
Hands-On Recommendation Systems with Python
Start building powerful and personalized, recommendation engines with Python
Rounak Banik
- 146 pages
- English
- ePUB (adapté aux mobiles)
- Disponible sur iOS et Android
Hands-On Recommendation Systems with Python
Start building powerful and personalized, recommendation engines with Python
Rounak Banik
À propos de ce livre
With Hands-On Recommendation Systems with Python, learn the tools and techniques required in building various kinds of powerful recommendation systems (collaborative, knowledge and content based) and deploying them to the web
Key Features
- Build industry-standard recommender systems
- Only familiarity with Python is required
- No need to wade through complicated machine learning theory to use this book
Book Description
Recommendation systems are at the heart of almost every internet business today; from Facebook to Netflix to Amazon. Providing good recommendations, whether it's friends, movies, or groceries, goes a long way in defining user experience and enticing your customers to use your platform.
This book shows you how to do just that. You will learn about the different kinds of recommenders used in the industry and see how to build them from scratch using Python. No need to wade through tons of machine learning theory—you'll get started with building and learning about recommenders as quickly as possible..
In this book, you will build an IMDB Top 250 clone, a content-based engine that works on movie metadata. You'll use collaborative filters to make use of customer behavior data, and a Hybrid Recommender that incorporates content based and collaborative filtering techniques
With this book, all you need to get started with building recommendation systems is a familiarity with Python, and by the time you're fnished, you will have a great grasp of how recommenders work and be in a strong position to apply the techniques that you will learn to your own problem domains.
What you will learn
- Get to grips with the different kinds of recommender systems
- Master data-wrangling techniques using the pandas library
- Building an IMDB Top 250 Clone
- Build a content based engine to recommend movies based on movie metadata
- Employ data-mining techniques used in building recommenders
- Build industry-standard collaborative filters using powerful algorithms
- Building Hybrid Recommenders that incorporate content based and collaborative fltering
Who this book is for
If you are a Python developer and want to develop applications for social networking, news personalization or smart advertising, this is the book for you. Basic knowledge of machine learning techniques will be helpful, but not mandatory.
Foire aux questions
Informations
Getting Started with Data Mining Techniques

- Similarity measures: Given two items, how do we mathematically quantify how different or similar they are to each other? Similarity measures help us in answering this question.
We have already made use of a similarity measure (the cosine score) while building our content recommendation engine. In this chapter, we will be looking at a few other popular similarity scores. - Dimensionality reduction: When building collaborative filters, we are usually dealing with millions of users rating millions of items. In such cases, our user and item vectors are going to be of a dimension in the order of millions. To improve performance, speed up calculations, and avoid the curse of dimensionality, it is often a good idea to reduce the number of dimensions considerably, while retaining most of the information. This section of the chapter will describe techniques that do just that.
- Supervised learning: Supervised learning is a class of machine learning algorithm that makes use of label data to infer a mapping function that can then be used to predict the label (or class) of unlabeled data. We will be looking at some of the most popular supervised learning algorithms, such as support vector machines, logistic regression, decision trees, and ensembling.
- Clustering: Clustering is a type of unsupervised learning where the algorithm tries to divide all the data points into a certain number of clusters. Therefore, without the use of a label dataset, the clustering algorithm is able to assign classes to all the unlabel points. In this section, we will be looking at k-means clustering, a simple but powerful algorithm popularly used in collaborative filters.
- Evaluation methods and metrics: We will take a look at a few evaluation metrics that are used to gauge the performance of these algorithms. The metrics include accuracy, precision, and recall.
Problem statement
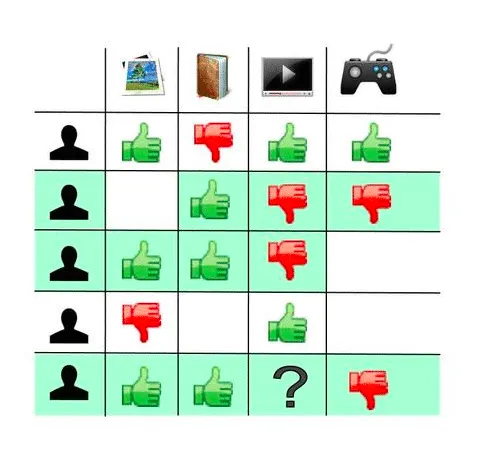
Similarity measures
Euclidean distance
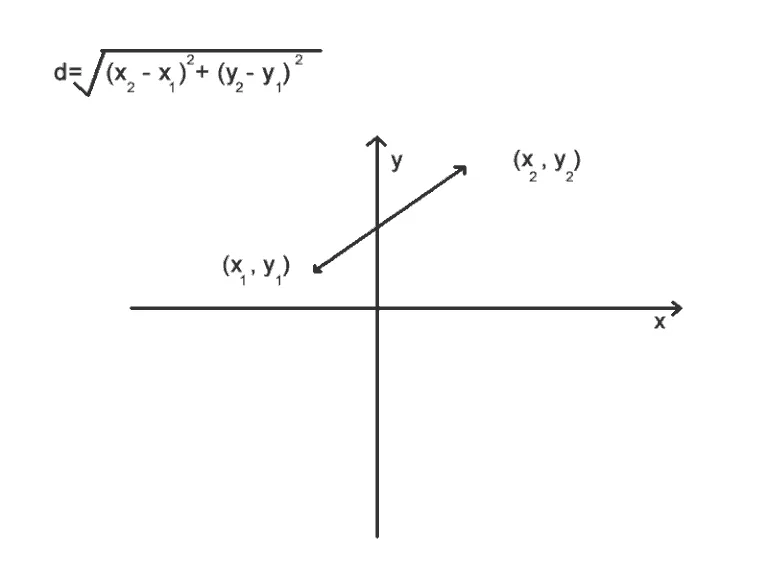
- v1: (q1, q2,...., qn)
- v2: (r1, r2,....., rn)

#Function to compute Euclidean Distance.
def euclidean(v1, v2):
#Convert 1-D Python lists to numpy vectors
v1 = np.array(v1)
v2 = np.array(v2)
#Compute vector which is the element wise square of the difference
diff = np.power(np.array(v1)- np.array(v2), 2)
#Perform summation of the elements of the above vector
sigma_val = np.sum(diff)
#Compute square root and return final Euclidean score
euclid_score = np.sqrt(sigma_val)
return euclid_score