prospects of online groundedness. When and under what conditions may findings be grounded with web data? One of the earlier cases that pointed up the prospects of web data as having a ‘say’ in the findings is journalistic and experimental. In the long-form journalism in the NRC Handelsblad, the Dutch quality newspaper, the journalist asked the question whether Dutch culture was hardening, given the murders and the backlash to them of the populist politician, Pim Fortuyn, and the cultural critic, Theo van Gogh in the mid-2000s (Dohmen, 2007). By the ‘hardening of culture’ is meant becoming less tolerant of others, with even a growing segment of radicalizing and more extremist individuals in society. The method employed is of interest to those considering web data as of some value. Instead of embedding oneself (e.g., among hooligans), studying pamphlets and other hard-copy ephemera, and surveying experts, the research turned to the web. Lists of right-wing and extremist websites were curated, and the language on the two types of sites was compared over time, with the aid of the Wayback Machine of the Internet Archive. It was found that over time the language on the right-wing sites increasingly approximated that on the extremist sites. While journalistic, the work provides a social research practice: charting change in language over time on the web, in order to study social change. The article also was accompanied by the data set, which is unusual for newspapers, and heralded the rise of data journalism. The journalist read the websites, in a close reading approach; one could imagine querying the sources as well in the distant reading approach which has come to be affiliated with the computational turn and big data studies more generally (Moretti, 2005; boyd and Crawford, 2012).
Another project that is demonstrative of digital methods is the cartogram visualization of recipe queries, which appeared in the New York Times (Ericson and Cox, 2009). All the recipes (on allrecipes.com) queried the day before Thanksgiving, the American holiday and feast, were geolocated, showing the locations whence the search queries came. For each recipe, the map is shaded according to frequency of queries by state (and is statistically normalized), where one notes differences in recipe queries, and perhaps food preference, across the United States. It presents, more broadly, a geography of taste. Here the question becomes how to ground the findings. Does one move offline with surveys or regional cookbooks, or seek more online data, such as food photos, tagged by location and timestamped? Would Flickr or Instagram provide more grounding? Here the web becomes a candidate grounding site.
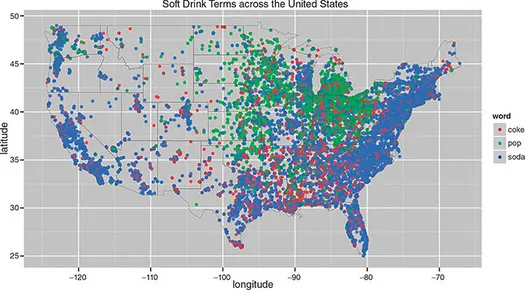
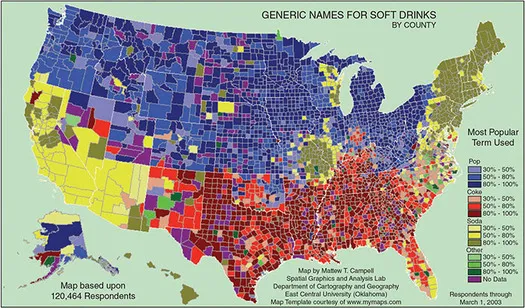
Online data have been employed to study regional differences. One case in point is the classic discussion of language variation in the use of the terms ‘soda’, ‘pop’ and ‘coke’ in the United States. Geotagged tweets with the words ‘soda’, ‘pop’ or ‘coke’ are captured and plotted on a map, displaying a geography of word usage (see Figure 1.1). In the project the findings are compared to those made by another web data collection technique, a survey method migrated online, also known as a ‘virtual method’, discussed below. A webpage serves as an online data collection vessel, where people are asked to choose their preferred term (soda, pop, coke, or other) and fill in their hometown, including state and zip code (see Figure 1.2). The resulting map shows starker regional differentiation than the Twitter analysis. Chen, while not confirming the earlier findings, reports ‘similar patterns’, with pop being a midwestern term, coke southern and soda northeastern (2012; Shelton, 2011).
The natively digital and the digitized
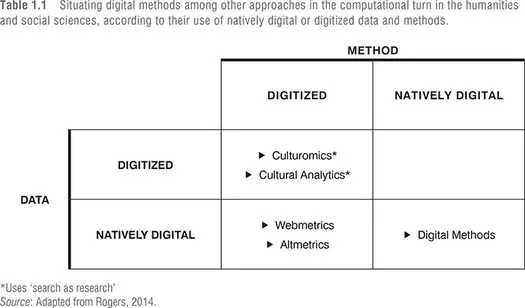
Digital methods may be situated as somewhat distinctive from other contemporary approaches within the computational turn in the social sciences and the digital humanities (see Table 1.1). First, like other contemporary approaches in the study of digital data, they employ methods based on queries and have as a research practice what may be called search as research. They differ, however, from other approaches in that they rely largely on natively digital data and online methods as opposed to digitized data and migrated methods.
Two approaches in the digital humanities that may be compared to digital methods are culturomics and cultural analytics. While digital methods study web or natively digital data, culturomics and cultural analytics have as their corpuses what one could call digitized materials, which then are searched for either words (in culturomics) or formal material properties (in cultural analytics). Culturomics queries Google Books and performs longitudinal studies concerning the changes in use of language from the written word, inferring broader cultural trends. For example, American spelling is gradually supplanting British spelling, and celebrity or fame is increasingly more quickly gained and shorter-lived (Michel et al., 2011). Cultural analytics is a research practice that also queries, but at a lower level in a computing sense; it queries and seeks patterns and changes not to words but to formal properties of media, such as the hue, brightness and saturation in images.
Figure 1.1 US map of self-reported usage of terms for soft drinks, 2003.
Source: Campbell, 2003.
Figure 1.2 US map showing distribution of usage of terms (in geotagged tweets in Twitter) for soft drinks, 2012.
Source: Chen, 2012.
Table 1.1 Uses ‘search as research’
Source: Adapted from Rogers, 2014.
Digitized data are often considered better than web data, as mentioned. Both culturomics and cultural analytics have to their advantage the study of what has been described as ‘good data’. For culturomics the queries are made in a large collection of historical books, which the researchers describe as the study of millions of books, or approximately ‘4% of all books ever printed’ (Michel et al., 2011: 176). For cultural analytics, the preferred corpus is the complete oeuvre of an artist (such as Mark Rothko) or the complete set of covers of a magazine (such as Time). In those cases, the data are good because they exist or have been captured from the beginning, cover long periods of time, and are complete, or rather so. One knows the percentage of missing data. With the web much of the data is from a recent past, covers a short period of time and is incomplete, where there is often a difficulty in grasping what complete data would be.
Two approaches in the e-social sciences also may be compared to digital methods: webometrics and altmetrics. Both are scientometric or bibliometric approaches of studying reputation or impact, applied to web data. As such they migrate citation analysis to the web, albeit in distinct ways. Webometrics studies hyperlinks (much like the Issuecrawler as discussed in Chapter 3) and derives site reputation or impact from the quantity and quality of links received. It uses natively digital objects (hyperlinks) and digitized method (bibliometrics). Altmetrics is similar, employing social media metrics (natively digital activities such as retweeting) to assign an ‘attention’ score to a published academic article (digitized method). The score increases depending on the quantity of mentions across online sources. Mentions in the news and in blog postings weigh more heavily than on Reddit, for example.
Virtual and digital methods compared
Indeed, the difficulties of moving methods and collecting data online are the subject of a social science approach, in the computational turn, called virtual methods. While digital methods seek to make use of the methods of the medium, virtual methods migrate the social science instrumentarium online, such as online surveys. The transition of the methods online varies in smoothness. Online, net or virtual ethnography has been able to define communities, enter them and observe and participate (Hine, 2005). For other techniques virtual methods seek to overcome some difficulties inherent in the web as a site of study and data collection realm. When surveying, the question is how to find the respondents, and whether one knows a response rate. For sampling, similarly, there are questions about whether one...