
eBook - ePub
Stevens' Handbook of Experimental Psychology and Cognitive Neuroscience, Language and Thought
This is a test
Buch teilen
- English
- ePUB (handyfreundlich)
- Über iOS und Android verfügbar
eBook - ePub
Stevens' Handbook of Experimental Psychology and Cognitive Neuroscience, Language and Thought
Angaben zum Buch
Buchvorschau
Inhaltsverzeichnis
Quellenangaben
Über dieses Buch
III. Language & Thought: Sharon Thompson-Schill (Volume Editor)
(Topics covered include embodied cognition; discourse and dialogue; reading; creativity; speech production; concepts and categorization; culture and cognition; reasoning; sentence processing; bilingualism; speech perception; spatial cognition; word processing; semantic memory; moral reasoning.)
Häufig gestellte Fragen
Wie kann ich mein Abo kündigen?
Gehe einfach zum Kontobereich in den Einstellungen und klicke auf „Abo kündigen“ – ganz einfach. Nachdem du gekündigt hast, bleibt deine Mitgliedschaft für den verbleibenden Abozeitraum, den du bereits bezahlt hast, aktiv. Mehr Informationen hier.
(Wie) Kann ich Bücher herunterladen?
Derzeit stehen all unsere auf Mobilgeräte reagierenden ePub-Bücher zum Download über die App zur Verfügung. Die meisten unserer PDFs stehen ebenfalls zum Download bereit; wir arbeiten daran, auch die übrigen PDFs zum Download anzubieten, bei denen dies aktuell noch nicht möglich ist. Weitere Informationen hier.
Welcher Unterschied besteht bei den Preisen zwischen den Aboplänen?
Mit beiden Aboplänen erhältst du vollen Zugang zur Bibliothek und allen Funktionen von Perlego. Die einzigen Unterschiede bestehen im Preis und dem Abozeitraum: Mit dem Jahresabo sparst du auf 12 Monate gerechnet im Vergleich zum Monatsabo rund 30 %.
Was ist Perlego?
Wir sind ein Online-Abodienst für Lehrbücher, bei dem du für weniger als den Preis eines einzelnen Buches pro Monat Zugang zu einer ganzen Online-Bibliothek erhältst. Mit über 1 Million Büchern zu über 1.000 verschiedenen Themen haben wir bestimmt alles, was du brauchst! Weitere Informationen hier.
Unterstützt Perlego Text-zu-Sprache?
Achte auf das Symbol zum Vorlesen in deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Weitere Informationen hier.
Ist Stevens' Handbook of Experimental Psychology and Cognitive Neuroscience, Language and Thought als Online-PDF/ePub verfügbar?
Ja, du hast Zugang zu Stevens' Handbook of Experimental Psychology and Cognitive Neuroscience, Language and Thought von im PDF- und/oder ePub-Format sowie zu anderen beliebten Büchern aus Psychologie & Psychologie expérimentale. Aus unserem Katalog stehen dir über 1 Million Bücher zur Verfügung.
Information
CHAPTER 1
Speech Perception
FRANK EISNER AND JAMES M. MCQUEEN
INTRODUCTION
What Speech Is
Speech is the most acoustically complex type of sound that we regularly encounter in our environment. The complexity of the signal reflects the complexity of the movements that speakers perform with their tongues, lips, jaws, and other articulators in order to generate the sounds coming out of their vocal tract. Figure 1.1 shows two representations of the spoken sentence The sun melted the snow—an oscillogram at the top, showing variation in amplitude, and a spectrogram at the bottom, showing its spectral characteristics over time. The figure illustrates some of the richness of the information contained in the speech signal: There are modulations of amplitude, detailed spectral structures, noises, silences, bursts, and sweeps. Some of this structure is relevant in short temporal windows at the level of individual phonetic segments. For example, the vowel in the word sun is characterized by a certain spectral profile, in particular the location of peaks in the spectrum (called “formants,” the darker areas in the spectrogram). Other structures are relevant at the level of words or phrases. For example, the end of the utterance is characterized by a fall in amplitude and in pitch, which spans several segments. The acoustic cues that describe the identity of segments such as individual vowels and consonants are referred to as segmental information, whereas the cues that span longer stretches of the signal such as pitch and amplitude envelope and that signal prosodic structures such as syllables, feet, and intonational phrases are called suprasegmental.
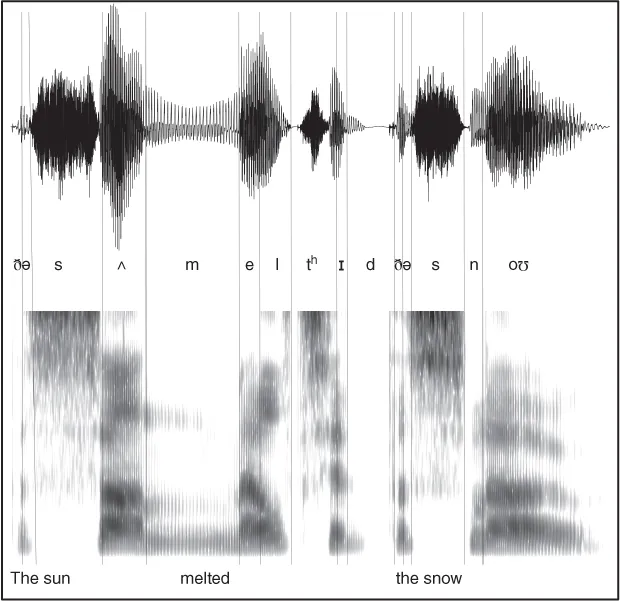
Figure 1.1 Oscillogram (top) and spectrogram (bottom) representations of the speech signal in the sentence “The sun melted the snow,” spoken by a male British English speaker. The vertical lines represent approximate phoneme boundaries with phoneme transcriptions in the International Phonetic Alphabet (IPA) system. The oscillogram shows variation in amplitude (vertical axis) over time (horizontal axis). The spectrogram shows variation in the frequency spectrum (vertical axis) over time (horizontal axis); higher energy in a given part of the spectrum is represented by darker shading.
Acoustic cues are transient and come in fast. The sentence in Figure 1.1 is spoken at a normal speech rate; it contains five syllables and is only 1.3 seconds long. The average duration of a syllable in the sentence is about 260 ms, meaning that information about syllable identity comes in on average at a rate of about 4 Hz, which is quite stable across languages (Giraud & Poeppel, 2012). In addition to the linguistic information that is densely packed in the speech signal, the signal also contains a great deal of additional information about the speaker, the so-called paralinguistic content of speech. If we were to listen to a recording of this sentence, we would be able to say with a fairly high degree of certainty that the speaker is a British middle-aged man with an upper-class accent, and we might also be able to guess that he is suffering from a cold and perhaps is slightly bored as he recorded the prescribed phrase. Paralinguistic information adds to the complexity of speech, and in some cases interacts with how linguistic information is interpreted by listeners (Mullennix & Pisoni, 1990).
What Speech Perception Entails
How, then, is this complex signal perceived? In our view, speech perception is not primarily about how listeners identify individual speech segments (vowels and consonants), though of course this is an important part of the process. Speech perception is also not primarily about how listeners identify suprasegmental units such as syllables and lexical stress patterns, though this is an often overlooked part of the process, too. Ultimately, speech perception is about how listeners use combined sources of segmental and suprasegmental information to recognize spoken words. This is because the listener's goal is to grasp what a speaker means, and the only way she or he can do so is through recognizing the individual meaning units in the speaker's utterance: its morphemes and words. Perceiving segments and prosodic structures is thus at the service of word recognition.
The nature of the speech signal poses a number of computational problems that the listener has to solve in order to be able to recognize spoken words (cf. Marr, 1982). First, listeners have to be able to recognize words in spite of considerable variability in the signal. The oscillogram and spectrogram in Figure 1.1 would look very different if the phrase had been spoken by a female adolescent speaking spontaneously in a casual conversation on a mobile phone in a noisy ski lift, and yet the same words would need to be recognized. Indeed, even if the same speaker recorded the same sentence a second time, it would be physically different (e.g., a different speaking rate, or a different fundamental frequency).
Due to coarticulation (the vocal tract changing both as a consequence of previous articulations and in preparation for upcoming articulations), the acoustic realization of any given segment can be strongly colored by its neighboring segments. There is thus no one-to-one mapping between the perception of a speech sound and its acoustics. This is one of the main factors that is still holding back automatic speech recognition systems (Benzeghiba et al., 2007). In fact, the perceptual system has to solve a many-to-many mapping problem, because not only do instances of the same speech sound have different acoustic properties, but the same acoustic pattern can result in perceiving different speech sounds, depending on the context in which the pattern occurs (Nusbaum & Magnuson, 1997; Repp & Liberman, 1987). The surrounding context of a set of acoustic cues thus has important implications on how the pattern should be interpreted by the listener.
There are also continuous speech processes through which sounds are added (a process called epenthesis), reduced, deleted, or altered, rendering a given word less like its canonical pronunciation. One example of such a process is given in Figure 1.1: The /n/ of sun is realized more like an [m], through a process called coronal place assimilation whereby the coronal /n/ approximates the labial place of articulation of the following word-initial [m].
Speech recognition needs to be robust in the face of all this variability. As we will argue, listeners appear to solve the variability problem in multiple ways, but in particular through phonological abstraction (i.e., categorizing the signal into prelexical segmental and suprasegmental units prior to lexical access) and through being flexible (i.e., through perceptual learning processes that adapt the mapping of the speech signal onto the mental lexicon in response to particular listening situations).
The listener must also solve the segmentation problem. As Figure 1.1 makes clear, the speech signal has nothing that is the equivalent of the white spaces between printed words as in a text such as this that reliably mark where words begin and end. In order to recognize speech, therefore, listeners have to segment the quasicontinuous input stream into discrete words. As with variability, there is no single solution to the segmentation problem: Listeners use multiple cues, and multiple algorithms.
A third problem derives from the fact that, across the world's languages, large lexica (on the order of perhaps 50,000 words) are built from small phonological inventories (on the order of 40 segments in a language such as English, and often much fewer than that; Ladefoged & Maddieson, 1996). Spoken words thus necessarily sound like other spoken words: They begin like other words, they end like other words, and they often have other words partially or wholly embedded within them. This means that, at any moment in the temporal unfolding of an utterance, the signal is likely to be partially or wholly consistent with many words. Once again, the listener appears to solve this “lexical embedding” problem using multiple algorithms.
We will argue that speech perception is based on several stages of processing at which a variety of perceptual operations help the listener solve these three major computational challenges—the variability problem, the segmentation problem, and the lexical embedding problem (see Box 1.1). These stages and operations have been studied over the past 70 years or so using behavioral techniques (e.g., psychophysical tasks such as identification and discrimination; psycholinguistic procedures such as lexical decision, cross-modal priming, and visual-world eye tracking); and neuroscientific techniques (especially measures using electroencephalography [EEG] and magnetoencephalography [MEG]). Neuroimaging techniques (primarily functional magnetic resonance imaging [fMRI]) and neuropsychological approaches (based on aphasic patients) have also made it possible to start to map these stages of processing onto brain regions. In the following section we will review data of all these different types. These data have made it possible to specify at least three core stages of processing involved in speech perception and the kinds of operations involved at each stage. The data also provide some suggestions about the neural instantiation of these stages.