Basic Terms and Definitions
There are some basic definitions and concepts that should provide useful context for understanding database design. Some of the terms we define are in common use but take on specific meaning in the information technology field.
Datum is a singular word, and data is its plural. A datum (sometimes called a “data item”) is a “particle” of information like “12” or “Q.”
Information refers to data that are structured and organized to be useful in making a decision or performing some task. Relational databases are currently the most common way data are organized into information; hence this book’s focus on relational databases.
Knowledge denotes understanding or evaluating information. An example could be when Casleton Corporation analyzes its recruiting data and concludes that recruits from Driftwood College tend to have good performance evaluations only if their GPAs are at least 3.0. Based on this “knowledge,” Casleton’s managers might choose to screen applicants from Driftwood College by their GPAs, interviewing only those graduates with at least a 3.0 GPA.
For this book, we will focus on representing information within computer systems. Note, however, that knowledge can also be represented within computers. One common kind of knowledge representation (KR) within computers is part of the field of artificial intelligence (AI). One common business application of AI in business is in automated business rules systems. Another recently popularized AI application is the “Siri” personal assistant on iPhones and iPads, or the similar “Google Voice” app on Android devices. Although its business uses are substantial and gradually expanding, we will not discuss AI, as relational database systems are simpler and far more ubiquitous.
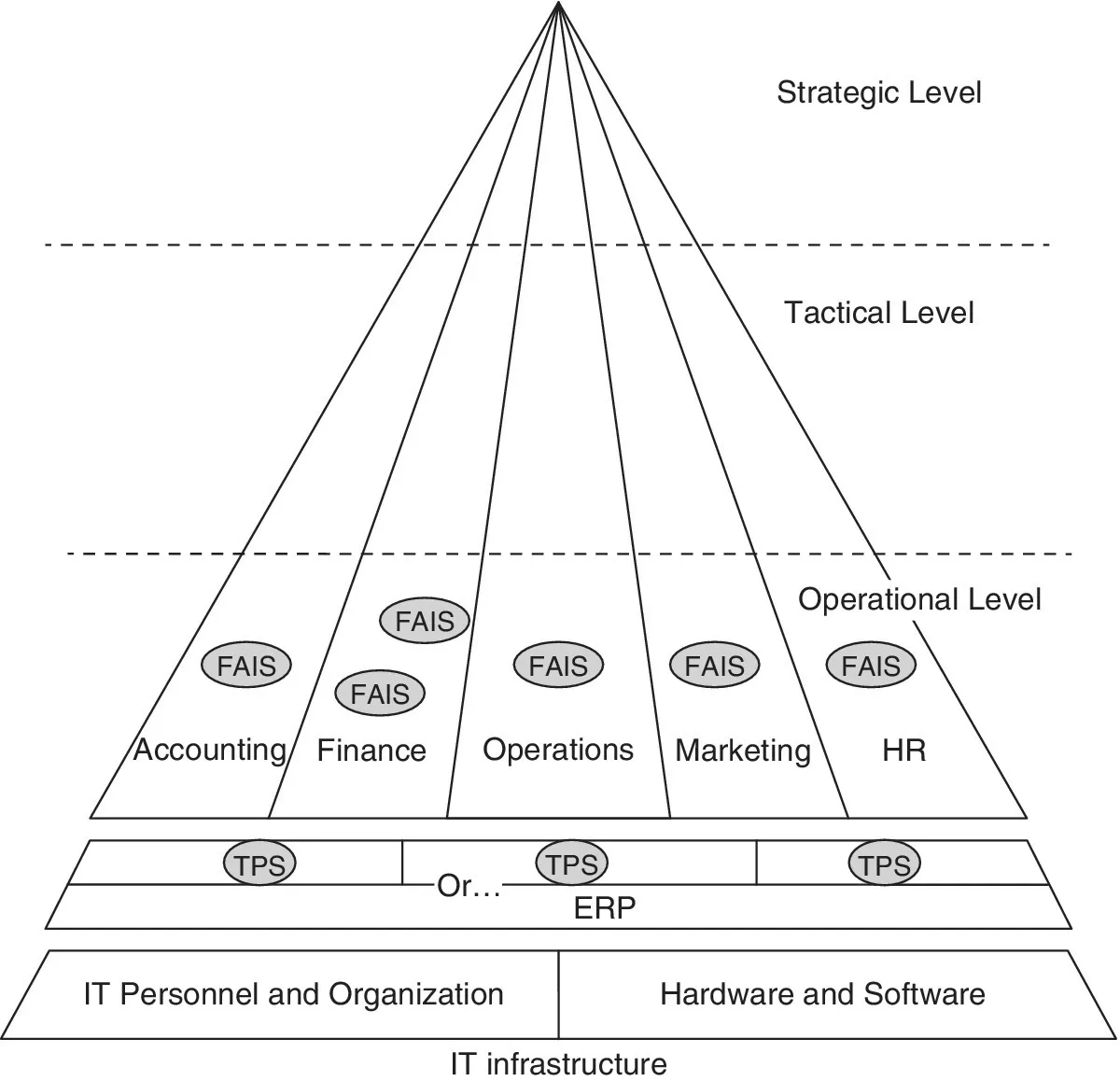
Information systems consist of the ways that organizations store, move, organize, and manipulate/process their information. The components that implement information systems – in other words, information technology – consist of the following:
- Hardware – physical tools: computer and network hardware, but also low‐tech objects such as pens and paper
- Software – (changeable) instructions for the hardware (when applicable; the simplest hardware does not need software)
- People
- Procedures – instructions for people
- Data/databases
Information systems existed before computers and networks – they just used relatively simple hardware that usually did not need software (at least as we know it today). For example, filing all sales receipts alphabetically by customer in a filing cabinet is a form of information system, although it is not electronic. Tax records kept on clay tablets by ancient civilizations were also a form of information system. Strictly speaking, this book is about an aspect of CBISs (computer‐based information systems). Because of the present ubiquity of computers in information systems, we usually leave out the “CB,” treating it as implicit.
Present‐day CBISs have the following advantages over older, manual information systems:
- They can perform numerical computations and other data processing much more quickly, accurately, and cheaply than people.
- They can communicate very quickly and accurately.
- They can store large amounts of information quickly and cheaply, and information retrieval can often be very rapid.
- They can, to varying degrees, automate tasks and processes that previously required human labor.
- Information no longer needs to be “stuck” with particular things, locations, or people.
However, increasingly, automated systems can have drawbacks, such as the following:
- Small errors can have a much wider impact than in a less automated system. For example, in March 2003, a minor software bug in some airport data collection code – which programmers were aware of but considered too small to cause operational problems – grounded all aircraft in Japan for two days.
- Fewer people in the organization understand exactly how information is processed.
- Sometimes, malfunctions may go unnoticed. For example, American Airlines once discovered a serious bug in its “yield management” software only after reporting quarterly results that were significantly lower than expected. (“Yield management” refers to the process of deciding how many aircraft seats to make available for sale at different fare levels.)
Information architecture is the particular way an organization has arranged its information systems: for example, a particular network of computers running particular software might support a firm’s marketing organization, while another network of computers running different software might support its production facilities, and so forth.
Information infrastructure consists of the hardware and software that support an organization’s information architecture, together with the personnel and services dedicated primarily to maintaining and developing that hardware and software.
Application and application program (nowadays sometimes simply “app”) are somewhat ill‐defined terms but typically denote computer software and databases supporting a particular task or group of tasks. For example, a firm’s human resource department might use one application to analyze benefit costs and usage, and another to monitor employee turnover.
A classic business IT problem is that applications, especially those used by different parts of an organization, may not communicate with one another effectively – for example, a new hire or retirement might have to be separately entered into both of the human resources systems described above because they do not communicate or share a common database.