Explore big data concepts, platforms, analytics, and their applications using the power of Hadoop 3About This Book• Learn Hadoop 3 to build effective big data analytics solutions on-premise and on cloud• Integrate Hadoop with other big data tools such as R, Python, Apache Spark, and Apache Flink• Exploit big data using Hadoop 3 with real-world examplesWho This Book Is ForBig Data Analytics with Hadoop 3 is for you if you are looking to build high-performance analytics solutions for your enterprise or business using Hadoop 3's powerful features, or you're new to big data analytics. A basic understanding of the Java programming language is required.What You Will Learn• Explore the new features of Hadoop 3 along with HDFS, YARN, and MapReduce• Get well-versed with the analytical capabilities of Hadoop ecosystem using practical examples• Integrate Hadoop with R and Python for more efficient big data processing• Learn to use Hadoop with Apache Spark and Apache Flink for real-time data analytics• Set up a Hadoop cluster on AWS cloud• Perform big data analytics on AWS using Elastic Map ReduceIn DetailApache Hadoop is the most popular platform for big data processing, and can be combined with a host of other big data tools to build powerful analytics solutions. Big Data Analytics with Hadoop 3 shows you how to do just that, by providing insights into the software as well as its benefits with the help of practical examples.Once you have taken a tour of Hadoop 3's latest features, you will get an overview of HDFS, MapReduce, and YARN, and how they enable faster, more efficient big data processing. You will then move on to learning how to integrate Hadoop with the open source tools, such as Python and R, to analyze and visualize data and perform statistical computing on big data. As you get acquainted with all this, you will explore how to use Hadoop 3 with Apache Spark and Apache Flink for real-time data analytics and stream processing. In addition to this, you will understand how to use Hadoop to build analytics solutions on the cloud and an end-to-end pipeline to perform big data analysis using practical use cases.By the end of this book, you will be well-versed with the analytical capabilities of the Hadoop ecosystem. You will be able to build powerful solutions to perform big data analytics and get insight effortlessly.Style and approachFilled with practical examples and use cases, this book will not only help you get up and running with Hadoop, but will also take you farther down the road to deal with Big Data Analytics

eBook - ePub
Big Data Analytics with Hadoop 3
Build highly effective analytics solutions to gain valuable insight into your big data
- 482 pages
- English
- ePUB (mobile friendly)
- Available on iOS & Android
eBook - ePub
Big Data Analytics with Hadoop 3
Build highly effective analytics solutions to gain valuable insight into your big data
About this book
Trusted by 375,005 students
Access to over 1.5 million titles for a fair monthly price.
Study more efficiently using our study tools.
Information
Big Data Processing with MapReduce
This chapter will puts everything we have learned in the book into a practical use case of building an end-to-end pipeline to perform big data analytics.
In a nutshell, the following topics will be covered throughout this chapter:
- The MapReduce framework
- MapReduce job types:
- Single mapper jobs
- Single mapper reducer jobs
- Multiple mappers reducer jobs
- MapReduce patterns:
- Aggregation patterns
- Filtering patterns
- Join patterns
The MapReduce framework
MapReduce is a framework used to compute a large amount of data in a Hadoop cluster. MapReduce uses YARN to schedule the mappers and reducers as tasks, using the containers. The MapReduce framework enables you to write distributed applications to process large amounts of data from a filesystem, such as a Hadoop Distributed File System (HDFS), in a reliable and fault-tolerant manner. When you want to use the MapReduce framework to process data, it works through the creation of a job, which then runs on the framework to perform the tasks needed. A MapReduce job usually works by splitting the input data across worker nodes, running the mapper tasks in a parallel manner.
At this time, any failures that happen, either at the HDFS level or the failure of a mapper task, are handled automatically, to be fault-tolerant. Once the mappers have completed, in the results are copied over the network to other machines running the reducer tasks.
An example of using a MapReduce job to count frequencies of words is shown in the following diagram:

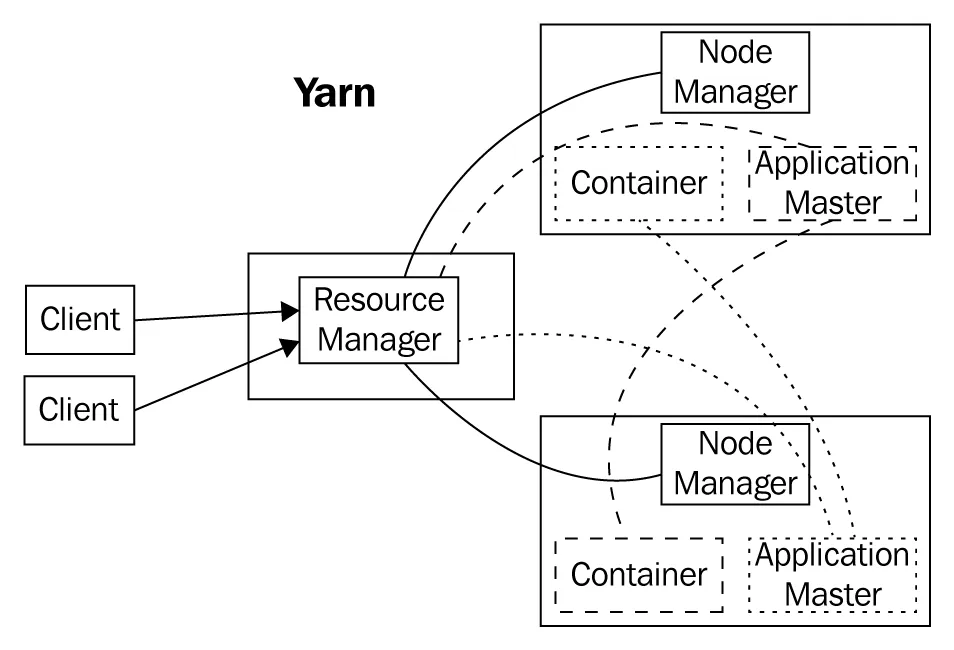
MapReduce uses YARN as a resource manager, which is shown in the following diagram:
The term MapReduce actually refers to two separate and distinct tasks that Hadoop programs perform. The first is the map job, which takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs).
The reduce job takes the output from a map as input and combines those data tuples into a smaller set of tuples. As the sequence of the name MapReduce implies, the reduce job is always performed after the map job.
The input to a MapReduce job is a set of files in the data store that is spread out over the HDFS. In Hadoop, these files are split with an input format, which defines how to separate a file into input splits. An input split is a byte-oriented view of a chunk of the file, to be loaded by a map task. Each map task in Hadoop is broken into the following phases: record reader, mapper, combiner, and partitioner. The output of the map tasks, called the intermediate keys and values, is sent to the reducers. The reduce tasks are broken into the following phases: shuffle, sort, reducer, and output format. The nodes in which the map tasks run are optimally on the nodes in which the data rests. This way, the data typically does not have to move over the network, and can be computed on the local machine.
Throughout this chapter, we will look at different use cases, and how to use a MapReduce job to produce the output desired; for this purpose, we will use a simple dataset.
Dataset
The first dataset is a table of cities containing the city ID and the name of the City:
Id,City
1,Boston
2,New York
3,Chicago
4,Philadelphia
5,San Francisco
7,Las Vegas
This file, cities.csv, is available as a download, and, once downloaded, you can move it into hdfs by running the command, as shown in the following code:
hdfs dfs -copyFromLocal cities.csv /user/normal
The second dataset is that of daily temperature measurements for a city, and this contains the Date of measurement, the city ID, and the Temperature on the particular date for the specific city:
Date,Id,Temperature
2018-01-01,1,21
2018-01-01,2,22
2018-01-01,3,23
2018-01-01,4,24
2018-01-01,5,25
2018-01-01,6,22
2018-01-02,1,23
2018-01-02,2,24
2018-01-02,3,25
This file, temperatures.csv, is available as a download, and, once downloaded, you can move it into hdfs by running the command, a...
Table of contents
- Title Page
- Copyright and Credits
- Packt Upsell
- Contributors
- Preface
- Introduction to Hadoop
- Overview of Big Data Analytics
- Big Data Processing with MapReduce
- Scientific Computing and Big Data Analysis with Python and Hadoop
- Statistical Big Data Computing with R and Hadoop
- Batch Analytics with Apache Spark
- Real-Time Analytics with Apache Spark
- Batch Analytics with Apache Flink
- Stream Processing with Apache Flink
- Visualizing Big Data
- Introduction to Cloud Computing
- Using Amazon Web Services
Frequently asked questions
Yes, you can cancel anytime from the Subscription tab in your account settings on the Perlego website. Your subscription will stay active until the end of your current billing period. Learn how to cancel your subscription
No, books cannot be downloaded as external files, such as PDFs, for use outside of Perlego. However, you can download books within the Perlego app for offline reading on mobile or tablet. Learn how to download books offline
We are an online textbook subscription service, where you can get access to an entire online library for less than the price of a single book per month. With over 1.5 million books across 990+ topics, we’ve got you covered! Learn about our mission
Look out for the read-aloud symbol on your next book to see if you can listen to it. The read-aloud tool reads text aloud for you, highlighting the text as it is being read. You can pause it, speed it up and slow it down. Learn more about Read Aloud
Yes! You can use the Perlego app on both iOS and Android devices to read anytime, anywhere — even offline. Perfect for commutes or when you’re on the go.
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Please note we cannot support devices running on iOS 13 and Android 7 or earlier. Learn more about using the app
Yes, you can access Big Data Analytics with Hadoop 3 by Sridhar Alla in PDF and/or ePUB format, as well as other popular books in Computer Science & Data Modelling & Design. We have over 1.5 million books available in our catalogue for you to explore.