Hands-On Machine Learning with R
Brad Boehmke, Brandon M. Greenwell
- 456 Seiten
- English
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
Hands-On Machine Learning with R
Brad Boehmke, Brandon M. Greenwell
Über dieses Buch
Hands-on Machine Learning with R provides a practical and applied approach to learning and developing intuition into today's most popular machine learning methods. This book serves as a practitioner's guide to the machine learning process and is meant to help the reader learn to apply the machine learning stack within R, which includes using various R packages such as glmnet, h2o, ranger, xgboost, keras, and others to effectively model and gain insight from their data. The book favors a hands-on approach, providing an intuitive understanding of machine learning concepts through concrete examples and just a little bit of theory.
Throughout this book, the reader will be exposed to the entire machine learning process including feature engineering, resampling, hyperparameter tuning, model evaluation, and interpretation. The reader will be exposed to powerful algorithms such as regularized regression, random forests, gradient boosting machines, deep learning, generalized low rank models, and more! By favoring a hands-on approach and using real word data, the reader will gain an intuitive understanding of the architectures and engines that drive these algorithms and packages, understand when and how to tune the various hyperparameters, and be able to interpret model results. By the end of this book, the reader should have a firm grasp of R's machine learning stack and be able to implement a systematic approach for producing high quality modeling results.
Features:
· Offers a practical and applied introduction to the most popular machine learning methods.
· Topics covered include feature engineering, resampling, deep learning and more.
· Uses a hands-on approach and real world data.
Häufig gestellte Fragen
Information
Part II
Supervised Learning
4
Linear Regression
4.1 Prerequisites
ames_train data set created in Section 2.7.4.2 Simple linear regression
(4.1) |
(4.2) |
4.2.1 Estimation
(4.3) |
(4.4) |
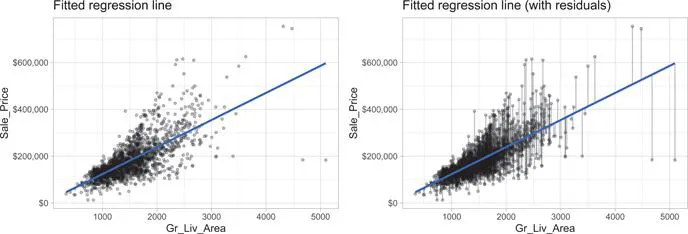
Gr_Liv_Area) and sale price (Sale_Price). To perform an OLS regression model in R we can use the lm() function:model1) is displayed in the left plot in Figure 4.1 where the points represent the values of Sale_Price in the training data. In the right plot of Figure 4.1, the vertical lines represent the individual errors, called residuals, associated with each observation. The OLS criterion in Equation (4.3) identifies the “best fitting” line that minimizes the sum of squares of these residuals.