
Performing Data Analysis Using IBM SPSS
Lawrence S. Meyers, Glenn C. Gamst, A. J. Guarino
- English
- ePUB (disponibile sull'app)
- Disponibile su iOS e Android
Performing Data Analysis Using IBM SPSS
Lawrence S. Meyers, Glenn C. Gamst, A. J. Guarino
Informazioni sul libro
Features easy-to-follow insight and clear guidelines to perform data analysis using IBM SPSS®
Performing Data Analysis Using IBM SPSS ® uniquely addresses the presented statistical procedures with an example problem, detailed analysis, and the related data sets. Data entry procedures, variable naming, and step-by-step instructions for all analyses are provided in addition to IBM SPSS point-and-click methods, including details on how to view and manipulate output.
Designed as a user's guide for students and other interested readers to perform statistical data analysis with IBM SPSS, this book addresses the needs, level of sophistication, and interest in introductory statistical methodology on the part of readers in social and behavioral science, business, health-related, and education programs. Each chapter of Performing Data Analysis Using IBM SPSS covers a particular statistical procedure and offers the following: an example problem or analysis goal, together with a data set; IBM SPSS analysis with step-by-step analysis setup and accompanying screen shots; and IBM SPSS output with screen shots and narrative on how to read or interpret the results of the analysis.
The book provides in-depth chapter coverage of:
- IBM SPSS statistical output
- Descriptive statistics procedures
- Score distribution assumption evaluations
- Bivariate correlation
- Regressing (predicting) quantitative and categorical variables
- Survival analysis
- t Test
- ANOVA and ANCOVA
- Multivariate group differences
- Multidimensional scaling
- Cluster analysis
- Nonparametric procedures for frequency data
Performing Data Analysis Using IBM SPSS is an excellent text for upper-undergraduate and graduate-level students in courses on social, behavioral, and health sciences as well as secondary education, research design, and statistics. Also an excellent reference, the book is ideal for professionals and researchers in the social, behavioral, and health sciences; applied statisticians; and practitioners working in industry.
Domande frequenti
Informazioni
Chapter 1: Introduction to IBM SPSS®
1.1 What is IBM SPSS?
1.2 Brief History
1.3 Types of IBM SPSS Files and File Name Extensions
- Data File.This is a spreadsheet containing the data that were collected from the participating entities or cases (e.g., students in a university class, patients in a clinic, retail stores in a national chain). In the data file, the variables are represented as columns; cases, as rows. This file type uses the extension .sav and its icon shows a grid.
- Output File.This file is produced when IBM SPSS has performed the requested statistical analysis (or other operations such as saving the data file). It contains the results of the procedure. This file type uses the extension .spv and its icon shows a window with a banner.
- Syntax File.This file contains the IBM SPSS computer code (syntax) that drives the analysis. This file type uses the extension .sps and its icon shows a window with horizontal lines.

- select Control Panel → Folder Options → View Tab;
- uncheck the checkbox for Hide extensions for known file types;
- click OK.
- Select Finder → Preferences → Advanced Tab.
- Check the checkbox for Show all filename extensions.
- Close the window.
Chapter 2: Entering Data in IBM SPSS®
2.1 The Starting Point
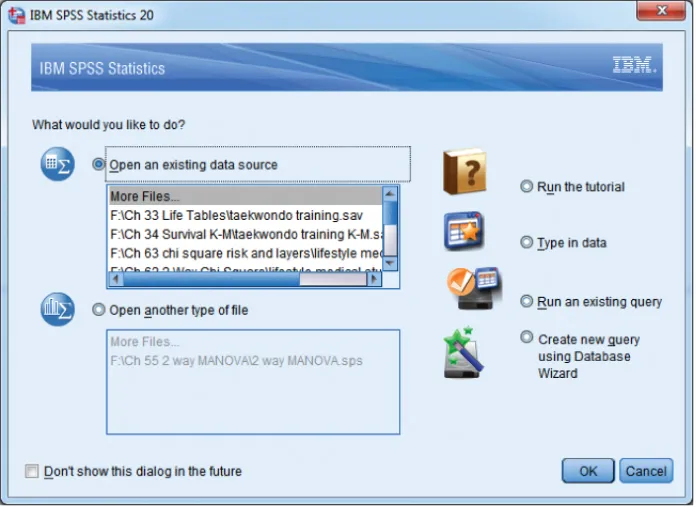
2.2 The Two Types of Displays

2.3 A Sample Data Set
- ID.This is an arbitrary identification code associated with each research participant (case). The ID de-identifies participants, thus protecting their anonymity and guaranteeing confidentiality. The ID also allows us to review the original data (which should also cont...