Translational bioinformatics (TBI) involves development of storage, analytics, and advanced computational methods to harvest knowledge from voluminous biomedical and genomic data into 4P healthcare (proactive, predictive, preventive, and participatory). Translational Bioinformatics Applications in Healthcare offers a detailed overview on concepts of TBI, biological and clinical databases, clinical informatics, and pertinent real-case applications. It further illustrates recent advancements, tools, techniques, and applications of TBI in healthcare, including Internet of Things (IoT) potential, toxin databases, medical image analysis and telemedicine applications, analytics of COVID-19 CT images, viroinformatics and viral diseases, and COVID-19–related research.
Covers recent technologies such as Blockchain, IoT, and Big data analytics in bioinformatics
Presents the role of translational bioinformatic methods in the field of viroinformatics, as well as in drug development and repurposing
Includes translational healthcare and NGS for clinical applications
Illustrates translational medicine systems and their applications in better healthcare
Explores medical image analysis with focus on CT images and novel coronavirus disease detection
Aimed at researchers and graduate students in computational biology, data mining and knowledge discovery, algorithms and complexity, and interdisciplinary fields of studies, including bioinformatics, health-informatics, biostatistics, biomedical engineering, and viroinformatics.
Khalid Raza is an Assistant Professor, the Department of Computer Science, Jamia Millia Islamia (Central University), New Delhi. His research interests include translational bioinformatics, computational intelligence methods and its applications in bioinformatics, viroinformatics, and health informatics.
Nilanjan Dey is an Associate Professor, the Department of Computer Science and Engineering, JIS University, Kolkata, India. His research interests include medical imaging, machine learning, computer-aided diagnosis, and data mining.
Häufig gestellte Fragen
Wie kann ich mein Abo kündigen?
Gehe einfach zum Kontobereich in den Einstellungen und klicke auf „Abo kündigen“ – ganz einfach. Nachdem du gekündigt hast, bleibt deine Mitgliedschaft für den verbleibenden Abozeitraum, den du bereits bezahlt hast, aktiv. Mehr Informationen hier.
(Wie) Kann ich Bücher herunterladen?
Derzeit stehen all unsere auf Mobilgeräte reagierenden ePub-Bücher zum Download über die App zur Verfügung. Die meisten unserer PDFs stehen ebenfalls zum Download bereit; wir arbeiten daran, auch die übrigen PDFs zum Download anzubieten, bei denen dies aktuell noch nicht möglich ist. Weitere Informationen hier.
Welcher Unterschied besteht bei den Preisen zwischen den Aboplänen?
Mit beiden Aboplänen erhältst du vollen Zugang zur Bibliothek und allen Funktionen von Perlego. Die einzigen Unterschiede bestehen im Preis und dem Abozeitraum: Mit dem Jahresabo sparst du auf 12 Monate gerechnet im Vergleich zum Monatsabo rund 30 %.
Was ist Perlego?
Wir sind ein Online-Abodienst für Lehrbücher, bei dem du für weniger als den Preis eines einzelnen Buches pro Monat Zugang zu einer ganzen Online-Bibliothek erhältst. Mit über 1 Million Büchern zu über 1.000 verschiedenen Themen haben wir bestimmt alles, was du brauchst! Weitere Informationen hier.
Unterstützt Perlego Text-zu-Sprache?
Achte auf das Symbol zum Vorlesen in deinem nächsten Buch, um zu sehen, ob du es dir auch anhören kannst. Bei diesem Tool wird dir Text laut vorgelesen, wobei der Text beim Vorlesen auch grafisch hervorgehoben wird. Du kannst das Vorlesen jederzeit anhalten, beschleunigen und verlangsamen. Weitere Informationen hier.
Ist Translational Bioinformatics Applications in Healthcare als Online-PDF/ePub verfügbar?
Ja, du hast Zugang zu Translational Bioinformatics Applications in Healthcare von Khalid Raza, Nilanjan Dey, Khalid Raza, Nilanjan Dey im PDF- und/oder ePub-Format sowie zu anderen beliebten Büchern aus Computer Science & Computer Engineering. Aus unserem Katalog stehen dir über 1 Million Bücher zur Verfügung.
Translational Healthcare, Next-Generation Sequence Analysis, and Drug Repurposing
1 Translational Healthcare System through Bioinformatics
Mrinal Kumar Sarma
The Energy and Resources Institute
Rina Ningthoujam
Central Agricultural University
Manasa Kumar Panda
CSIR-Institute of Minerals and Materials Technology
Punuri Jayasekhar Babu
Mizoram University
Ankit Srivastava
Banaras Hindu University
Mohinikanti Das
Odisha University of Agriculture and Technology
Yengkhom Disco Singh
Central Agricultural University
Contents
1.1 Introduction
1.2 Data and Biomedicine
1.3 Genomics and Bioinformatics
1.4 Pharmacogenomics
1.5 Mechanism of PG
1.5.1 Pharmacokinetics
1.5.2 Pharmacodynamics
1.6 PG in Drug Discovery
1.7 Drug Discovery and Development through Omics Technologies
1.7.1 Omics Technology
1.8 Availability of Omics Technology in Drug Discovery and Development
1.9 Role of Genomics in Drug Discovery and Development
1.10 Role of Transcriptomics in Drug Discovery and Development
1.11 Role of Proteomics in Drug Discovery and Development
1.12 Artificial Intelligence and Machine Learning of Drugs
1.13 Real time Biomedical and Healthcare Data
1.14 Biomedical and Healthcare Challenges
1.15 Opportunities to Improve Biomedical and Healthcare Sectors
1.16 Data models for Healthcare and Well Care Analytics
1.17 Conclusion and Future Prospects
Acknowledgments
References
1.1 Introduction
The field of translational bioinformatics is relatively young and fast, capturing the interest of academic circles as an important discipline of personalized healthcare and precision medicine. Advanced biological methods and technologies of analysis, along with interpretation, have opened up a new realm of exploratory endeavor. Microscopy as an invention and as a field of scientific discourse, commonly known as optics and imaging, allowed doctors and researchers to witness changes at the cellular level(Kalinin et al., 2016). Introduction of X-ray followed by magnetic resonance and other similar imaging technologies enabled monitoring of tissues and organs which was never possible before (Yu et al., 2018). Another recent addition to the above solution is “Big data” that translates the purpose of the application albeit the size. The term relates to the hypothesis-free approach of underlying experimental designs. Big data analysis is hypothesis generating rather than hypotheses driven (Golub, 2010). As we observe, innumerable data sets are generated when exploring a complicated disease worked on by researchers worldwide. These data points serve as feed for computational tools that process this information to get an apprehensible outcome which is used to target a specific medical condition. This approach of complementing complex experimental data volume with bioinformatics tools to arrive at a targeted solution for the health exigency is termed as translational healthcare (TH) system. This complex set of points also termed as “Big data” addresses the interconnectivity of different pathways at our biological levels, thereby probing the dysfunctional part of the body. The goal of precision medicine is to make use of this big data results and convert them into the information of pragmatic value for the practicing clinician.
The concept of TH is loosely based on the collection of big data provided by individual customers willingly and delivered directly to commercial giants like Facebook and Amazon, which helps them to tailor products according to their personal likes and dislikes. This approach has been thought over in medical and healthcare domain as a collection of information about a patient’s clinical history that can be put together and assessed using a computational tool, resulting in a possible personalized, specific solution addressing the medical conditions to improve outcomes (Manyika et al., 2011). Compared to the commercial industry, healthcare sector is more stringent as information available to researchers are not easy due to statutory protection of patient’s medical data. The direct inaccessibility to medical data by big data professionals, which is both philosophical and practical, is also a huge barrier in TH approach. Medical research in their field of research is still anchored in its classical approach of producing knowledge through studies and narrowing down the research question avoiding complexities in the real-world practice. Mostly, these kinds of studies are poorly equipped to correlate the interconnecting factors associated with the outcome of the treatment administered to the patient. The medical data generated in the hospitals on a daily basis can be a huge fuel for knowledge to be gained in treating an ailment. However, despite having so much information to develop an improved process for medical methods, big data analytics till date is limited only to the field of bioinformatics. The workers involved in this vibrant field encompass these details and develop user-friendly computational methods to deliver outcomes in healthcare that are understood by the practitioner. This new insight in the field of healthcare allows us to ideally treat disease and also in other case provides insight in preventing it in the first place.
1.2 Data and Biomedicine
With the advent of modern technology like next-generation sequencing (NGS) and advanced molecular biology tools for genomics and transcriptomics, a comprehensive look at the experimental outcomes is increasingly becoming multidimensional. This new facet of pursuit requires a large number of feed points to present a true signal corroborated by the statistical analysis (Kulynych and Greely, 2014). The last decade has seen an ever-increasing number of large-scale biorepositories targeted toward clinical and TH research all over the planet. These biorepositories contain both soft information and biospecimens collected from patients, enabling researchers to define and design treatment based on the understanding of the disease by reclassifying it on the basis of their underlying metabolic pathways with the help of the bioinformatics tools instead of the classical approach toward clinical treatment that has been practiced for centuries (Denny, 2014). These projects involve data collection using various modes of operation, starting from explicit information provided by patients expressing consent to their medical history being used to de-identified specimens whose clinical records are obtained from EHRs (electronic health records, also de-identified). This model of data collection using ethically informed consent is rigorous and expensive, whereas the model of using the information of de-identified specimens is more scalable and financially viable. However, with the increasing use of genomic data, nowadays, it is very complicated and, in a way, impossible to de-identify these information sources (Fleurence et al., 2013). This has led to the increase in ethical issues concerning patient privacy and data sharing. Most of the developed countries have come up with legislation to address these issues (Hudson and Collins, 2015). To augment toward the process of learning healthcare systems (LHS) model, the partnership between the patients and their doctors or researchers is sought by empowering the patient as a collaborator of the project, who also has a part in it. TH practice is a transition from best evidence accrued via randomized clinical trials to practice-based evidence, i.e., application of data generated from real world rather than from controlled clinical trials or experiments. In fact, currently used experimental design of randomized clinical trials is expensive and at times tends to be different from practical scenarios mainly due to non inclusion of common comorbidities associated with the addressed medical question (Luce et al., 2009). The data collected are statistical interpretations in nature where there is an effort to provide a generalized solution to a disease, not taking into account the complexities arising in the lower average groups of the cohort studied. These cohorts are meant to be a representative of the population in consideration but in reality are farfetched from actualities. In LHS or biomedicine, the operation is bidirectional where research is used to inform practice, and the data points collected during the disease treatment can be applied for hypothesis generation along with its validation through pragmatic experiments. Data derived from the outcomes of these experiments, accessed through computational “Big Data” methods, can possibly provide guidelines for future clinical care and practice.
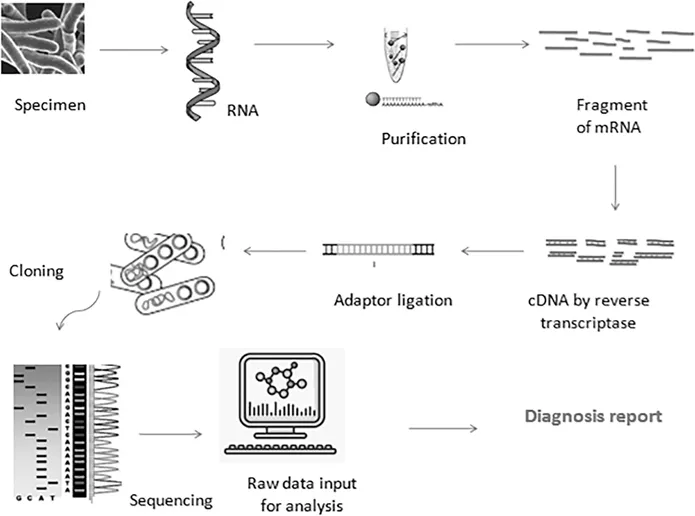
1.3 Genomics and Bioinformatics
The study of the genome of an organism, including whole DNA sequencing methods (Figure 1.1), gene mapping, and analyzing of intragenomic phenomena, is called genomics. It helps in pointing out the ideal gene or genotype among others. It has been globally used in healthcare and agriculture. In agriculture, it is used as a tool for programmed crop improvement. With the help of this process, we can generate new hybrid strains with good nutritional quality and more stress tolerance. The potential impact of this technology in the clinical application includes the discovery of gene and diagnosis of genetic abnormalities; identification and treatment of common diseases such as high blood pressure, diabetes, and cancer; targeted therapy; noninvasive prenatal testing; and identification of human infectious microorganism genome. It is further used in gene therapy and editing. Likewise, bioinformatics is also a tool which is capable of handling an enormous amount of data that result from programmed genomics and proteomics. It is used in other scientific fields and helps in analyzing transcription and functional structure determination (Zagursky and Russel, 2001). It has the ability of data acquisition, storage, processing, analysis, and integration. This tool functions in three main steps (Luscombe et al., 2001). First, it organizes the data in the simplest form and gives the existing information to the researchers. Second, the data are analyzed by developing a tool and resource. Third, the results are provided in a biological manner.