With Hands-On Recommendation Systems with Python, learn the tools and techniques required in building various kinds of powerful recommendation systems (collaborative, knowledge and content based) and deploying them to the web
Key Features
- Build industry-standard recommender systems
- Only familiarity with Python is required
- No need to wade through complicated machine learning theory to use this book
Book Description
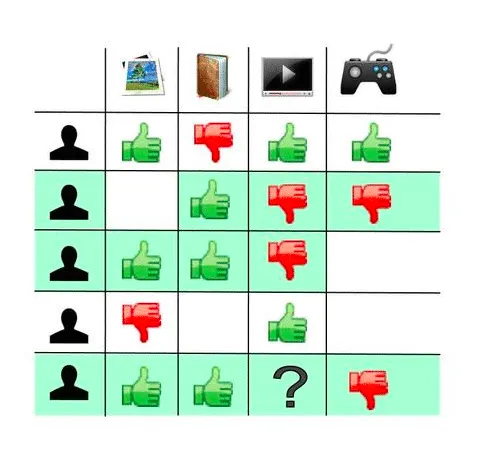
Recommendation systems are at the heart of almost every internet business today; from Facebook to Netflix to Amazon. Providing good recommendations, whether it's friends, movies, or groceries, goes a long way in defining user experience and enticing your customers to use your platform.
This book shows you how to do just that. You will learn about the different kinds of recommenders used in the industry and see how to build them from scratch using Python. No need to wade through tons of machine learning theory—you'll get started with building and learning about recommenders as quickly as possible..
In this book, you will build an IMDB Top 250 clone, a content-based engine that works on movie metadata. You'll use collaborative filters to make use of customer behavior data, and a Hybrid Recommender that incorporates content based and collaborative filtering techniques
With this book, all you need to get started with building recommendation systems is a familiarity with Python, and by the time you're fnished, you will have a great grasp of how recommenders work and be in a strong position to apply the techniques that you will learn to your own problem domains.
What you will learn
- Get to grips with the different kinds of recommender systems
- Master data-wrangling techniques using the pandas library
- Building an IMDB Top 250 Clone
- Build a content based engine to recommend movies based on movie metadata
- Employ data-mining techniques used in building recommenders
- Build industry-standard collaborative filters using powerful algorithms
- Building Hybrid Recommenders that incorporate content based and collaborative fltering
Who this book is for
If you are a Python developer and want to develop applications for social networking, news personalization or smart advertising, this is the book for you. Basic knowledge of machine learning techniques will be helpful, but not mandatory.