This section will introduce you to the basics of data engineering. In this section, you will learn what data engineering is and how it relates to other similar fields, such as data science. You will cover the basics of working with files and databases in Python and using Apache NiFi. Once you are comfortable with moving data, you will be introduced to the skills required to clean and transform data. The section culminates with the building of a data pipeline to extract 311 data from SeeClickFix, transform it, and load it into another database. Lastly, you will learn the basics of building dashboards with Kibana to visualize the data you have loaded into your database.
This section comprises the following chapters:
- Chapter 1, What is Data Engineering?
- Chapter 2, Building Our Data Engineering Infrastructure
- Chapter 3, Reading and Writing Files
- Chapter 4, Working with Databases
- Chapter 5, Cleaning and Transforming Data
- Chapter 6, Building a 311 Data Pipeline
Chapter 1: What is Data Engineering?
Welcome to Data Engineering with Python. While data engineering is not a new field, it seems to have stepped out from the background recently and started to take center stage. This book will introduce you to the field of data engineering. You will learn about the tools and techniques employed by data engineers and you will learn how to combine them to build data pipelines. After completing this book, you will be able to connect to multiple data sources, extract the data, transform it, and load it into new locations. You will be able to build your own data engineering infrastructure, including clustering applications to increase their capacity to process data.
In this chapter, you will learn about the roles and responsibilities of data engineers and how data engineering works to support data science. You will be introduced to the tools used by data engineers, as well as the different areas of technology that you will need to be proficient in to become a data engineer.
In this chapter, we're going to cover the following main topics:
- What data engineers do
- Data engineering versus data science
- Data engineering tools
What data engineers do
Data engineering is part of the big data ecosystem and is closely linked to data science. Data engineers work in the background and do not get the same level of attention as data scientists, but they are critical to the process of data science. The roles and responsibilities of a data engineer vary depending on an organization's level of data maturity and staffing levels; however, there are some tasks, such as the extracting, loading, and transforming of data, that are foundational to the role of a data engineer.
At the lowest level, data engineering involves the movement of data from one system or format to another system or format. Using more common terms, data engineers query data from a source (extract), they perform some modifications to the data (transform), and then they put that data in a location where users can access it and know that it is production quality (load). The terms extract, transform, and load will be used a lot throughout this book and will often be abbreviated to ETL. This definition of data engineering is broad and simplistic. With the help of an example, let's dig deeper into what data engineers do.
An online retailer has a website where you can purchase widgets in a variety of colors. The website is backed by a relational database. Every transaction is stored in the database. How many blue widgets did the retailer sell in the last quarter?
To answer this question, you could run a SQL query on the database. This doesn't rise to the level of needing a data engineer. But as the site grows, running queries on the production database is no longer practical. Furthermore, there may be more than one database that records transactions. There may be a database at different geographical locations – for example, the retailers in North America may have a different database than the retailers in Asia, Africa, and Europe.
Now you have entered the realm of data engineering. To answer the preceding question, a data engineer would create connections to all of the transactional databases for each region, extract the data, and load it into a data warehouse. From there, you could now count the number of all the blue widgets sold.
Rather than finding the number of blue widgets sold, companies would prefer to find the answer to the following questions:
- How do we find out which locations sell the most widgets?
- How do we find out the peak times for selling widgets?
- How many users put widgets in their carts and remove them later?
- How do we find out the combinations of widgets that are sold together?
Answering these questions requires more than just extracting the data and loading it into a single system. There is a transformation required in between the extract and load. There is also the difference in times zones in different regions. For instance, the United States alone has four time zones. Because of this, you would need to transform time fields to a standard. You will also need a way to distinguish sales in each region. This could be accomplished by adding a location field to the data. Should this field be spatial – in coordinates or as well-known text – or will it just be text that could be transformed in a data engineering pipeline?
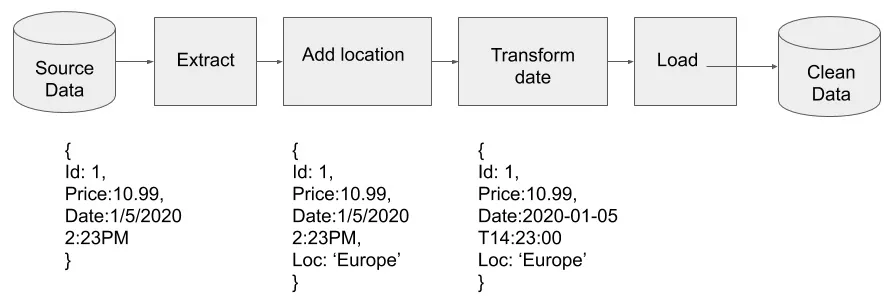
Here, the data engineer would need to extract the data from each database, then transform the data by adding an additional field for the location. To compare the time zones, the data engineer would need to be familiar with data standards. For the time, the International Organization for Standardization (ISO) has a standard – ISO 8601.
Let's now answer the questions in the preceding list one by one:
- Extract the data from each database.
- Add a field to tag the location for each transaction in the data
- Transform the date from local time to ISO 8601.
- Load the data into the data warehouse.
The combination of extracting, loading, and transforming data is accomplished by the creation of a data pipeline. The data comes into the pipeline raw, or dirty in the sense that there may be missing data or typos in the data, which is then cleaned as it flows through the pipe. After that, it comes out the other side into a data warehouse, where it can be queried. The following diagram shows the pipeline required to accomplish the task:
Figure 1.1 – A pipeline that adds a location and modifies the date
Knowing a little more about what data engineering is, and what data engineers do, you should start to get a sense of the responsibilities and skills that data engineers need to acquire. The following section will elaborate on these skills.
Required skills and knowledge to be a data engineer
In the preceding example, it should be clear that data engineers need to be familiar with many different technologies, and we haven't even mentioned the business processes or needs.
At the start of a data pipeline, data engineers need to know how to extract data from files in different formats or different types of databases. This means data engineers need to know several languages used to perform many different tasks, such as SQL and Python.
During the transformation phase of the data pipeline, data engineers need to be familiar with data modeling and structures. They will also need to understand the business and what knowledge and insight they are hoping to extract from the data because this will impact the design of the data models.
The loading of data into the data warehouse means there needs to be a data warehouse with a schema to hold the data. This is also usually the responsibility of the data engineer. Data engineers will need to know the basics of data warehouse design, as well as the types of databases used in their construction.
Lastly, the entire infrastructure that the data pipeline runs on could be the responsibility of the data engineer. They need to know how to manage Linux server...