![]()
TEIL II
Verteilte Daten
Für eine erfolgreiche Technologie muss die Wirklichkeit Vorrang vor der Öffentlichkeitsarbeit haben, denn die Natur lässt sich nicht täuschen.
– Richard Feynman, Rogers Commission Report (1986)
Die in Teil I dieses Buchs diskutierten Aspekte von Datensystemen gelten, wenn die Daten auf einem einzelnen Computer gespeichert werden. In Teil II gehen wir nun eine Stufe nach oben und fragen: Was passiert, wenn mehrere Computer beim Speichern und Abrufen von Daten beteiligt sind?
Es gibt verschiedene Gründe, eine Datenbank auf mehrere Computer zu verteilen:
Skalierbarkeit
Wird das Datenvolumen, die Lesebelastung oder die Schreibbelastung größer, als ein einzelner Computer bewältigen kann, lässt sich die Last möglicherweise auf mehrere Computer verteilen.
Fehlertoleranz/Hochverfügbarkeit
Wenn Ihre Anwendung auch dann weiterhin funktionieren muss, wenn ein Computer (oder mehrere Computer oder das Netzwerk oder ein ganzes Rechenzentrum) ausfällt, können Sie mit mehreren Computern ein redundantes System aufbauen. Fällt ein Computer aus, kann ein anderer dessen Aufgaben übernehmen.
Latenz
Wenn Ihre Benutzer global verteilt sind, brauchen Sie vielleicht Server an mehreren Standorten weltweit, sodass jeder Benutzer von einem Rechenzentrum in seiner geografischen Nähe bedient werden kann. Damit lässt sich vermeiden, dass Benutzer auf Netzwerkpakete warten müssen, die um die halbe Welt reisen.
Für höhere Belastung skalieren
Wenn Sie lediglich für eine höhere Belastung skalieren müssen, ist es am einfachsten, leistungsfähigere Computer anzuschaffen (oft auch als vertikale Skalierung (scale up) bezeichnet). Viele CPUs, viele RAM-Chips und viele Festplatten lassen sich unter einem Betriebssystem gemeinsam betreiben, und schnelle Zwischenverbindungen erlauben jeder CPU, auf jeden Teil des Arbeitsspeichers oder der Festplatte zuzugreifen. Bei einer derartigen Shared-Memory-Architektur (Architektur mit gemeinsam genutztem Speicher) können alle Komponenten als ein einziger Computer betrachtet werden [1].1
Bei einem Shared-Memory-Ansatz besteht das Problem darin, dass die Kosten schneller als linear wachsen: Ein Computer mit doppelt so vielen CPUs, doppelt so viel RAM und doppelt so viel Festplattenkapazität wie ein anderer Computer kostet in der Regel deutlich mehr als das Doppelte. Und aufgrund von Engpässen ist ein Computer der doppelten Größe häufig gar nicht in der Lage, die doppelte Belastung zu bewältigen.
Eine Shared-Memory-Architektur kann begrenzte Fehlertoleranz bieten – High-End-Computer besitzen Hot-Swappable-Komponenten (die sich im laufenden Betrieb ersetzen lassen, ohne die Computer auszuschalten, wie zum Beispiel Festplatten, Speichermodule und sogar CPUs) – doch bleibt eine solche Architektur zweifellos auf einen einzelnen geografischen Standort beschränkt.
Ein anderer Ansatz ist die Shared-Disk-Architektur, die mehrere Computer mit unabhängigen CPUs und Arbeitsspeichern verwendet, die Daten aber auf einem Festplattenarray speichert, das die Computer gemeinsam nutzen und das über ein schnelles Netzwerk verbunden ist.2 Diese Architektur wird für bestimmte Data-Warehousing-Arbeitslasten eingesetzt, doch Konkurrenzsituationen und der Overhead von Sperrmechanismen schränken die Skalierbarkeit des Shared-Disk-Konzepts ein [2].
Shared-Nothing-Architekturen
Demgegenüber haben Shared-Nothing-Architekturen [3] (manchmal auch horizontale Skalierung oder Scale-out genannt) eine Menge an Popularität gewonnen. In diesem Ansatz wird jeder Computer oder jeder virtuelle Computer, der die Datenbanksoftware ausführt, als Knoten bezeichnet. Jeder Knoten läuft mit seinen CPUs, seinem RAM und seinen Festplatten unabhängig von anderen. Jegliche Koordinierung zwischen den Knoten geschieht auf der Softwareebene und läuft über ein konventionelles Netzwerk.
Da ein Shared-Nothing-System keine spezielle Hardware benötigt, können Sie beispielweise den Computer einsetzen, der das beste Preis-Leistungs-Verhältnis hat. Die Daten können Sie möglicherweise auf mehrere geografische Regionen verteilen, somit die Latenz für Benutzer verringern und gegebenenfalls den Totalausfall eines ganzen Rechenzentrums überstehen. Mit Cloud-Bereitstellungen von virtuellen Computern brauchen Sie nicht einmal in der Größenordnung von Google zu operieren: Selbst für kleinere Firmen ist jetzt eine auf mehrere Regionen verteilte Architektur praktikabel.
In diesem Teil des Buchs konzentrieren wir uns auf Shared-Nothing-Architekturen – nicht weil sie unbedingt die beste Wahl für jeden Einsatzfall sind, sondern vielmehr weil sie die meiste Sorgfalt von Ihnen, dem Anwendungsentwickler, verlangen. Wenn Ihre Daten über mehrere Knoten verteilt sind, müssen Sie sich der Einschränkungen und Kompromisse bewusst sein, die in einem derartigen verteilten System auftreten – die Datenbank ist nicht in der Lage, diese vor Ihnen zu verbergen.
Eine verteilte Shared-Nothing-Architektur hat zwar viele Vorteile, doch sie beinhaltet auch zusätzliche Komplexität für Anwendungen und schränkt manchmal die Ausdruckskraft der Datenmodelle ein, die Sie verwenden können. In manchen Fällen kann ein einfaches Programm, das in einem einzigen Thread läuft, deutlich besser abschneiden als ein Cluster mit über 100 CPU-Kernen [4]. Andererseits können Shared-Nothing-Systeme sehr leistungsfähig sein. Die nächsten Kapitel gehen ausführlich auf die Fragen ein, die im Zusammenhang mit verteilten Daten auftauchen.
Replikation vs. Partitionierung
Es gibt zwei gängige Methoden, Daten über mehrere Knoten zu verteilen:
Replikation
Eine Kopie derselben Daten auf mehreren verschiedenen Knoten behalten, möglicherweise an verschiedenen Standorten. Replikation bietet Redundanz: Wenn einige Knoten nicht mehr verfügbar sind, können die Daten dennoch von den übrigen Knoten bereitgestellt werden. Zudem kann Replikation helfen, die Performance zu verbessern. Replikation ist Thema von Kapitel 5.
Partitionierung
Eine große Datenbank in kleinere Teilmengen – sogenannte Partitionen – aufgliedern, sodass verschiedene Partitionen unterschiedlichen Knoten zugewiesen werden können (auch als Sharding – horizontale Fragmentierung – bezeichnet). Auf Partitionierung gehen wir in Kapitel 6 ein.
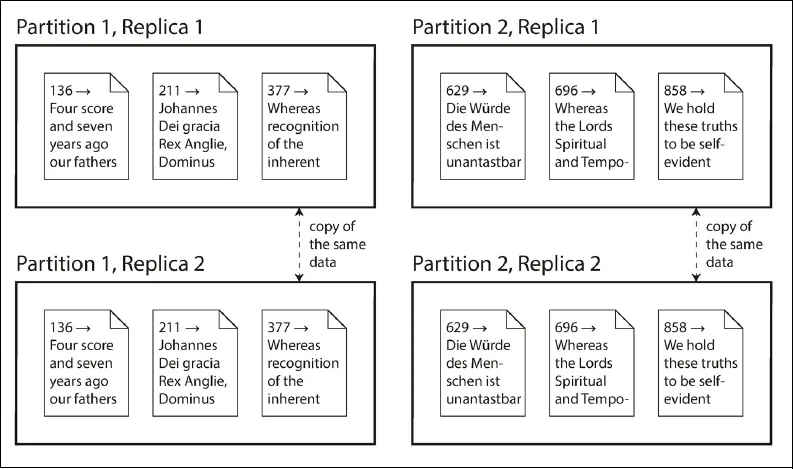
Diese Mechanismen sind zwar eigenständig, doch arbeiten sie oftmals Hand in Hand, wie Abbildung T-1 zeigt.
Abbildung T-1: Eine Datenbank, die in zwei Partitionen aufgeteilt ist und zwei Replikate pro Partition speichert
Mit dem Wissen über diese Konzepte können wir die schwierigen Kompromisse diskutieren, die Sie in einem verteilten System eingehen müssen. Mit Transaktionen befasst sich Kapitel 7, damit Sie verstehen, was in einem Datensystem alles schiefgehen kann und was sich dagegen unternehmen lässt. Diesen Teil des Buchs schließen wir in Kapitel 8 und Kapitel 9 mit einer Erörterung der prinzipiellen Beschränkungen von verteilten Systemen ab.
Später betrachten wir in Teil III dieses Buchs, wie Sie mehrere (möglicherweise verteilte) Datenspeicher in ein größeres System integrieren können, das die Anforderungen einer komplexen Anwendung erfüllt. Doch zunächst wollen wir über verteilte Daten sprechen.
Literaturverzeichnis
[1]Ulrich Drepper: What Every Programmer Should Know About Memory. akkadia.org, 21. November 2007.
[2]Ben Stopford: Shared Nothing vs. Shared Disk Architectures: An Independent View. benstopford.com, 24. November 2009.
[3]Michael Stonebraker: The Case for Shared Nothing. IEEE Database Engineering Bulletin, Bd. 9, Nr. 1, S. 4–9, März 1986.
[4]Frank McSherry, Michael Isard und Derek G. Murray: Scalability! But at What COST?. im 15. USENIX Workshop on Hot Topics in Operating Systems (HotOS), Mai 2015.
![]()
KAPITEL 5
Replikation
Der wichtigste Unterschied zwischen einer Sache, die schiefgehen kann, und einer Sache, die keinesfalls schiefgehen kann, besteht darin, dass, wenn etwas doch schiefgeht, das keinesfalls schiefgehen kann, es sich keinesfalls beheben lässt.
– Douglas Adams, Einmal Rupert und zurück (Mostly Harmless, 1992)
Replikation heißt, eine Kopie derselben Daten auf mehreren Computern, die über ein Netzwerk miteinander verbunden sind, zu speichern. Wie in der Einführung zu Teil II erörtert, gibt es mehrere Gründe, warum man Daten repliziert:
- Um Daten geografisch nahe bei den Benutzern zu halten (und somit die Latenz von Zugriffen zu verringern)
- Um dem System zu ermöglichen weiterzuarbeiten, selbst wenn einige seiner Komponenten ausgefallen sind (und somit die Verfügbarkeit zu erhöhen)
- Um die Anzahl der Computer, die Leseabfragen bedienen können, zu erhöhen (und s...